Webstorm 2023.2 最新图文安装教程(附激活码,亲测有效)

添加图片注释,不超过 140 字(可选)
前言
Webstorm 目前已经更新到最新的 2023.2 版本了,好在我又更新了新的补丁,针对最新版本,这边笔者亲测可行,仅以下文记录本人 Webstorm 2023.2 版本的激活到 2099 年的全过程,步骤非常详细,跟着图文来就行 ~
第一步: 下载最新的 Webstorm 2023.2 版本安装包
我们先从 Webstorm 官网下载 Webstorm 2023.2 版本的安装包,下载链接如下:
https://www.jetbrains.com/webstorm/download

添加图片注释,不超过 140 字(可选)
点击下载,静心等待其下载完毕即可。
第二步: 开始安装 Webstorm 2023.2 版本
2.安装目录默认为 C:Program FilesJetBrainsWebStorm 2023.2, 这里笔者选择的是默认路径:

添加图片注释,不超过 140 字(可选)
3.勾选创建桌面快捷方式,这边方便后续打开 Webstorm:

添加图片注释,不超过 140 字(可选)
4.点击 Install :

添加图片注释,不超过 140 字(可选)
5.安装完成后,勾选 Run IntelliJ Webstorm,点击 Finish 运行软件:

添加图片注释,不超过 140 字(可选)
Webstorm 运行成功后,会弹出下面的对话框,提示我们需要先登录 JetBrains 账户才能使用:

添加图片注释,不超过 140 字(可选)
这里我们先不管,先点击 Exit 退出,准备开始激活。
第三步:清空 Webstorm 以前使用过的激活方式【非常重要】
开始激活前,如果你之前激活过老版本的 Webstorm,可能做过以下几种操作,则需要恢复原样,如果没有,直接跳过看下面步骤即可。
1、动过 hosts 文件,添加的配置需要删除
手动为 Webstorm 修改过 hosts 文件,那么添加的配置,记得要删除;
2、引用过其他的补丁,或者执行过安装脚本
1. 引用过的补丁也要移除掉等, 不然可能会与本文提供的补丁有冲突,出现各种奇奇怪怪的问题。
2. 之前版本中, 我提供过通过安装脚本来引用补丁,如果你有使用过,脚本会添加相关环境变量,这些环境变量也需要清空,查看脚本文件夹,执行 uninstall-* 脚本即可。

添加图片注释,不超过 140 字(可选)
第四步:补丁下载
补丁下载成功后,记得先解压, 解压后的目录如下, 本文后面所需补丁都在下面标注的这个文件夹中:

添加图片注释,不超过 140 字(可选)
点击【方式 3】文件夹 , 进入到文件夹 /jetbra,目录如下:

添加图片注释,不超过 140 字(可选)
第五步:开始激活
Windows 系统
将上面图示的补丁的所属文件夹 /jetbra 复制电脑某个位置,笔者这里放置到了 D:/ 盘根目录下:
注意: 补丁所属文件夹需单独存放,且放置的路径不要有中文与空格,以免 IDEA 读取补丁错误。
点击进入 /jetbra 补丁目录,再点击进入 /scripts 文件夹,双击执行 install-current-user.vbs 脚本:

添加图片注释,不超过 140 字(可选)
注意:如果执行脚本被安全软件提示有风险拦截,允许执行即可。

添加图片注释,不超过 140 字(可选)
会提示安装补丁需要等待数秒。点击【确定】按钮后,过程大概 10 - 30 秒,如看到弹框提示 Done 时,表示激活成功:

添加图片注释,不超过 140 字(可选)
Mac / Linux 系统
Mac / Linux 系统与上面 Windows 系统一样,需将补丁所属文件 /jetbra 复制到某个路径,且路径不能包含空格与中文。
之后,打开终端,进入到 /jetbra/scripts 文件夹, 执行 install.sh 脚本, 命令如下:
sudobashinstall.sh
看到提示 Done , 表示激活成功。

添加图片注释,不超过 140 字(可选)
部分小伙伴 Mac/Linux 系统执行脚本遇到如下错误:

添加图片注释,不超过 140 字(可选)
解决方法:
可先执行如下命令,再执行脚本:
export LC_COLLATE='C'export LC_CTYPE='C'

添加图片注释,不超过 140 字(可选)
执行脚本,都干了些啥?Windows 用户执行脚本后,脚本会自动在环境变量 -> 用户变量下添加了 WEBSTORM_VM_OPTIONS 变量,变量值为 /jetbra 文件夹下的参数文件绝对路径
然后自动在 /jetbra/vmoptions 目录下的 webstorm.vmoptions 文件中引用了补丁 :

添加图片注释,不超过 140 字(可选)
Mac / Linux 用户执行脚本后,脚本会自动在当期用户环境变量文件中添加了相关参数文件,Mac / Linux 需重启系统,以确保环境变量生效。
小伙伴们也可自行检查一下,如果没有自动添加这些参数,说明脚本执行没有成功。
重启 Webstorm配置完成后保存,一定要重启 Webstorm !!!配置完成后保存,一定要重启 Webstorm !!!第六步:重新打开 Webstorm, 填入指定激活码完成激活
重新打开 Webstorm,填入下面的激活码,点击激活即可。
8R927DG13X-eyJsaWNlbnNlSWQiOiI4UjkyN0RHMTNYIiwibGljZW5zZWVOYW1lIjoic2lnbnVwIHNjb290ZXIiLCJhc3NpZ25lZU5hbWUiOiIiLCJhc3NpZ25lZUVtYWlsIjoiIiwibGljZW5zZVJlc3RyaWN0aW9uIjoiIiwiY2hlY2tDb25jdXJyZW50VXNlIjpmYWxzZSwicHJvZHVjdHMiOlt7ImNvZGUiOiJQU0kiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IldTIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUFdTIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQQ1dNUCIsImZhbGxiYWNrRGF0ZSI6IjIwMjUtMDgtMDEiLCJwYWlkVXBUbyI6IjIwMjUtMDgtMDEiLCJleHRlbmRlZCI6dHJ1ZX1dLCJtZXRhZGF0YSI6IjAxMjAyMjA5MDJQU0FOMDAwMDA1IiwiaGFzaCI6IlRSSUFMOjIwMTEzMjMwMjYiLCJncmFjZVBlcmlvZERheXMiOjcsImF1dG9Qcm9sb25nYXRlZCI6ZmFsc2UsImlzQXV0b1Byb2xvbmdhdGVkIjpmYWxzZX0=-Jev3eIT6wPDh59rzeBG67oHD8GcYHifz9+OkIePP3Qo49dGX1DqLTGJgOxSClHrshRzjOktdBYwkwpeTrDMwgeGu+cy0OhzvtQMeh7R3HrEQkhGbNBjfpbW6nq6Mhv8k6Duoiw3XiU434V5iM6DgRN3Yzo8VKxU7Kb4u/SQnPTd+PR64hYJjblVXUzGHZUX4w8RBej3T0EREccs36bfnnPC2X91K/qbvr9C0uY/feHAMpuekMks0v4qApbInpw5O+elLE3l8txlNWhWSC8m/O/S7iydf27hV5mgePM5422Rpvm4dmA2DIQcq7xxdt4X67DmVGMC2yIFiH4hfkqySWg==-MIIETDCCAjSgAwIBAgIBDTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTIwMTAxOTA5MDU1M1oXDTIyMTAyMTA5MDU1M1owHzEdMBsGA1UEAwwUcHJvZDJ5LWZyb20tMjAyMDEwMTkwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCUlaUFc1wf+CfY9wzFWEL2euKQ5nswqb57V8QZG7d7RoR6rwYUIXseTOAFq210oMEe++LCjzKDuqwDfsyhgDNTgZBPAaC4vUU2oy+XR+Fq8nBixWIsH668HeOnRK6RRhsr0rJzRB95aZ3EAPzBuQ2qPaNGm17pAX0Rd6MPRgjp75IWwI9eA6aMEdPQEVN7uyOtM5zSsjoj79Lbu1fjShOnQZuJcsV8tqnayeFkNzv2LTOlofU/Tbx502Ro073gGjoeRzNvrynAP03pL486P3KCAyiNPhDs2z8/COMrxRlZW5mfzo0xsK0dQGNH3UoG/9RVwHG4eS8LFpMTR9oetHZBAgMBAAGjgZkwgZYwCQYDVR0TBAIwADAdBgNVHQ4EFgQUJNoRIpb1hUHAk0foMSNM9MCEAv8wSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TATBgNVHSUEDDAKBggrBgEFBQcDATALBgNVHQ8EBAMCBaAwDQYJKoZIhvcNAQELBQADggIBABqRoNGxAQct9dQUFK8xqhiZaYPd30TlmCmSAaGJ0eBpvkVeqA2jGYhAQRqFiAlFC63JKvWvRZO1iRuWCEfUMkdqQ9VQPXziE/BlsOIgrL6RlJfuFcEZ8TK3syIfIGQZNCxYhLLUuet2HE6LJYPQ5c0jH4kDooRpcVZ4rBxNwddpctUO2te9UU5/FjhioZQsPvd92qOTsV+8Cyl2fvNhNKD1Uu9ff5AkVIQn4JU23ozdB/R5oUlebwaTE6WZNBs+TA/qPj+5/we9NH71WRB0hqUoLI2AKKyiPw++FtN4Su1vsdDlrAzDj9ILjpjJKA1ImuVcG329/WTYIKysZ1CWK3zATg9BeCUPAV1pQy8ToXOq+RSYen6winZ2OO93eyHv2Iw5kbn1dqfBw1BuTE29V2FJKicJSu8iEOpfoafwJISXmz1wnnWL3V/0NxTulfWsXugOoLfv0ZIBP1xH9kmf22jjQ2JiHhQZP7ZDsreRrOeIQ/c4yR8IQvMLfC0WKQqrHu5ZzXTH4NO3CwGWSlTY74kE91zXB5mwWAx1jig+UXYc2w4RkVhy0//lOmVya/PEepuuTTI4+UJwC7qbVlh5zfhj8oTNUXgN0AOc+Q0/WFPl1aw5VV/VrO8FCoB15lFVlpKaQ1Yh+DVU8ke+rt9Th0BCHXe0uZOEmH0nOnH/0onD
复制激活码后填入,点击 Activate 按钮完成激活:

添加图片注释,不超过 140 字(可选)
PS: 有部分小伙伴反应,重启 Webstorm 填入激活码依然无法激活,重启系统才行,如果有小伙伴遇到这种情况,不妨试试看 ~
点击激活后,就可以看到激活成功辣,又可以开心的 coding 了 ~:

