pytorch版本,cuda版本,系统cuda版本查询和对应关系


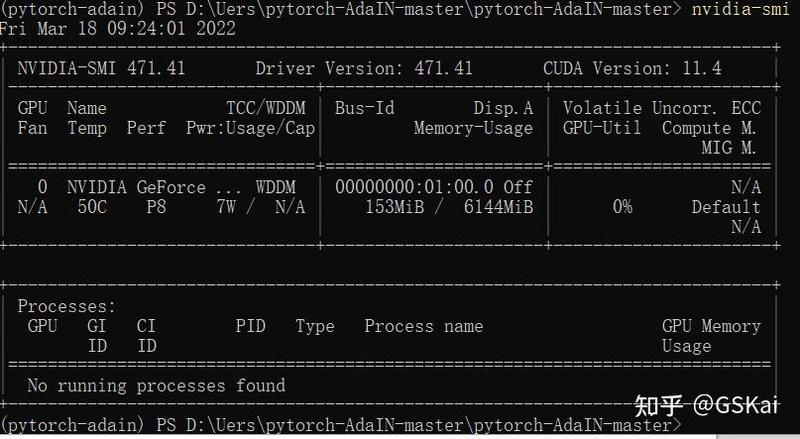
查询各版本,以及cuda的方法
显示true就是代表可以用。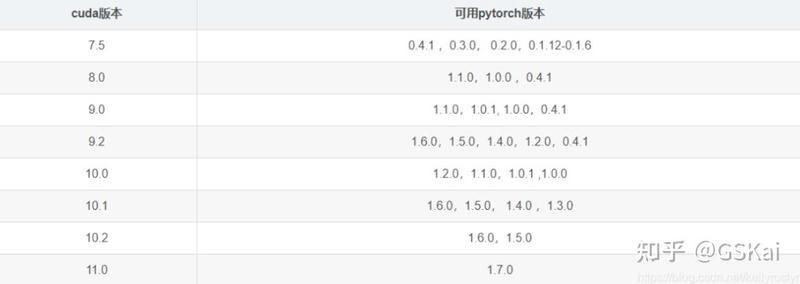
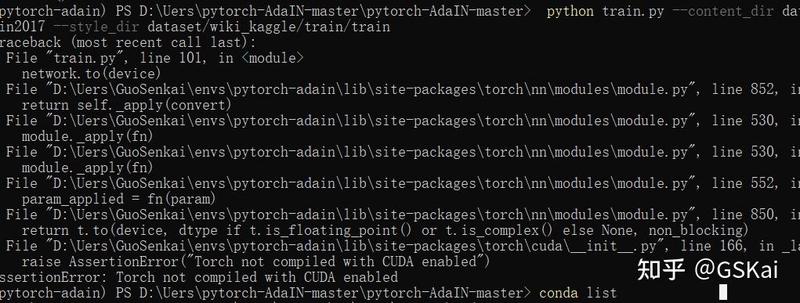
查看显卡版本:
ubuntu-drivers devices
nvidia-smi
查看CUDA版本命令:或或 
cuda与英伟达驱动匹配要求见CUDA Toolkit Documentation


AdaIN-TF-master训练报错:
T7ReaderException: unknown object type / typeidx: 11
解决方法force_8bytes_long=False ->True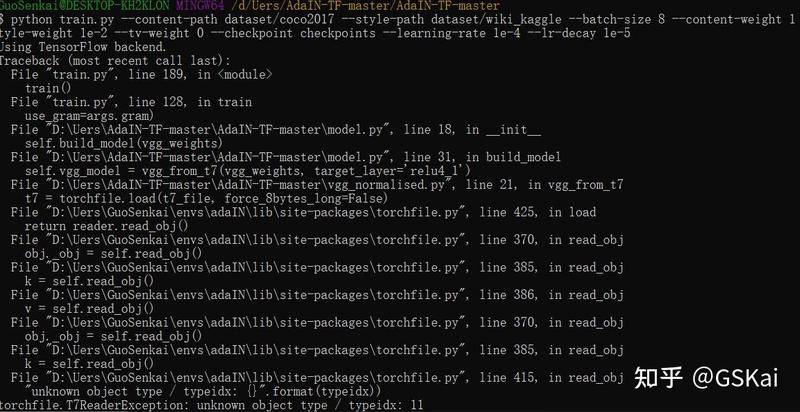

运行某代码时,报错:
NameError:name ‘xrange’ is not defined
原因:
在Python 3中,range()与xrange()合并为range( )。我的python版本为python3.5。
解决办法:
将xrange( )函数全部换为range( )。
我的环境是3.6,GitHub项目上readme是3.x,哈哈,真是哩个大普,编写torchfile.py的脑子抽了???


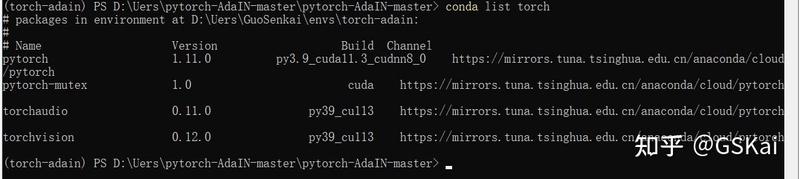
pytorch-adain训练报错:
1.RuntimeError: DataLoader worker (pid(s) 3620, 16160, 6256, 3744) exited unexpectedly
解决方法:令num_workers=0,在本人笔记本上哪怕取1,也还是会报错,只不过少一个数
1.1 OSError: [WinError 1455] 页面文件太小,无法完成操作
解决:把num_workers设置为0有用!在dataset.py文件中,可以搜索到num_workers变量,修改为0,解决这个报错问题。
num_workers是什么?num_workers即工作进程数,在dataloader加载数据时,num_workers可以看作搬砖的工人,将batch加载进RAM,工人越多加载速度越快。一般这个数量设置值是自己电脑/服务器的CPU核心数。如果num_worker设为0,意味着每一轮迭代时,dataloader不再有自主加载数据到RAM这一步骤(因为没有worker了),而是在RAM中找batch,找不到时再加载相应的batch。缺点:导致训练速度变慢

2.TypeError: ‘NoneType' object is notiterable解决办法
解决不了,重装cuda,注意要装latest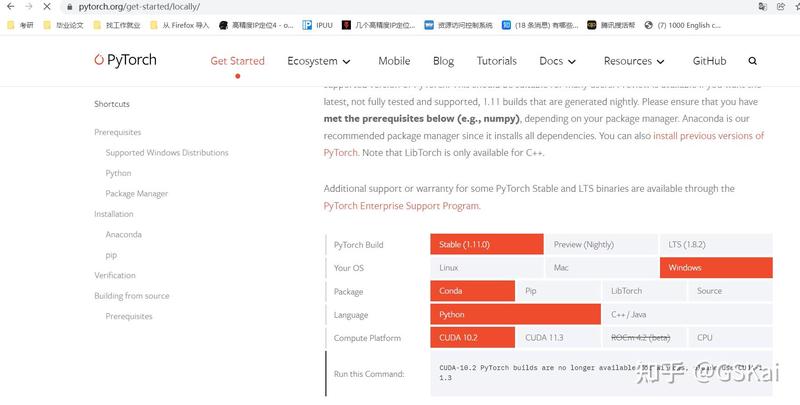
3.Python报错:PermissionError: [Errno 13] Permission denied
解决办法:什么被占用,用管理员身份打开cmd,文件改为只读隐藏均不好使,新建一个数据文件问题解决
可能原因
conda清理没用的安装包
4.cuda与