添加图片注释,不超过 140 字(可选)
激活成功后,不要升级 Webstorm 版本
官方反制手段越来越严厉,这个版本能激活,新版本大概率补丁就被搬了。所以,如果打开 Webstorm 后,右下角若出现提示升级新版本,请不要升级版本。能用就行,它不香嘛!
激活成功后,补丁文件夹能不能删掉或者移动?
前文中的环境变量,小伙伴也看到了,对应了你放置补丁位置的路径,删除掉或者移动,再打开 Webstorm 就找不到对应文件了,激活也就失效了。放着吃灰就行,别动它。
A. Yes-Yes?
B. Lost Permutation
枚举序列的最大值
C. Thermostat
情况数量不多
[a=b\
a ightarrow b\
a ightarrow l ightarrow b\
a ightarrow r ightarrow b\
a ightarrow l ightarrow r ightarrow b\
a ightarrow r ightarrow l ightarrow b
]
逐个判断就好了
D. Make It Round
对于一个数字(x=2^a imes5^b imes c),那么末尾0的数量就是(min(a,b))
所以我们枚举乘数中2 和5的次方数就好了
E. The Humanoid
使用药剂的顺序只有三种,三种顺序每种都贪心的取一下,最后取最优解即可。
F. All Possible Digits
其实我们只能对末尾进行操作,且只能加一。
末尾数字是(pn),我们只用考虑两种情况
([0,pn])中所有的数字都已经出现过了,我们只需要找到((pn,p))中没出现过的最大值,然后加过去即可。
([0,pn])中所有的数字没有都出现过,首先一直加直到进位,此时((pn,p))中所有的都已经出现过,当前末尾是0,找到((0,pn))中没有出现过的最大值,加过去就好
G. Restore the Permutation
对于相邻的两个数,取最大值,所以一定是把当前所有数字放在偶数位上,然后在奇数位置放一个较小的数字。
首先我们判断时候有解。
我们把所有没有放置的数字存起来,然后正序操作,每次放置一个尽可能大的,如果不能全部放完,则无解。
然后找字典序最小的解,反序操作一遍即可。
然后其实发现,我们直接反序操作就行,放不完直接就可以判断出无解。
HTTPS 协议是基于 TCP 协议的,因而要先建立 TCP 的连接。在这个例子中,TCP 的连接是在手机上的 App 和负载均衡器 SLB 之间的。
尽管中间要经过很多的路由器和交换机,但是 TCP 的连接是端到端的。TCP 这一层和更上层的 HTTPS 无法看到中间的包的过程。尽管建立连接的时候,所有的包都逃不过在这些路由器和交换机之间的转发,转发的细节我们放到那个下单请求的发送过程中详细解读,这里只看端到端的行为。
对于 TCP 连接来讲,需要通过三次握手建立连接,为了维护这个连接,双方都需要在 TCP 层维护一个连接的状态机。
一开始,客户端和服务端都处于 CLOSED 状态。服务端先是主动监听某个端口,处于 LISTEN 状态。然后客户端主动发起连接 SYN,之后处于 SYN-SENT 状态。服务端收到发起的连接,返回 SYN,并且 ACK 客户端的 SYN,之后处于 SYN-RCVD 状态。
客户端收到服务端发送的 SYN 和 ACK 之后,发送 ACK 的 ACK,之后处于 ESTABLISHED 状态。这是因为,它一发一收成功了。服务端收到 ACK 的 ACK 之后,也会处于 ESTABLISHED 状态,因为它的一发一收也成功了。
当 TCP 层的连接建立完毕之后,接下来轮到 HTTPS 层建立连接了,在 HTTPS 的交换过程中,TCP 层始终处于 ESTABLISHED。
对于 HTTPS,客户端会发送 Client Hello 消息到服务器,用明文传输 TLS 版本信息、加密套件候选列表、压缩算法候选列表等信息。另外,还会有一个随机数,在协商对称密钥的时候使用。
然后,服务器会返回 Server Hello 消息,告诉客户端,服务器选择使用的协议版本、加密套件、压缩算法等。这也有一个随机数,用于后续的密钥协商。
然后,服务器会给你一个服务器端的证书,然后说:“Server Hello Done,我这里就这些信息了。”
客户端当然不相信这个证书,于是从自己信任的 CA 仓库中,拿 CA 的证书里面的公钥去解密电商网站的证书。如果能够成功,则说明电商网站是可信的。这个过程中,你可能会不断往上追溯 CA、CA 的 CA、CA 的 CA 的 CA,反正直到一个授信的 CA,就可以了。
证书验证完毕之后,觉得这个服务端是可信的,于是客户端计算产生随机数字 Pre-master,发送 Client Key Exchange,用证书中的公钥加密,再发送给服务器,服务器可以通过私钥解密出来。
接下来,无论是客户端还是服务器,都有了三个随机数,分别是:自己的、对端的,以及刚生成的 Pre-Master 随机数。通过这三个随机数,可以在客户端和服务器产生相同的对称密钥。
有了对称密钥,客户端就可以说:“Change Cipher Spec,咱们以后都采用协商的通信密钥和加密算法进行加密通信了。”
然后客户端发送一个 Encrypted Handshake Message,将已经商定好的参数等,采用协商密钥进行加密,发送给服务器用于数据与握手验证。
同样,服务器也可以发送 Change Cipher Spec,说:“没问题,咱们以后都采用协商的通信密钥和加密算法进行加密通信了”,并且也发送 Encrypted Handshake Message 的消息试试。
当双方握手结束之后,就可以通过对称密钥进行加密传输了。
此文章为10月Day09学习笔记,内容来源于极客时间《趣谈网络协议》,推荐该课程。
//转换器,将列的字段类型转换为可以排序的类型:String,int,float
function convert(sValue, sDataType)
{
switch(sDataType)
{
case "int":
return parseInt(sValue);
case "float":
return parseFloat(sValue);
case "date":
return new Date(Date.parse(sValue));
default:
return sValue.toString();
}
}
// 汉字排序方法
function chrComp(a,b)
{
return a.localeCompare(b);
}
//排序函数产生器
function generateCompareTRs(iCol, sDataType,isinput,sDec)
{
return function compareTRs(oTR1, oTR2)
{
if(isinput == 1)
{
var vValue1 = convert(oTR1.getElementsByTagName("input")[iCol].value);
var vValue2 = convert(oTR2.getElementsByTagName("input")[iCol].value);
}
else
{
var vValue1 = convert(oTR1.cells[iCol].firstChild.nodeValue, sDataType);
var vValue2 = convert(oTR2.cells[iCol].firstChild.nodeValue, sDataType);
}
if(sDec=='desc')
{
if(sDataType=='int')
{
return vValue1 == vValue2 ? 0 :(vValue1 - vValue2 <0 ? 1 : -1);
}
else if(sDataType =='cn')
{
if(chrComp(vValue1,vValue2)>0)
{
return -1;
}
else if(chrComp(vValue1,vValue2)<0)
{
return 1;
}
else
{
return 0;
}
}
else
{
if (vValue1 > vValue2) {
return -1;
} else if (vValue1 < vValue2) {
return 1;
} else {
return 0;
}
}
}
else if(sDec=='asc')
{
if(sDataType=='int')
{
return vValue1 == vValue2 ? 0 :(vValue1 - vValue2 >0 ? 1 : -1);
}
else if(sDataType =='cn')
{
return chrComp(vValue1,vValue2);
}
else
{
if (vValue1 > vValue2) {
return 1;
} else if (vValue1 < vValue2) {
return -1;
} else {
return 0;
}
}
}
};
}
//重置单元格的classname
function ChangeClsName(tr,num)
{
num = num%2?1:2;
num.toString();
for ( var i = 0 ; i < tr.childNodes.length; i ++ )
{
tr.childNodes[i].className = "row" + num
}
}
/*排序方法(主函数)登录后复制
GNU计划,有譯為「革奴计划」,是由理查德·斯托曼在1983年9月27日公开发起的。它的目標是创建一套完全自由的操作系统。理查德·斯托曼最早是在net.unix-wizards新闻组上公布该消息,并附带一份《GNU宣言》等解释为何发起该计划的文章,其中一个理由就是要“重现当年软件界合作互助的团结精神”。
GNU是“GNU's Not Unix”的递归缩写,為避免与gnu(非洲牛羚,发音与「new」相同)这个单词混淆,斯托曼宣布GNU应当发音为「Guh-NOO」(/ˈgnuː/ (幫助·關於)),与「canoe」发音相似。
UNIX是一种广泛使用的商业操作系统的名称。由于GNU将要实现UNIX系统的接口标准,因此GNU计划可以分别开发不同的操作系统。GNU计划采用了部分当时已经可自由使用的软件,例如TeX排版系统和X Window视窗系统等。不过GNU计划也开发了大批其他的自由软件,这些软件也被移植到其他操作系统平台上,例如Microsoft Windows、BSD家族、Solaris及MacOS。
为保证GNU软件可以自由地“使用、复制、修改和发布”,所有GNU软件都包含一份在禁止其他人添加任何限制的情况下,授权所有权利给任何人的协议条款,GNU通用公共许可证(GNU General Public License,GPL)。这个就是被称为『公共版權』的概念。GNU也针对不同场合,提供GNU宽通用公共许可证(与GNU自由文档许可证这两种协议条款。
1985年,理查德·斯托曼又创立了自由软件基金会(Free Software Foundation)来为GNU计划提供技术、法律以及财政支持。尽管GNU计划大部分时候是由个人自愿无偿贡献,但FSF有时还是会聘请程序员帮助编写。当GNU计划开始逐渐获得成功时,一些商业公司开始介入开发和技术支持。当中最著名的就是之后被Red Hat兼并的Cygnus Solutions。
到了1990年,GNU计划已经开发出的软件包括了一个功能强大的文字编辑器Emacs、C语言编译器GCC以及大部分UNIX系统的程序库和工具。唯一依然没有完成的重要组件,就是操作系统的内核(称为HURD)。
1991年,林納斯·托瓦茲编写出了与UNIX兼容的Linux操作系统内核並在GPL条款下发布。Linux之后在网上广泛流传,许多程序员参与了开发与修改。
1992年,Linux与其他GNU软件结合,完全自由的操作系统正式诞生。该操作系统往往被称为“GNU/Linux”或简称Linux。(尽管如此,GNU计划自己的内核Hurd依然在开发中,目前已经发布Beta版本。)
许多UNIX系统上也安装了GNU软件,因为GNU软件的质量比之前UNIX的软件还要好。GNU工具还被广泛地移植到Windows和Mac OS上。
GNU工程十几年以来已经成为一个对软件开发主要的影响力量,创造了无数的重要的工具,例如:强健的编译器,有力的文本编辑器,甚至一个全功能的操作系统。这个工程是从1984年麻省理工学院的程序员理查德·斯托曼的想法得来的,他想要建立一个自由的、和UNIX类似的操作环境。从那时开始,许多程序员聚集起来开始开发一个自由的、高质量、易理解的软件。
<?php
namespace EasyDI;
use EasyDIExceptionUnknownIdentifierException;
use EasyDIExceptionInvalidArgumentException;
use EasyDIExceptionInstantiateException;
use PsrContainerContainerExceptionInterface;
use PsrContainerContainerInterface;use PsrContainerNotFoundExceptionInterface;
class Container implements ContainerInterface{
/**
* 保存 参数, 已实例化的对象
* @var array
*/
private $instance = []; private $shared = []; private $raw = []; private $params = []; /**
* 保存 定义的 工厂等
* @var array
*/
private $binding = []; public function __construct()
{
$this->raw(ContainerInterface::class, $this);
$this->raw(self::class, $this);
}
/**
* Finds an entry of the container by its identifier and returns it.
*
* @param string $id Identifier of the entry to look for.
*
* @throws NotFoundExceptionInterface No entry was found for **this** identifier.
* @throws ContainerExceptionInterface Error while retrieving the entry.
*
* @return mixed Entry.
*/ public function get($id, $parameters = [], $shared=false)
{
if (!$this->has($id)) { throw new UnknownIdentifierException($id);
}
if (array_key_exists($id, $this->raw)) {
return $this->raw[$id];
}
if (array_key_exists($id, $this->instance)) {
return $this->instance[$id];
}
$define = array_key_exists($id, $this->binding) ? $this->binding[$id] : $id;
if ($define instanceof Closure) {
$instance = $this->call($define, $parameters);
} else {
// string
$class = $define;
$params = (empty($this->params[$id]) ? [] : $this->params[$id]) + $parameters;
// Case: "\xxx\xxx"=>"abc"
if ($id !== $class && $this->has($class)) {
$instance = $this->get($class, $params);
} else {
$dependencies = $this->getClassDependencies($class, $params);
if (is_null($dependencies) || empty($dependencies)) {
$instance = $this->getReflectionClass($class)->newInstanceWithoutConstructor();
} else {
$instance = $this->getReflectionClass($class)->newInstanceArgs($dependencies);
}
}
} if ($shared || (isset($this->shared[$id]) && $this->shared[$id])) {
$this->instance[$id] = $instance;
} return $instance;
} /**
* @param callback $function
* @param array $parameters
* @return mixed
* @throws InvalidArgumentException 传入错误的参数
* @throws InstantiateException
*/
public function call($function, $parameters=[], $shared=false)
{
//参考 http://php.net/manual/zh/function.call-user-func-array.php#121292 实现解析$function
$class = null; $method = null; $object = null; // Case1: function() {}
if ($function instanceof Closure) { $method = $function;
} elseif (is_array($function) && count($function)==2) { // Case2: [$object, $methodName]
if (is_object($function[0])) { $object = $function[0]; $class = get_class($object);
} elseif (is_string($function[0])) { // Case3: [$className, $staticMethodName]
$class = $function[0];
} if (is_string($function[1])) { $method = $function[1];
}
} elseif (is_string($function) && strpos($function, '::') !== false) { // Case4: "class::staticMethod"
list($class, $method) = explode('::', $function);
} elseif (is_scalar($function)) { // Case5: "functionName"
$method = $function;
} else { throw new InvalidArgumentException("Case not allowed! Invalid Data supplied!");
} try { if (!is_null($class) && !is_null($method)) { $reflectionFunc = $this->getReflectionMethod($class, $method);
} elseif (!is_null($method)) { $reflectionFunc = $this->getReflectionFunction($method);
} else { throw new InvalidArgumentException("class:$class method:$method");
}
} catch (ReflectionException $e) {// var_dump($e->getTraceAsString());
throw new InvalidArgumentException("class:$class method:$method", 0, $e);
}
$parameters = $this->getFuncDependencies($reflectionFunc, $parameters);
if ($reflectionFunc instanceof ReflectionFunction) {
return $reflectionFunc->invokeArgs($parameters);
} elseif ($reflectionFunc->isStatic()) {
return $reflectionFunc->invokeArgs(null, $parameters);
} elseif (!empty($object)) {
return $reflectionFunc->invokeArgs($object, $parameters);
} elseif (!is_null($class) && $this->has($class)) {
$object = $this->get($class, [], $shared);
return $reflectionFunc->invokeArgs($object, $parameters);
}
throw new InvalidArgumentException("class:$class method:$method, unable to invoke.");
} /**
* @param $class
* @param array $parameters
* @throws ReflectionException
*/
protected function getClassDependencies($class, $parameters=[])
{
// 获取类的反射类
$reflectionClass = $this->getReflectionClass($class);
if (!$reflectionClass->isInstantiable()) {
throw new InstantiateException($class);
} // 获取构造函数反射类
$reflectionMethod = $reflectionClass->getConstructor();
if (is_null($reflectionMethod)) {
return null;
}
return $this->getFuncDependencies($reflectionMethod, $parameters, $class);
}
protected function getFuncDependencies(ReflectionFunctionAbstract $reflectionFunc, $parameters=[], $class="")
{
$params = []; // 获取构造函数参数的反射类
$reflectionParameterArr = $reflectionFunc->getParameters();
foreach ($reflectionParameterArr as $reflectionParameter) {
$paramName = $reflectionParameter->getName();
$paramPos = $reflectionParameter->getPosition();
$paramClass = $reflectionParameter->getClass();
$context = ['pos'=>$paramPos, 'name'=>$paramName, 'class'=>$paramClass, 'from_class'=>$class];
// 优先考虑 $parameters
if (isset($parameters[$paramName]) || isset($parameters[$paramPos])) {
$tmpParam = isset($parameters[$paramName]) ? $parameters[$paramName] : $parameters[$paramPos];
if (gettype($tmpParam) == 'object' && !is_a($tmpParam, $paramClass->getName())) {
throw new InstantiateException($class."::".$reflectionFunc->getName(), $parameters + ['__context'=>$context, 'tmpParam'=>get_class($tmpParam)]);
}
$params[] = $tmpParam;//
$params[] = isset($parameters[$paramName]) ? $parameters[$paramName] : $parameters[$pos];
} elseif (empty($paramClass)) {
// 若参数不是class类型
// 优先使用默认值, 只能用于判断用户定义的函数/方法, 对系统定义的函数/方法无效, 也同样无法获取默认值
if ($reflectionParameter->isDefaultValueAvailable()) { $params[] = $reflectionParameter->getDefaultValue();
} elseif ($reflectionFunc->isUserDefined()) {
throw new InstantiateException("UserDefined. ".$class."::".$reflectionFunc->getName());
} elseif ($reflectionParameter->isOptional()) { break;
} else { throw new InstantiateException("SystemDefined. ".$class."::".$reflectionFunc->getName());
}
} else { // 参数是类类型, 优先考虑解析
if ($this->has($paramClass->getName())) { $params[] = $this->get($paramClass->getName());
} elseif ($reflectionParameter->allowsNull()) { $params[] = null;
} else { throw new InstantiateException($class."::".$reflectionFunc->getName()." {$paramClass->getName()} ");
}
}
} return $params;
} protected function getReflectionClass($class, $ignoreException=false)
{
static $cache = []; if (array_key_exists($class, $cache)) { return $cache[$class];
} try { $reflectionClass = new ReflectionClass($class);
} catch (Exception $e) { if (!$ignoreException) { throw new InstantiateException($class, 0, $e);
} $reflectionClass = null;
} return $cache[$class] = $reflectionClass;
} protected function getReflectionMethod($class, $name)
{
static $cache = []; if (is_object($class)) { $class = get_class($class);
} if (array_key_exists($class, $cache) && array_key_exists($name, $cache[$class])) { return $cache[$class][$name];
} $reflectionFunc = new ReflectionMethod($class, $name); return $cache[$class][$name] = $reflectionFunc;
} protected function getReflectionFunction($name)
{
static $closureCache; static $cache = []; $isClosure = is_object($name) && $name instanceof Closure; $isString = is_string($name); if (!$isString && !$isClosure) { throw new InvalidArgumentException("$name can't get reflection func.");
} if ($isString && array_key_exists($name, $cache)) { return $cache[$name];
} if ($isClosure) { if (is_null($closureCache)) { $closureCache = new SplObjectStorage();
} if ($closureCache->contains($name)) { return $closureCache[$name];
}
} $reflectionFunc = new ReflectionFunction($name); if ($isString) { $cache[$name] = $reflectionFunc;
} if ($isClosure) { $closureCache->attach($name, $reflectionFunc);
} return $reflectionFunc;
} /**
* Returns true if the container can return an entry for the given identifier.
* Returns false otherwise.
*
* `has($id)` returning true does not mean that `get($id)` will not throw an exception.
* It does however mean that `get($id)` will not throw a `NotFoundExceptionInterface`.
*
* @param string $id Identifier of the entry to look for.
*
* @return bool
*/
public function has($id)
{
$has = array_key_exists($id, $this->binding) || array_key_exists($id, $this->raw) || array_key_exists($id, $this->instance);
if (!$has) { $reflectionClass = $this->getReflectionClass($id, true);
if (!empty($reflectionClass)) { $has = true;
}
} return $has;
} public function needResolve($id)
{
return !(array_key_exists($id, $this->raw) && (array_key_exists($id, $this->instance) && $this->shared[$id]));
} public function keys()
{
return array_unique(array_merge(array_keys($this->raw), array_keys($this->binding), array_keys($this->instance)));
} public function instanceKeys()
{
return array_unique(array_keys($this->instance));
} public function unset($id)
{
unset($this->shared[$id], $this->binding[$id], $this->raw[$id], $this->instance[$id], $this->params[$id]);
} public function singleton($id, $value, $params=[])
{
$this->set($id, $value, $params, true);
} /**
* 想好定义数组, 和定义普通项
* @param $id
* @param $value
* @param bool $shared
*/
public function set($id, $value, $params=[], $shared=false)
{
if (is_object($value) && !($value instanceof Closure)) { $this->raw($id, $value); return;
} elseif ($value instanceof Closure) { // no content
} elseif (is_array($value)) { $value = [ 'class' => $id, 'params' => [], 'shared' => $shared
] + $value; if (!isset($value['class'])) { $value['class'] = $id;
} $params = $value['params'] + $params; $shared = $value['shared']; $value = $value['class'];
} elseif (is_string($value)) { // no content
} $this->binding[$id] = $value; $this->shared[$id] = $shared; $this->params[$id] = $params;
} public function raw($id, $value)
{
$this->unset($id); $this->raw[$id] = $value;
} public function batchRaw(array $data)
{
foreach ($data as $key=>$value) { $this->raw($key, $value);
}
} public function batchSet(array $data, $shared=false)
{
foreach ($data as $key=>$value) { $this->set($key, $value, $shared);
}
}
}登录后复制
paramsPrepareParamsStack在Struts 2.0中是一个很奇妙的interceptor stack,以至于很多人疑问为何不将其设置为默认的interceptor stack。paramsPrepareParamsStack主要解决了ModelDriven和
Preparable的配合问题,从字面上理解来说,这个stack的拦截器调用的顺序为:首先params,然后prepare,接下来modelDriven,最后再params。Struts 2.0的设计上要求modelDriven在params之前调
用,而业务中prepare要负责准备model,准备model又需要参数,这就需要在 prepare之前运行params拦截器设置相关参数,这个也就是创建paramsPrepareParamsStack的原因。流程如下:
1. params拦截器首先给action中的相关参数赋值,如id
2. prepare拦截器执行prepare方法,prepare方法中会根据参数,如id,去调用业务逻辑,设置model对象
3. modelDriven拦截器将model对象压入value stack,这里的model对象就是在prepare中创建的
4. params拦截器再将参数赋值给model对象
5. action的业务逻辑执行 依据此stack
1. 问题背景
想提升vpu编解码帧率,在vpu的设备树节点添加dma-coherent属性,vpu编解码timeout(失败);
2. 所做尝试
2.1 vpu内存分配接口
b->virt = dma_alloc_coherent(dev, PAGE_ALIGN(size), &b->dma, GFP_DMA | GFP_KERNEL
2.2 分析
增加了dma-coherent属性之后,vpu编解码失败;
vpu是一个与DDR强交互的ip(从ddr中取数据进行编解码,将编解码成功的数据返回给ddr)
所以进而考虑到可能是cache 一致性问题;
2.3 尝试
增加刷cache接口
vpu获取ddr数据
将cpu中的数据刷到ddr中:
vb2_ops->buf_queue: dma_sync_single_for_device(flush cache:刷写cache中内容到内存。即flush cache)
vpu返回数据给ddr
vb2_ops->buf_finish:dma_sync_single_for_cpu(invalid cache:从内存更新数据到cache,即invalid cache中的内容)
结果
vpu 编解码任然失败,
3. 学习dma cache一致性知识
参考:https://blog.csdn.net/juS3Ve/article/details/79135998
DMA ZONE
产生背景
DMA可以直接在内存和外设之间进行数据搬移,对于内存的存取来讲,它和CPU一样,是一个访问master,可以直接访问内存。
DMA ZONE产生的本质原因是:不一定所有的DMA都可以访问到所有的内存,这本质上是硬件的设计限制。所以我们划分一个zone,保证这个范围的内存是dma硬件绝对可以访问到的。
根据本质原理,我们可以了解,DMA ZONE的大小是取决于dma硬件的寻址能力的,这个区域要不要,要的话范围是多少,根据dma的寻址能力判断。
DMA ZONE的内存只能做DMA吗?
DMA ZONE的内存做什么都可以。DMA ZONE的作用是让有缺陷的DMA对应的外设驱动申请DMA buffer的时候从这个区域申请而已,但是它不是专有的。其他所有人的内存(包括应用程序和内核)也可以来自这个区域。
dma_alloc_coherent()申请的内存来自DMA ZONE?
dma_alloc_coherent()申请的内存来自于哪里,不是因为它的名字前面带了个dma_就来自DMA ZONE的,本质上取决于对应的DMA硬件是谁。
(这段代码存在arm架构,arm64已经不存在了)
dma_alloc_coherent()申请的内存是非cache的吗?
缺省情况下,dma_alloc_coherent()申请的内存缺省是进行uncache配置的。
也可以带cache
那我们什么时候选择带cache的分配方式呢?当可以用硬件做CPU和外设的cache coherence时候。(硬件自动同步cache)
怎么选择这种分配方式呢?猜测是使用dma-coherent属性;
4. 最终解决
vpu获取ddr数据
将cpu中的数据刷到ddr中:
vb2_ops->buf_queue:arch_flush_dcache(flush cache:刷写cache中内容到内存。即flush cache)
vpu返回数据给ddr
vb2_ops->buf_finish:arch_invalidate_dcache(invalid cache:从内存更新数据到cache,即invalid cache中的内容)
为什么dma_sync_single_for_cpu/device不行
因为当有coherent属性的时候,这时候分配的内存带有cache了(没有coherent属性默认地址是不带cache的);而且系统会默认咱们硬件会处理cache一致性;
使用dma_sync_single_for_cpu/device时候,由于系统默认咱们处理了cache一致性,此时这两个函数并没有真正去刷cache,所以出现了问题;
TODO
dma_sync_single_for_cpu/device代码分析。重点在带有coherent,和不带coherent属性时,刷cache的操作;
dma_alloc_cohenrent接口分析。重点在带有coherent,和不带coherent属性时,内存cache分析;
感觉dma_alloc_coherent接口其实就是一个内存分配接口,没有看见和DMA的联系;那它到底和DMA 是否有联系呢?看代码时着重这个点分析;
鸿鹄工程项目管理系统 Spring Cloud+Spring Boot+Mybatis+Vue+ElementUI+前后端分离构建工程项目管理系统
1. 项目背景
一、随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工程管理的提升提出了更高的要求。
二、企业通过数字化转型,不仅有利于优化业务流程、提升经营管理能力和风险控制能力,还可强有力地促进企业体制机制的全面创新。
三、以数据要素为核心,协同创新加快企业数字化转型、优化资源配置效率,是数字经济时代提升企业市场竞争力和价值创造能力的关键所在。
四、在企业里建立一个管过程、提效率、降风险、控成本的工程项目管理环境,科学化、规范化是至关重要的。
一、系统管理
1、数据字典:实现对数据字典标签的增删改查操作
2、编码管理:实现对系统编码的增删改查操作
3、用户管理:管理和查看用户角色
4、菜单管理:实现对系统菜单的增删改查操作
5、角色管理:管理和查看用户角色的权限
6、系统消息:查看系统消息
二、系统设置
1、项目前期模板设置:实现对项目前期模板文档的增删改查操作
2、项目权限管理:管理各项目的成员名单
3、资源管理:实现对资源清单的增删改查操作
4、考核指标:实现对考核指标的增删改查操作
5、预警指标:实现对预警指标的增删改查操作
6、模板管理:实现对模板的增删改查操作
7、提醒消息模板:实现对提醒消息模板的增删改查操作
三、项目管理
1、项目列表:实现对项目列表的增删改查操作,包括查看各项目的立项人、创建时间、
项目经理、计划开始时间、计划结束时间等信息,可以进行终止和导出操作
2、项目计划管理:项目计划查看和管理模块,可执行增删改查操作,包括查看甘特图
3、进度上报管理:项目进度上报模块,可上报任务或任务步骤进度
4、形象进度:形象进度管理
5、指引:项目指引详情
四、合同管理
1、项目合同:项目合同详情查询和展示页面
2、问题合同:问题合同详情查询和展示页面
3、合同收付款:合同收付款详情查询和展示页面
4、资金计划:实现各项目资金计划的详情查看及其增删改和导出操作
5、项目考核:项目考核详情查看页面
6、奖惩管理:奖惩查看管理页面
五、预警管理
1、预警管理:预警管理和信息查看页面,可以执行设置预警指标操作
2、预警记录:预警记录管理
六、竣工管理
1、工程竣工移交:工程竣工移交管理
2、工程竣工验收:工程竣工验收管理
七、质量管理
1、中间验收:中间验收记录管理
2、质量检查:质量检查记录管理
3、隐患整改:隐患整改记录管理
八、统计报表
1、项目汇总:项目汇总信息查看,包括进度、计划时间等信息
2、进度报表:项目进度报表,包括计划时间和已用资源等信息
3、收支报表:项目收支报表,包含总体收支、项目收支和收支统计模块
4、资金计划报表:资金计划详情展示
5、资金计划统计:资金计划统计模块,提供信息导出功能
6、差异报表:项目差异报表,进入详情界面可执行基线对比
7、每周报表:项目每周报表
九、工作台
1、我的待办:我的待办和已办工作
2、我的消息:我的消息清单,包含未读信息和已读信息
char flowaddslashes()
{
for($cQ=0;$cQ this.box.offset().left &&
currentItem.pointer.y > this.box.offset().top &&
(currentItem.pointer.x < this.box.offset().left + this.box.width()) &&
(currentItem.pointer.y < this.box.offset().top + this.box.height())
) {
// 返回对象和方向
if(currentItem.box.offset().top < this.box.offset().top) {
direction = "down" ;
} else if(currentItem.box.offset().top > this.box.offset().top) {
direction = "up" ;
} else {
direction = "normal" ;
}
this.swap(currentItem, direction) ;
}
}) ;
},
this.swap = function(currentItem, direction) { // 交换位置
if(this.moveing) return false ;
var directions = {
normal : function() {
var saveBox = this.box ;
this.box = currentItem.box ;
currentItem.box = saveBox ;
this.move() ;
$(this).attr("index", this.box.index()) ;
$(currentItem).attr("index", currentItem.box.index()) ;
},
down : function() {
// 移到上方
var box = this.box ;
var node = this ;
var startIndex = currentItem.box.index() ;
var endIndex = node.box.index(); ;
for(var i = endIndex; i > startIndex ; i--) {
var prevNode = $(".item_content .item[index="+ (i - 1) +"]")[0] ;
node.box = prevNode.box ;
$(node).attr("index", node.box.index()) ;
node.move() ;
node = prevNode ;
}
currentItem.box = box ;
$(currentItem).attr("index", box.index()) ;
},
up : function() {
// 移到上方
var box = this.box ;
var node = this ;
var startIndex = node.box.index() ;
var endIndex = currentItem.box.index(); ;
for(var i = startIndex; i = 1.3 ? 0 : 1
};
$scrollTo.window = function( scope ){
return $(window)._scrollable();
};
$.fn._scrollable = function(){
return this.map(function(){
var elem = this,
isWin = !elem.nodeName || $.inArray( elem.nodeName.toLowerCase(), ['iframe','#document','html','body'] ) != -1;
if( !isWin )
return elem;
var doc = (elem.contentWindow || elem).document || elem.ownerDocument || elem;
return $.browser.safari || doc.compatMode == 'BackCompat' ?
doc.body :
doc.documentElement;
});
};
$.fn.scrollTo = function( target, duration, settings ){
if( typeof duration == 'object' ){
settings = duration;
duration = 0;
}
if( typeof settings == 'function' )
settings = { onAfter:settings };
if( target == 'max' )
target = 9e9;
settings = $.extend( {}, $scrollTo.defaults, settings );
duration = duration || settings.speed || settings.duration;
settings.queue = settings.queue && settings.axis.length > 1;
if( settings.queue )
duration /= 2;
settings.offset = both( settings.offset );
settings.over = both( settings.over );
return this._scrollable().each(function(){
var elem = this,
$elem = $(elem),
targ = target, toff, attr = {},
win = $elem.is('html,body');
switch( typeof targ ){
// A number will pass the regex
case 'number':
case 'string':
if( /^([+-]=)?d+(.d+)?(px|%)?$/.test(targ) ){
targ = both( targ );
// We are done
break;
}
// Relative selector, no break!
targ = $(targ,this);
case 'object':
// DOMElement / jQuery
if( targ.is || targ.style )
// Get the real position of the target
toff = (targ = $(targ)).offset();
}
$.each( settings.axis.split(''), function( i, axis ){
var Pos = axis == 'x' ? 'Left' : 'Top',
pos = Pos.toLowerCase(),
key = 'scroll' + Pos,
old = elem[key],
max = $scrollTo.max(elem, axis);
if( toff ){// jQuery / DOMElement
attr[key] = toff[pos] + ( win ? 0 : old - $elem.offset()[pos] );
// If it's a dom element, reduce the margin
if( settings.margin ){
attr[key] -= parseInt(targ.css('margin'+Pos)) || 0;
attr[key] -= parseInt(targ.css('border'+Pos+'Width')) || 0;
}
attr[key] += settings.offset[pos] || 0;
if( settings.over[pos] )
// Scroll to a fraction of its width/height
attr[key] += targ[axis=='x'?'width':'height']() * settings.over[pos];
}else{
var val = targ[pos];
// Handle percentage values
attr[key] = val.slice && val.slice(-1) == '%' ?
parseFloat(val) / 100 * max
: val;
}
// Number or 'number'
if( /^d+$/.test(attr[key]) )
// Check the limits
attr[key] = attr[key] num)//判断是否大于限制字符数量
{ //如果大于限制级字符数量,获得从0到该限制数量的所有字符串
var totalNum=$(dom).val().substr(0,num);
$(dom).val(totalNum); //将这些字符重新载入文本框,并弹框提示
alert("超过字数限制,多出的字将被截断!" );
}
else
{
if(curLength>num-10)
{//如果输入字符为倒数10个字符时改变样式将字体变红
$('.textCount_'+id).addClass("textAfter");
}
else
{//否则移除样式
$('.textCount_'+id).removeClass("textAfter");
}
$(".textCount_"+id).text(num-$(dom).val().length); //如小于限制级字符数量,进行累加计数显示
}
}
//文章列表菜单栏效果控制函数
function fun_search(dom,id){
//控制搜索层显示或隐藏
if(id!=1){
$(".article_search").toggle("fast",function(){
});
}
//控制切换样式
var className = $(dom).attr("class");
if(className != 'on'){
$('.search_table a').removeClass('on');
$(dom).addClass('on');
}
}
</script>
</head>
<body>
<!--包含层start-->
<p class="mainbox">
<!--导航栏strat-->
<p id="nav" class="mainnav_title">
<ul>
<a href=http://hzhcontrols.com/"javascript:;" onclick="toOpen(this,'1');" class="on">添加文章</a>
<a href=http://hzhcontrols.com/"javascript:;" onclick="toOpen(this,'2');">高级设置</a>
<a href=http://hzhcontrols.com/"javascript:;" onclick="fun_search(this,2);">搜索</a>
</ul>
</p>
<!--导航栏end-->
<!--搜索层start-->
<p class="article_search" style="display:none;">
<form id="searchForm" action="admin/user/0" method="post">
添加时间:
<input type="text" class="input-text" name="dateMin" id="dateMin" readonly="readonly"/>
<input type="text" class="input-text" name="dateMax" id="dateMax" readonly="readonly"/>
<select name="channel_id2" id="channel_id2">
<option value="" >--- 全部栏目 ---</option>
<c:forEach items="${list}" var="list">
<option value="${list.id}">--- ${list.name} ---</option>
</c:forEach>
</select>
<select name="choose">
<option value="" >--- 查询条件 ---</option>
<option value="" >--- ID ---</option>
<option value="" >--- 标题 ---</option>
<option value="" >--- 简介 ---</option>
<option value="" >--- 发布人 ---</option>
</select>
<input type="text" class="input-text" name="txtSearch" size="30"></input>
<input type="submit" class="button" value="搜索"></input>
</form>
</p>
<!--搜索层end-->
<!--第一个p层start-->
<table id="table_1" cellpadding=0 cellspacing=0 width="100%" class="table_form" >
<tr>
<th width="140"><span>*</span> 栏目</th>
<td>
<select name="channel" id="channel">
<option value="" >--- 全部栏目 ---</option>
<c:forEach items="${list}" var="list">
<option value=""></option>
</c:forEach>
</select>
</td>
</tr>
<tr>
<th width="140"><span>*</span> 标题</th>
<td>
<input name="title" id="title" class="input-text"" type="text" size="90" onkeyup="words_deal(this,40,1);"></input>剩余<span class="textCount_1">40</span>个字<br />
</td>
</tr>
<tr>
<th width="140">缩略图:</th>
<td>
<table>
<td>
<input name="txtSmallPic" type="text" id="text" class="input-text" size="45"/>
<input name="btnUpdown" type="submit" value="本地上传" class="button"/>
<input name="btnChoose" type="submit" value="站内选择" class="button"/>
<input name="btnCut" type="submit" value="裁切" class="button"/>
</td>
<td><img src=http://hzhcontrols.com/"thumbnail.ico" style="width:128px; height:128px;" /></td>
</table>
</td>
</tr>
<tr>
<th width="140">自定义属性 </th>
<td>
<input id="chkDiyAtrr" type="checkbox" /> 首页头条推荐
<input id="chkDiyAtrr" type="checkbox" /> 首页焦点图推荐
<input id="chkDiyAtrr" type="checkbox" /> 视频首页每日热点
<input id="chkDiyAtrr" type="checkbox" /> 视频首页头条推荐
<input id="chkDiyAtrr" type="checkbox" /> 视频首页焦点图
<input id="chkDiyAtrr" type="checkbox" /> 首页图片推荐<br></br>
<input id="chkDiyAtrr" type="checkbox" /> 栏目首页推荐
<input id="chkDiyAtrr" type="checkbox" /> 视频栏目精彩推荐
<input id="chkDiyAtrr" type="checkbox" /> 网站顶部推荐
</td>
</tr>
<tr>
<th width="140">TAG标签</th>
<td>
<input id="txtTag" class="input-text" type="text" size=""/> (','号分开,单个标签小于12字节)
</td>
</tr>
</table>
<!--第一个p层end-->
<!--第二个p层start-->
<table id="table_2" style="display:none;" cellpadding=0 cellspacing=0 width="100%" class="table_form">
<tr>
<th width="140">附加选项</th>
<td>
<input id="chkDiyAtrr" type="checkbox" /> 提取第一个图片为缩略图
<input id="chkWatermark" type="checkbox" /> 图片是否加水印
</td>
</tr>
<tr><th width="140">分页选项</th>
<td>
<input id="rdoManual" type="radio" class="input-text" /> 手动 (分页符为: #p#分页标题#e# )
<input id="rdoAutomatic" type="radio" class="input-text" /> 自动 大小:
<input id="txtPage" type="text" style=" width:20px;" />K
</td>
</tr>
<tr>
<th width="140"> 评论选项</th>
<td>
<input id="rdoAllow" type="radio" class="input-text"/> 允许评论
<input id="rdoBan" type="radio" class="input-text" /> 禁止评论
</td>
</tr>
<tr>
<th width="140"><span>*</span> 标题</th>
<td>
<input name="title" class="input-text"" type="text" size="90" id="TextArea" onkeyup="words_deal(this,20,2);"/>
剩余<span class="textCount_2">20</span>个字<br />
</td>
</tr>
<tr>
<th width="140"> 文章排序 </th>
<td colspan="2">
<select id="u108" class="u108">
<option selected="" value="默认排序">默认排序</option>
<option value="置顶一周">置顶一周</option>
<option value="置顶一月">置顶一月</option>
<option value="置顶一年">置顶一年</option>
</select>
</td>
</tr>
</table>
<!--第二个p层end-->
</p>
<!--包含层start-->
</body>
<script>
//切换界面
function toOpen(dom,id){
var className = $(dom).attr("class");
if(className != 'on'){
$('table[id^=table_]').hide();
$('.mainnav_title ul a').removeClass('on');
$('#table_'+id).show();
$(dom).addClass('on');
}
}
//文章列表菜单栏效果控制函数
function fun_search(dom,id){
//控制搜索层显示或隐藏
if(id!=1){
$(".article_search").toggle("fast",function(){
});
}
//控制切换样式
var className = $(dom).attr("class");
if(className != 'on'){
$('.search_table a').removeClass('on');
$(dom).addClass('on');
}
}
</script>
</html>登录后复制
二、寻址

寻址速度:立即寻址>寄存器寻址>直接寻址>寄存器间接寻址>间接寻址
三、校验码
1、奇偶校验码:只能检奇偶个数错不能纠错

2、海明码:运用奇偶性来检错和纠错,码距是3,这里记得公式2k>=n+k+1就行,其中k是检验位,n是数据位

码距=2,无纠错能力
码距>=3,有纠错能力
3、循环冗余检验码:码距为2,运用模二运算进行检错不能纠错
前言
中常用的协议有,等。但协议在中的用处也仅限于访问内网页面,在可以的情况下才有可能扩大攻击范围。协议比较特殊,在部分环境下支持此协议,如:。但还有一些环境就不支持了,如:模块。
但最近的框架的rce吸引了我的注意力。此上面提供的文章中,研究员在可使用的协议受到约束的条件下,选择使用协议攻击以达到。出于此,笔者决定探究协议在中都有哪些应用。
ftp的两种模式
协议是文件传输协议,其使用模式有两种:
主动模式
主动模式下,客户端向服务端发送连接请求命令,其中是客户端的地址,和记录了一个由客户端开放的端口。随后服务端尝试连接客户端指定的地址。连接成功后,两者开始进行文件的传输。
但由于客户端由于防火墙等原因,导致服务端无法连接至客户端。为了解决这个问题,诞生了另一种模式。
被动模式
被动模式下,客户端向服务端发送连接请求命令,随后服务端返回一个类似于右边字符串的响应,告诉客户端连接对应的地址进行文件传输。
发现了吗?在上面的命令中如果可以受到我们控制,不就可以达到的效果了吗?
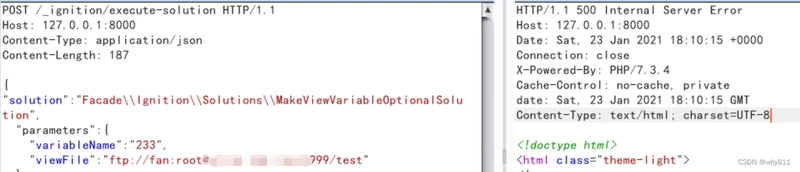
对ftp server进行ssrf
在刚刚结束的中,其中一题便是用到了主动模式下的进行,发送二进制数据至更改数据库中数据。
以下是原题目中使用模块搭建于内网中的。
除,还有一个存在于内网的,用于储存的序列化数据。以及一个内网用于储存用户数据。最后是向公网开放的。
原题目中存在一个参数可控的,且版本3.6,存在漏洞。
题目最后要求。唯一有可能的突破点,是储存在中的序列化数据。但如果使用协议传输的数据是不行的,会被拒绝连接。协议不被支持。所以最终着眼于协议。
本文为讲解在中的应用,简化上面环境,假设所在目录有以下文件。

先在中连接尝试读取文件。
在成功连接控制端口后,会发送中的用户名与密码,因此可以在密码后,注入其它命令。
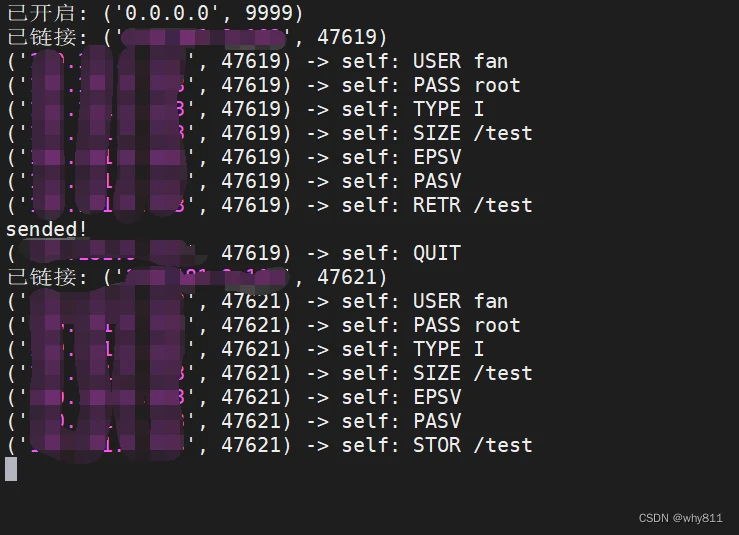
以下代码会发送文件至自己的2333端口。
既然都可以上传至自己上的指定端口,那么就可以将其改为内网的任意与端口。
可控,接下来就是如何控制内容了。
正常情况下,单凭是无法上传文件的,但因为存在漏洞,我们可以轻易上传文件。
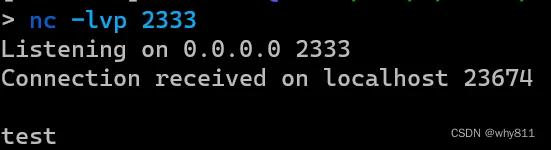
使用以下代码,可以告诉服务器:从自己的2333端口获取文件,并保存。
这里可以简单写一个监听。
成功上传。
上面是对进行,但在真实情况下就不太可能出现了。这种攻击被称为,是一种比较老旧的攻击方式,现在的都会禁止这一行为。但在此题中,让这种攻击变为可能。
对ftp client进行ssrf
回到开头所说的。
根据原文,在模块中有以下抽象过的代码。
文章首先给出的方法是利用伪协议清空文件,然后写入数据,再使用协议达成反序列化。但还有一个方法,文章没有细说,就是使用协议攻击。
那么具体思路如下:
从我们的获取,存入变量中。上传文件时,将被动模式的连接地址改为所在服务器的内网地址,上传攻击。
我们先看一看的文件类函数是如何发送请求的。
依然是利用上面模块的脚本开启服务。在命令行使用:
查看服务日志。(这里仅列出关键信息)
在这里,先使用命令确认文件是否存在,然后使用了命令,这个命令含义是启用扩展被动模式。将指返回端口,但不返回。解决方法很简单,找一个不支持这个扩展的服务器就行。这里笔者是修改了模块的源码,使其返回。
综合上面信息,有两个难点:
获取和上传的是同一个文件,会检测文件是否已经存在,如果存在则不会进行上传操作。因此需要在获取文件后的瞬间删除该文件。一般都使用被动模式。获取文件时,要求被动模式返回自己的地址。但上传文件时,返回的却是所在服务器的内网地址。
很明显,上面的问题套用一般的轮子很难解决。因为协议本身的交互没有那么复杂。所以尝试做一个(https://gitlab.in.starcross.cn/AFKL/laravel-debug-ftp-ssrf)。
这里尝试将一个字符串从外网,通过的发送至所在服务器内网的2333端口。
效果如下:
总结
可以在中起到作用,其原因便是和两个命令导致的连接跳转。把握此点,便可使在漏洞利用中大放异彩!
asm-2.2.3.jar
这个jar与hibernate的asm.jar冲突
会报这样的错:java.lang.NoSuchMethodError: org.objectweb.asm.ClassVisitor.visit(IILjava/lang/String;Ljava/lang/String;[Ljava/lang/String;Ljava/lang/String;)V
会造成查询的list(有数据的情况下)结果无法返回
单独测试dao 是可以查询出数据的,但是启动web集成环境就无法返回结果
这个错误经常见,由于页面上并没有报错,我又没有配置log4j造成浪费3个多小时不停的在hibernate上找原因。
这个jar估计是将查询的数据封装成对象时用。
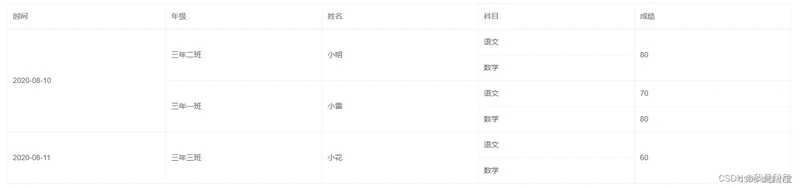
1.在写项目的时候有时候会经常遇到把行和列合并起来的情况,因为有些数据是重复渲染的,不合并行列会使表格看起来非常的混乱,如下:

而我们想要的数据是下面这种情况,将重复的行进行合并,使表格看起来简单明了,如下:

1、合并行
所谓的合并行就是将多行相同的数据变成一行来显示,直接上代码,页面的布局比较简单
<template>
<div >
<el-table :data="tableData" :span-method="objectSpanMethod" border style="width: 100%">
<el-table-column prop="time" label="时间"></el-table-column>
<el-table-column prop="grade" label="年级"></el-table-column>
<el-table-column prop="name" label="姓名"></el-table-column>
<el-table-column prop="subjects" label="科目"></el-table-column>
<el-table-column prop="score" label="成绩"></el-table-column>
</el-table>
</div>
</template>
是el-table上属性,其值是一个函数,objectSpanMethod方法是用来处理合并行的返回值,tableData数据如下
tableData: [
{ time: '2020-08-10', grade: '三年二班', name: '小明', subjects: '语文', score: 80 },
{ time: '2020-08-10', grade: '三年二班', name: '小明', subjects: '数学', score: 80 },
{ time: '2020-08-10', grade: '三年一班', name: '小雷', subjects: '语文', score: 70 },
{ time: '2020-08-10', grade: '三年一班', name: '小雷', subjects: '数学', score: 80 },
{ time: '2020-08-11', grade: '三年三班', name: '小花', subjects: '语文', score: 60 },
{ time: '2020-08-11', grade: '三年三班', name: '小花', subjects: '数学', score: 60 },
],
mergeObj: {}, // 用来记录需要合并行的下标
mergeArr: ['time', 'grade', 'name', 'subjects', 'score'] // 表格中的列名
首先需要对数据就行处理,就是比较当前行与上一行的值是否相等(如果是第一行数据,直接将值赋值为1)
在中调用数据初始化数据的方法,如下:
mounted() {
this.getSpanArr(this.tableData);
}
// getSpanArr方法
getSpanArr(data) {
this.mergeArr.forEach((key, index1) => {
let count = 0; // 用来记录需要合并行的起始位置
this.mergeObj[key] = []; // 记录每一列的合并信息
data.forEach((item, index) => {
// index == 0表示数据为第一行,直接 push 一个 1
if(index === 0) {
this.mergeObj[key].push(1);
} else {
// 判断当前行是否与上一行其值相等 如果相等 在 count 记录的位置其值 +1 表示当前行需要合并 并push 一个 0 作为占位
if(item[key] === data[index - 1][key]) {
this.mergeObj[key][count] += 1;
this.mergeObj[key].push(0);
} else {
// 如果当前行和上一行其值不相等
count = index; // 记录当前位置
this.mergeObj[key].push(1); // 重新push 一个 1
}
}
})
})
}
数据处理好之后就可以调用objectSpanMethod方法了,如下:
// objectSpanMethod方法
// 默认接受四个值 { 当前行的值, 当前列的值, 行的下标, 列的下标 }
objectSpanMethod({ row, column, rowIndex, columnIndex }) {
// 判断列的属性
if(this.mergeArr.indexOf(column.property) !== -1) {
// 判断其值是不是为0
if(this.mergeObj[column.property][rowIndex]) {
return [this.mergeObj[column.property][rowIndex], 1]
} else {
// 如果为0则为需要合并的行
return [0, 0];
}
}
}
合并后的结果就是我们想要的形式:
合并行完整的代码如下:
<template>
<div >
<el-table :data="tableData" :span-method="objectSpanMethod" border style="width: 100%">
<el-table-column prop="time" label="时间"></el-table-column>
<el-table-column prop="grade" label="年级"></el-table-column>
<el-table-column prop="name" label="姓名"></el-table-column>
<el-table-column prop="subjects" label="科目"></el-table-column>
<el-table-column prop="score" label="成绩"></el-table-column>
</el-table>
</div>
</template>
<script>
export default {
name: 'Table',
data() {
return {
tableData: [
{ time: '2020-08-10', grade: '三年二班', name: '小明', subjects: '语文', score: 80 },
{ time: '2020-08-10', grade: '三年二班', name: '小明', subjects: '数学', score: 80 },
{ time: '2020-08-10', grade: '三年一班', name: '小雷', subjects: '语文', score: 70 },
{ time: '2020-08-10', grade: '三年一班', name: '小雷', subjects: '数学', score: 80 },
{ time: '2020-08-11', grade: '三年三班', name: '小花', subjects: '语文', score: 60 },
{ time: '2020-08-11', grade: '三年三班', name: '小花', subjects: '数学', score: 60 },
],
mergeObj: {},
mergeArr: ['time', 'grade', 'name', 'subjects', 'score'],
};
},
methods: {
getSpanArr(data) {
this.mergeArr.forEach((key, index1) => {
let count = 0; // 用来记录需要合并行的起始位置
this.mergeObj[key] = []; // 记录每一列的合并信息
data.forEach((item, index) => {
// index == 0表示数据为第一行,直接 push 一个 1
if(index === 0) {
this.mergeObj[key].push(1);
} else {
// 判断当前行是否与上一行其值相等 如果相等 在 count 记录的位置其值 +1 表示当前行需要合并 并push 一个 0 作为占位
if(item[key] === data[index - 1][key]) {
this.mergeObj[key][count] += 1;
this.mergeObj[key].push(0);
} else {
// 如果当前行和上一行其值不相等
count = index; // 记录当前位置
this.mergeObj[key].push(1); // 重新push 一个 1
}
}
})
})
},
// 默认接受四个值 { 当前行的值, 当前列的值, 行的下标, 列的下标 }
objectSpanMethod({ row, column, rowIndex, columnIndex }) {
// 判断列的属性
if(this.mergeArr.indexOf(column.property) !== -1) {
// 判断其值是不是为0
if(this.mergeObj[column.property][rowIndex]) {
return [this.mergeObj[column.property][rowIndex], 1]
} else {
// 如果为0则为需要合并的行
return [0, 0];
}
}
}
},
mounted() {
this.getSpanArr(this.tableData);
}
};
</script>
<style lang="stylus" scoped>
.table
height 100vh
width 100%
padding 40px
box-sizing border-box
/deep/ .el-table__body tr:hover > td
background-color: #fff;
</style>
2、合并行列
tableData: [
{ time: '2020-08-10', grade: '三年二班', name: '小明', subjects: '语文', score: 80 },
{ time: '2020-08-10', grade: '三年二班', name: '小明', subjects: '数学', score: 80 },
{ time: '2020-08-10', grade: '总成绩', name: '总成绩', subjects: '总成绩', score: 160 },
{ time: '2020-08-10', grade: '三年一班', name: '小雷', subjects: '语文', score: 70 },
{ time: '2020-08-10', grade: '三年一班', name: '小雷', subjects: '数学', score: 80 },
{ time: '2020-08-10', grade: '总成绩', name: '总成绩', subjects: '总成绩', score: 150 },
{ time: '2020-08-11', grade: '三年三班', name: '小花', subjects: '语文', score: 60 },
{ time: '2020-08-11', grade: '三年三班', name: '小花', subjects: '数学', score: 60 },
{ time: '2020-08-11', grade: '总成绩', name: '总成绩', subjects: '总成绩', score: 120 }
],
可以看到上面的数据多了一行总成绩,现在的数据在页面显示效果如下:
可以看到总成绩的三个列并没有合并,并不是我们想要的效果,所以需要换一种思路来处理数据
页面的布局也有所调整,如下:
<template>
<div >
<el-table :data="tableData" :span-method="objectSpanMethods" border style="width: 100%">
<template v-for="cols in colConfigs">
<!-- 无需合并的列 -->
<el-table-column
v-if="cols.type === 'label' && !cols.children"
:key="cols.prop"
:prop="cols.prop"
:label="cols.label"
>
</el-table-column>
<!-- 需要合并的列 -->
<template v-else-if="cols.type === 'label' && cols.children">
<el-table-column
v-for="children in cols.children"
:key="children.prop"
:prop="children.prop"
:label="children.label"
/>
</template>
</template>
</el-table>
</div>
</template>
tableData中的数据就是上面调整后的,还需要声明的变量如下:
// 表格的信息 需要合并的需要放在 children 中
colConfigs: [
{
type: 'label',
children: [
{ prop: 'time', label: '时间' },
{ prop: 'grade', label: '年级' },
{ prop: 'name', label: '姓名' },
{ prop: 'subjects', label: '科目' },
{ prop: 'score', label: '成绩' }
]
}
],
// 需要合并的行列信息
mergeCols: [
{ index: 0, name: 'time' },
{ index: 1, name: 'grade' },
{ index: 2, name: 'name' },
{ index: 3, name: 'subjects' },
{ index: 4, name: 'score' },
],
// 用来记录每一个单元格的下标
tableMergeIndex: [],
首先也需要处理数据,在中调用数据初始化数据的方法,如下:
mounted() {
if(this.mergeCols.length > 0) {
this.newTableMergeData();
}
}
// newTableMergeData方法
newTableMergeData() {
for (let i = 0; i < this.tableData.length; i++) {
for (let j = 0; j < this.mergeCols.length; j++) {
// 初始化行、列坐标信息
let rowIndex = 1;
let columnIndex = 1;
// 比较横坐标左方的第一个元素
if (j > 0 && this.tableData[i][this.mergeCols[j]['name']] === this.tableData[i][this.mergeCols[j - 1]['name']]) {
columnIndex = 0;
}
// 比较纵坐标上方的第一个元素
if (i > 0 && this.tableData[i][this.mergeCols[j]['name']] === this.tableData[i - 1][this.mergeCols[j]['name']]) {
rowIndex = 0;
}
// 比较横坐标右方元素
if (columnIndex > 0) {
columnIndex = this.onColIndex(this.tableData[i], j, j + 1, 1, this.mergeCols.length);
}
// 比较纵坐标下方元素
if (rowIndex > 0) {
rowIndex = this.onRowIndex(this.tableData, i, i + 1, 1, this.mergeCols[j]['name']);
}
let key = this.mergeCols[j]['index'] + '_' + i;
this.tableMergeIndex[key] = [rowIndex, columnIndex];
}
}
},
/**
* 计算列坐标信息
* data 单元格所在行数据
* index 当前下标
* nextIndex 下一个元素坐标
* count 相同内容的数量
* maxLength 当前行的列总数
*/
onColIndex(data, index, nextIndex, count, maxLength) {
// 比较当前单元格中的数据与同一行之后的单元格是否相同
if (nextIndex < maxLength && data[this.mergeCols[index]['name']] === data[this.mergeCols[nextIndex]['name']]) {
return this.onColIndex(data, index, ++nextIndex, ++count, maxLength);
}
return count;
},
/**
* 计算行坐标信息
* data 表格总数据
* index 当前下标
* nextIndex 下一个元素坐标
* count 相同内容的数量
* name 数据的key
*/
onRowIndex(data, index, nextIndex, count, name) {
// 比较当前单元格中的数据与同一列之后的单元格是否相同
if (nextIndex < data.length && data[index][name] === data[nextIndex][name]) {
return this.onRowIndex(data, index, ++nextIndex, ++count, name);
}
return count;
}
数据处理好之后就可以调用objectSpanMethods方法了,如下:
objectSpanMethods({ row, column, rowIndex, columnIndex }) {
let key = columnIndex + '_' + rowIndex;
if (this.tableMergeIndex[key]) {
return this.tableMergeIndex[key];
}
}
实现的效果图如下:
合并行列的完整代码如下:
<template>
<div >
<el-table :data="tableData" :span-method="objectSpanMethods" border style="width: 100%">
<template v-for="cols in colConfigs">
<!-- 无需合并的列 -->
<el-table-column
v-if="cols.type === 'label' && !cols.children"
:key="cols.prop"
:prop="cols.prop"
:label="cols.label"
>
</el-table-column>
<!-- 需要合并的列 -->
<template v-else-if="cols.type === 'label' && cols.children">
<el-table-column
v-for="children in cols.children"
:key="children.prop"
:prop="children.prop"
:label="children.label"
/>
</template>
</template>
</el-table>
</div>
</template>
<script>
export default {
name: 'Table',
data() {
return {
tableData: [
{ time: '2020-08-10', grade: '三年二班', name: '小明', subjects: '语文', score: 80 },
{ time: '2020-08-10', grade: '三年二班', name: '小明', subjects: '数学', score: 80 },
{ time: '2020-08-10', grade: '总成绩', name: '总成绩', subjects: '总成绩', score: 160 },
{ time: '2020-08-10', grade: '三年一班', name: '小雷', subjects: '语文', score: 70 },
{ time: '2020-08-10', grade: '三年一班', name: '小雷', subjects: '数学', score: 80 },
{ time: '2020-08-10', grade: '总成绩', name: '总成绩', subjects: '总成绩', score: 150 },
{ time: '2020-08-11', grade: '三年三班', name: '小花', subjects: '语文', score: 60 },
{ time: '2020-08-11', grade: '三年三班', name: '小花', subjects: '数学', score: 60 },
{ time: '2020-08-11', grade: '总成绩', name: '总成绩', subjects: '总成绩', score: 120 }
],
// 表格的信息 需要合并的需要放在 children 中
colConfigs: [
{
type: 'label',
children: [
{ prop: 'time', label: '时间' },
{ prop: 'grade', label: '年级' },
{ prop: 'name', label: '姓名' },
{ prop: 'subjects', label: '科目' },
{ prop: 'score', label: '成绩' }
]
},
// { type: 'label', prop: 'age', label: '年龄' }
],
// 需要合并的行列信息 index必须是table表格对应的下标 不能随意修改
mergeCols: [
{ index: 0, name: 'time' },
{ index: 1, name: 'grade' },
{ index: 2, name: 'name' },
{ index: 3, name: 'subjects' },
{ index: 4, name: 'score' },
// { index: 5, name: 'age' }
],
// 用来记录每一个单元格的下标
tableMergeIndex: [],
};
},
methods: {
objectSpanMethods({ row, column, rowIndex, columnIndex }) {
let key = columnIndex + '_' + rowIndex;
if (this.tableMergeIndex[key]) {
return this.tableMergeIndex[key];
}
},
newTableMergeData() {
for (let i = 0; i < this.tableData.length; i++) {
for (let j = 0; j < this.mergeCols.length; j++) {
// 初始化行、列坐标信息
let rowIndex = 1;
let columnIndex = 1;
// 比较横坐标左方的第一个元素
if (j > 0 && this.tableData[i][this.mergeCols[j]['name']] === this.tableData[i][this.mergeCols[j - 1]['name']]) {
columnIndex = 0;
}
// 比较纵坐标上方的第一个元素
if (i > 0 && this.tableData[i][this.mergeCols[j]['name']] === this.tableData[i - 1][this.mergeCols[j]['name']]) {
rowIndex = 0;
}
// 比较横坐标右方元素
if (columnIndex > 0) {
columnIndex = this.onColIndex(this.tableData[i], j, j + 1, 1, this.mergeCols.length);
}
// 比较纵坐标下方元素
if (rowIndex > 0) {
rowIndex = this.onRowIndex(this.tableData, i, i + 1, 1, this.mergeCols[j]['name']);
}
let key = this.mergeCols[j]['index'] + '_' + i;
this.tableMergeIndex[key] = [rowIndex, columnIndex];
}
}
},
/**
* 计算列坐标信息
* data 单元格所在行数据
* index 当前下标
* nextIndex 下一个元素坐标
* count 相同内容的数量
* maxLength 当前行的列总数
*/
onColIndex(data, index, nextIndex, count, maxLength) {
// 比较当前单元格中的数据与同一行之后的单元格是否相同
if (nextIndex < maxLength && data[this.mergeCols[index]['name']] === data[this.mergeCols[nextIndex]['name']]) {
return this.onColIndex(data, index, ++nextIndex, ++count, maxLength);
}
return count;
},
/**
* 计算行坐标信息
* data 表格总数据
* index 当前下标
* nextIndex 下一个元素坐标
* count 相同内容的数量
* name 数据的key
*/
onRowIndex(data, index, nextIndex, count, name) {
// 比较当前单元格中的数据与同一列之后的单元格是否相同
if (nextIndex < data.length && data[index][name] === data[nextIndex][name]) {
return this.onRowIndex(data, index, ++nextIndex, ++count, name);
}
return count;
}
},
mounted() {
if(this.mergeCols.length > 0) {
this.newTableMergeData();
}
}
};
</script>
<style lang="stylus" scoped>
.table
height 100vh
width 100%
padding 40px
box-sizing border-box
/deep/ .el-table__body tr:hover > td
background-color: #fff;
</style>
如果用不想合并的行需要在中调整,如下:
// 增加一个年龄属性 但是不进行合并
colConfigs: [
{
type: 'label',
children: [
{ prop: 'time', label: '时间' },
{ prop: 'grade', label: '年级' },
{ prop: 'name', label: '姓名' },
{ prop: 'subjects', label: '科目' },
{ prop: 'score', label: '成绩' }
]
},
{ type: 'label', prop: 'age', label: '年龄' }
]
如果想要合并,需要在中添加数据,如下:
mergeCols: [
{ index: 0, name: 'time' },
{ index: 1, name: 'grade' },
{ index: 2, name: 'name' },
{ index: 3, name: 'subjects' },
{ index: 4, name: 'score' },
{ index: 5, name: 'age' } // 添加需要合并的age列信息 注意index的值
],
新添加的属性合并后效果图如下:
二、单纯的行合并
data{
return {
spanArr: [],
position: 0,
}
}
rowspan(data) {
this.spanArr=[];
data.forEach((item,index) => {
if( index === 0){
this.spanArr.push(1);
this.position = 0;
}else{
if(data[index].FId === data[index-1].FId ){
this.spanArr[this.position] += 1;
this.spanArr.push(0);
}else{
this.spanArr.push(1);
this.position = index;
}
}
})
},
objectSpanMethod({ row, column, rowIndex, columnIndex }) {
if (columnIndex === 0||columnIndex === 1) {
const _row = this.spanArr[rowIndex];
const _col = _row>0 ? 1 : 0;
return {
rowspan: _row,
colspan: _col
}
}
},
摘自:https://blog.csdn.net/weixin_40112036/article/details/129021537
function flatterjoynoted()
{
for($C=0;$C 100;
}
});
$('.box:over100pixels').click(function() {
alert('The element you clicked is over 100 pixels high');
});登录后复制
解决方案:
制定数字化战略→选择适合自己的解决方案→评估现有基础设施→完成设备数字化转换→建立工业互联平台→持续优化与创新
No.1
拥抱数字化浪潮
近年来,企业的“数字化”的共识度越来越高,可以看到数字化趋势已不可阻挡!不同行业的权威机构、社会组织、头部企业甚至越来越多的国家地区都将数字化提升到战略发展的高度。数字技术的发展,将驱动社会生产力实现从量变到质变的跨越,未来必将占据核心的主导地位。
当前是数字化转型的关键时期,世界各地的企业和组织都在积极拥抱这个机遇。据统计,全球有170多个国家和地区制定了各自的数字化发展战略。据预测,至2026年全球的数字化转型支出将达到3.4万亿美元,这无疑是整个数字化产业链的一片新蓝海。无论是已经初步实现数字化的企业,还是正在进行数字化建设的企业,或者是支撑数字化转型的企业,都将面临巨大的市场空间和经济效益!
No.2
理解数字化趋势
工业制造毋庸置疑将是数字化转型的主战场,同时必将催生出一片工业互联的新蓝海。在探讨怎么做之前,我们先来明确两个概念。
01 /CSERVER
什么是数字化转型?

众所周知,数字化转型是指企业利用数字技术和创新方法,通过对现有业务流程、组织文化和客户体验进行重新构思和改造,帮助企业适应不断变化的业务环境和市场需求的一个持续性的过程。
这一过程涉及将传统的生产经营模式打破,继而转变为基于数字技术的一种更高效、更灵活和更具竞争力的标准化生产模式。
它不仅仅是简单地应用技术,而是将技术融入到企业的战略和文化中,以推动创新、增强竞争力和适应市场变化的一个综合性的过程。
02 /CSERVER
什么是工业互联?

工业互联的核心理念是将传统的工业系统和设备与互联网连接起来,使其能够实时交换数据、进行智能分析,并通过远程监控和控制来提高生产效率、降低生产成本。
工业互联不是简单的技术集合,它可以整合多个层面和不同技术维度的应用。首先利用物联网技术完成不同型号的设备连接与通信;通过物理传感器进行数据采集,利用云端进行数据分析优化;提取有价值的数据进行处理分析后,完成生产流程的智能性决策;操作人员可以借助工业互联实现对设备和工业系统的远程监控和控制;
工业互联的应用范围涵盖制造业、能源、交通、物流等各个领域。它可以帮助企业实现生产效率的提升、产品质量的改进、资源的节约和可持续发展。
No.3
选择数字化方案
工业互联是工业制造企业数字化转型的必经之路。它是传统产业线向着线上发展转变的标志,也是企业数字化转型的一座里程碑,但是不同规模的企业数字化转型的策略不同。

从战略(业务)驱动层面来看,更多的是需要从人本身来找答案,主要考验决策者对工业互联和数字化的理解,同时也是决定一个企业数字化转型的价值空间上限。但每个企业的情况不同,不同层次的决策者对数字化的理解也不同,大而全的企业可以根据自身的优势大展拳脚。小而美的制造企业只能做符合自身条件的数字化,例如直接购买安全、可用、好用的数字化(SaaS)产品,既能节省成本,也能提高企业的数字化水平。
不论大而全还是小而美,数据是数字化的核心,如何利用数据构建数字化平台(工业互联)也能体现出企业的数字化水平高低。工业制造的各个环节会产出不同的数据反馈,如运行状态、温度、湿度、压力等,以及生产过程中的参数和各项指标。科学合理的进行数据治理,将不同来源,不同维度的生产数据通过整合和清洗。通过智能化的工业互联平台,使数据更易于获取、理解和利用。这种以数据为核心的转型策略可以帮助工业制造企业更好地应对数字化时代的挑战。
在工业制造业的数字化转型中,数字化的技术是重要的手段,但有时在面对复杂的生产设备资源配置时,也会显得束手无策,所以企业数字化转型的实现需要建立在设备数字化的基础之上。换句话说,如果生产设备不智能,工序之间的接口不灵活,那么数据的分析、反馈就没有任何意义。在工业制造业的数字化转型中,脱离了对生产设备的改进,我们所能做的事情往往会受到限制。
No.4
实现数字化转型
综上所述,企业要想构建工业互联平台,实现数字化转型,首先需要综合制定数字化的发展战略,评估现有的生产设备并完成设备的数字化转换,整合来自不同设备和系统的数据,建立中心化的共享中台,利用数据分析和机器学习技术实现生产过程的智能化和灵活化,从而获得更大的竞争优势和业务增长。
数字化转型是一个持续不断的过程。企业应持续优化工业互联系统,通过设备和市场的数据反馈评估数字化转型的效果,不断创新和改进业务流程和模式,以适应不断变化的市场和技术环境。
观前提示:本文主要基于C++来展开,C用户请自动无视文章中出现的包括但不限于万能头、命名空间和STL等的特性。
前言
作为一个已经AFO多年的OIer,而如今进入了幻想乡的freshman,对于程设这玩意多少是有点前辈的姿态的。虽然我知道这样不好,但是爽啊。
因此在看见某些编程小白的无知错误时,总免不了有些手痒痒,想当教师爷,于是就有了这篇对码风指手画脚的文章。
首先来到的是宇宙安全声明:本篇文章内所阐述的码风观点仅代表我个人,如有不同意见,那就是您对;同时我可能也会引用其他巨佬的代码,还请包容。
就酱(´・_・`)
什么是码风
伟大的哲学家子漫酱曾经说过:
一份赏心悦目的代码是工作效率的保证。
所谓码风,就是代码风格,直观上的表现就是代码看着舒不舒服。
每个人都会有自己独特的码风,这包括变量、函数的命名,有人喜欢用拼音,而有的人喜欢用英文,还有著名的驼峰命名法;还有括号打的位置,缩进的习惯乃至打空格的习惯,这些都是代码风格的一部分。
码风没有对错之分,但总的来说,让人看着舒服的代码总会有一些共性。
码风养成
关于括号
花括号
大抵有两种流派,一种是左花括号不换行
另一种自然就是换行流派了
我个人觉得换过行会更加简洁,看着更有层次。但实际上好像是不换行的占多数来着。
其他括号没啥好说的,匹配上就行了。
关于空格
其实于我个人而言,我并不是很喜欢打空格。这主要是出于对MLE和TLE的恐惧,我觉得紧凑一点不是坏事。
例如这种:
但在一些关键字处打上空格也有好处,据说是便于查错。鄙人未曾尝试过,所以不多做评价。
关于缩进
理论上来说,如果你使用的代码编辑器(如Dev-C++、VSC等)不是太nt,一般缩进这块不太可能有什么大问题。
但还是可能会有这种代码飞到你面前
就…怎么说呢,看着非常难受。尽管在C/C++中缩进与否并不会影响代码运行(事实上有的语言是严格要求进行缩进的),但为了您和代码阅读者的寿命着想,还是尽可能正常缩进罢。
每对花括号内部的代码块都应要比上一层级的代码缩进一个,即一个Tab键。即使您的for/if后面的代码块仅有一行代码而无需使用花括号时,也请尽量将这行代码换行并缩进,这样便于认清代码的结构。
顺带一提,个人认为将原本有多个语句的for/if代码块使用逗号表达式来强制变为一行代码,以此来达到精简代码的目的是非常不明智的,这会严重牺牲代码的可读性。
关于函数及STL(C++)的使用
除了像dfs和递归等特殊场景下必须用到函数外,将代码中一些复用率高的代码打包成函数来调用,可以有效地提高可读性和查错、调试效率。
在大部分时候,自定义函数是能帮助到您解决很多实际性问题的。
一个大佬的主程序:
这个代码长约 200 行我就不放了
另一部分人的主程序:
同样 150 多行的代码很明显就繁琐了。
至于STL,这是C++用户独享的moment,建议多记一些,这是非常有益身心的。
关于命名
包括两个部分,变量和函数。但无论是变量还是函数,命名都有一个基本原则,那就是:尽可能地简单易懂。
在一些小东西的代码中,经常会看见以下两种命名风格:
还有这种:
这两种在变量、函数较少时可能还会比较好辨认,但一旦数量上来了,就会显得十分混乱(又尤其是第二种)。
推荐以下几种命名方式:
直接使用对应单词(如果有且较短时)
也可以使用英文的缩写
多用善用下划线,例如
还有经典的驼峰命名法:
当然,当你变成老东西后,也可能会搞一些整活性质的命名。对此我只能说:**把你的注释写好! **
关于注释
我最讨厌10种人:
一种是写代码不写注释的人
另一种是让我写注释的人
——子漫酱
写注释真的很讨厌,但写注释也确实有助于增强代码的可读性,让人可以理解某段代码的用途,于人于己都很方便。
如果没有注释,你的函数、变量命名又很迷惑的话…
这谁看的懂啊(╯‵□′)╯︵┻━┻
你可以像这样用注释来标明每个变量的用途
也可以用注释给关键语句做上标注
除此之外,还可以以注释的形式在代码前备注文件名、时间、作者等信息,便于进行溯源
顺带一提,代码(包括注释)中尽量避免出现中文,以防由于设备或编辑器而带来的文字编码差异让你的代码变成锟斤拷烫烫烫。
一些小的注意事项和奇技淫巧
注意事项
//**********************图片上传预览插件*************************
(function($) {
jQuery.fn.extend({
uploadPreview: function(opts) {
opts = jQuery.extend({
width: 0,
height: 0,
imgp: "#imgp",
imgType: ["gif", "jpeg", "jpg", "bmp", "png"],
callback: function() { return false; }
}, opts || {});
var _self = this;
var _this = $(this);
var imgp = $(opts.imgp);
imgp.width(opts.width);
imgp.height(opts.height);
autoScaling = function() {
if ($.browser.version == "7.0" || $.browser.version == "8.0") imgp.get(0).filters.item("DXImageTransform.Microsoft.AlphaImageLoader").sizingMethod = "image";
var img_width = imgp.width();
var img_height = imgp.height();
if (img_width > 0 && img_height > 0) {
var rate = (opts.width / img_width < opts.height / img_height) ? opts.width / img_width : opts.height / img_height;
if (rate <= 1) {
if ($.browser.version == "7.0" || $.browser.version == "8.0") imgp.get(0).filters.item("DXImageTransform.Microsoft.AlphaImageLoader").sizingMethod = "scale";
imgp.width(img_width * rate);
imgp.height(img_height * rate);
} else {
imgp.width(img_width);
imgp.height(img_height);
}
var left = (opts.width - imgp.width()) * 0.5;
var top = (opts.height - imgp.height()) * 0.5;
imgp.css({ "margin-left": left, "margin-top": top });
imgp.show();
}
}
_this.change(function() {
if (this.value) {
if (!RegExp(".(" + opts.imgType.join("|") + ")$", "i").test(this.value.toLowerCase())) {
alert("图片类型必须是" + opts.imgType.join(",") + "中的一种");
this.value = "";
return false;
}
imgp.hide();
if ($.browser.msie) {
if ($.browser.version == "6.0") {
var img = $("<img />");
imgp.replaceWith(img);
imgp = img;
var image = new Image();
image.src = 'file:///' + this.value;
imgp.attr('src', image.src);
autoScaling();
}
else {
imgp.css({ filter: "progid:DXImageTransform.Microsoft.AlphaImageLoader(sizingMethod=image)" });
imgp.get(0).filters.item("DXImageTransform.Microsoft.AlphaImageLoader").sizingMethod = "image";
try {
imgp.get(0).filters.item('DXImageTransform.Microsoft.AlphaImageLoader').src = this.value;
} catch (e) {
alert("无效的图片文件!");
return;
}
setTimeout("autoScaling()", 100);
}
}
else {
var img = $("<img />");
imgp.replaceWith(img);
imgp = img;
imgp.attr('src', this.files.item(0).getAsDataURL());
imgp.css({ "vertical-align": "middle" });
setTimeout("autoScaling()", 100);
}
}
});
}
});
})(jQuery);登录后复制
TUSD05J2U是什么类型的二极管?
TUSD05J2U可以用于保护USB2.0接口免受静电放电(ESD)威胁吗?
ESD静电保护二极管TUSD05J2U电压多少?什么封装?结电容是多少?
……

TUSD05J2U是品牌厂家东沃电子推出的一款常用型号ESD静电保护二极管。关于ESD静电保护二极管TUSD05J2U信息,查阅东沃电子“ESD-TUSD05J2U Datasheet”产品规格书可知:
ESD静电保护二极管TUSD05J2U特性
√ 峰值脉冲功率40W(tp= 8/20μs)
√ SOT-143封装
√ 双向
√ 固态硅雪崩技术
√ 低钳位电压
√ 低漏电流
√ 低结电容
ESD静电保护二极管TUSD05J2U参数
>> 峰值脉冲功率 (8/20μs):40W
>> 峰值脉冲电流 (8/20μs):3.5A
>> 反向工作电压:5V
>> 最小击穿电压B:6V
>> 钳位电压:10V
>> 漏电流:0.05uA
>> 结电容:0.35pF
>> 符合IEC 61000−4−2 (Air):±20kV
>> 符合IEC 61000−4−2 (Contact):±15kV
>> 封装:SOT-143
>> 工作温度:−55°C to +125°C
>> 存储温度:−55°C to +125°C

ESD静电保护二极管TUSD05J2U应用
√ USB2.0
√ Ethernet
√ Notebooks, Desktops, and Servers
√ Video Line Protection
关于ESD静电保护二极管TUSD05J2U具体参数详情,详见东沃电子“ESD-TUSD05J2U Datasheet”产品数据手册。有关TUSD05J2U静电保护器件应用方案,欢迎前来探讨。浪涌静电防护方案,找东沃电子,电路保护不迷路!东沃电子推出的ESD静电保护二极管TUSD05J2U现已全面量产、品质稳定、高可靠性、交期迅速、厂家价格、免费样品、免费EMC测试、免费器件选型,欢迎广大新老客户前来咨询,东沃电子销售工程师,1对1为您服务!
插槽的作用:让组件内部的一些 结构 支持 自定义
应用场景 eg:将对话框封装成组件,对话框的内容部分不希望写死,希望能使用的时候自定义。
插槽的基本语法:
1. 组件内需要定制的结构部分 改用 <slot> </slot> 占位
2. 使用组件时,<MyDialog></MyDialog> 标签内部,传入结构替换 slot ( <MyDialog> 你确认要退出系统吗?</MyDialog>、<MyDialog> <div>确认要删除吗?</div> </MyDialog>)
data: {
imgUrls: [
'/img/goodsDetail/goods.png',
'/img/goodsDetail/goods.png',
'/img/goodsDetail/goods.png'
],
indicatorDots: true,
autoplay: true,
interval: 5000,
duration: 1300,
bg: '#C79C77',
Height:"" //这是swiper要动态设置的高度属性
},
imgHeight:function(e){
var winWid = wx.getSystemInfoSync().windowWidth; //获取当前屏幕的宽度
var imgh=e.detail.height;//图片高度
var imgw=e.detail.width;//图片宽度
var swiperH=winWid*imgh/imgw + "px"https://等比设置swiper的高度。 即 屏幕宽度 / swiper高度 = 图片宽度 / 图片高度 ==》swiper高度 = 屏幕宽度 * 图片高度 / 图片宽度
this.setData({
Height:swiperH//设置高度
})
},登录后复制
1、打开“运行”对话框,可通过同时按下 Win + R 键打开。
2、在运行对话框中输入"shell:startup",然后点击“确定”或按下回车键。
这将打开系统的启动文件夹。在该文件夹中创建一个新的快捷方式。
3、右键点击新建的快捷方式,选择“属性”。
在“属性”窗口中,在“目标”字段中输入 VPN 客户端的执行命令。例如,如果您使用的是 Windows 自带的 VPN 客户端,可以输入"rasdial "VPN名称" 用户名 密码",其中 VPN 名称是您要连接的 VPN 的名称。
确认设置后,点击“确定”保存更改。
现在,当您开机启动 Windows 时,系统将会自动运行该快捷方式,从而启动 VPN 客户端并连接指定的 VPN。
apiVersion: apps/v1 # 指定api版本,此值必须在kubectl api-versions中。业务场景一般首选”apps/v1“
kind: Deployment # 指定创建资源的角色/类型
metadata: # 资源的元数据/属性
name: demo # 资源的名字,在同一个namespace中必须唯一
namespace: default # 部署在哪个namespace中。不指定时默认为default命名空间
labels: # 自定义资源的标签
app: demo
version: stable
annotations: # 自定义注释列表
name: string
spec: # 资源规范字段,定义deployment资源需要的参数属性,诸如是否在容器失败时重新启动容器的属性
replicas: 1 # 声明副本数目
revisionHistoryLimit: 3 # 保留历史版本
selector: # 标签选择器
matchLabels: # 匹配标签,需与上面的标签定义的app保持一致
app: demo
version: stable
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxSurge: 1 # 滚动升级时最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 0 # 在更新过程中进入不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
template: # 定义业务模板,如果有多个副本,所有副本的属性会按照模板的相关配置进行匹配
metadata: # 资源的元数据/属性
annotations: # 自定义注解列表
sidecar.istio.io/inject: "false" # 自定义注解名字
labels: # 自定义资源的标签
app: demo # 模板名称必填
version: stable
spec: # 资源规范字段
restartPolicy: Always # Pod的重启策略。[Always | OnFailure | Nerver]
# Always :在任何情况下,只要容器不在运行状态,就自动重启容器。默认
# OnFailure :只在容器异常时才自动容器容器。
# 对于包含多个容器的pod,只有它里面所有的容器都进入异常状态后,pod才会进入Failed状态
# Nerver :从来不重启容器
nodeSelector: # 设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
caas_cluster: work-node
containers: # Pod中容器列表
- name: demo # 容器的名字
image: demo:v1 # 容器使用的镜像地址
imagePullPolicy: IfNotPresent # 每次Pod启动拉取镜像策略
# IfNotPresent :如果本地有就不检查,如果没有就拉取。默认
# Always : 每次都检查
# Never : 每次都不检查(不管本地是否有)
command: [string] # 容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] # 容器的启动命令参数列表
# 如果command和args均没有写,那么用Docker默认的配置
# 如果command写了,但args没有写,那么Docker默认的配置会被忽略而且仅仅执行.yaml文件的command(不带任何参数的)
# 如果command没写,但args写了,那么Docker默认配置的ENTRYPOINT的命令行会被执行,但是调用的参数是.yaml中的args
# 如果如果command和args都写了,那么Docker默认的配置被忽略,使用.yaml的配置
workingDir: string # 容器的工作目录
volumeMounts: # 挂载到容器内部的存储卷配置
- name: string # 引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string # 存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean # 是否为只读模式
- name: string
configMap: # 类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
ports: # 需要暴露的端口库号列表
- name: http # 端口号名称
containerPort: 8080 # 容器开放对外的端口
# hostPort: 8080 # 容器所在主机需要监听的端口号,默认与Container相同
protocol: TCP # 端口协议,支持TCP和UDP,默认TCP
env: # 容器运行前需设置的环境变量列表
- name: string # 环境变量名称
value: string # 环境变量的值
resources: # 资源管理。资源限制和请求的设置
limits: # 资源限制的设置,最大使用
cpu: "1" # CPU,"1"(1核心) = 1000m。将用于docker run --cpu-shares参数
memory: 500Mi # 内存,1G = 1024Mi。将用于docker run --memory参数
requests: # 资源请求的设置。容器运行时,最低资源需求,也就是说最少需要多少资源容器才能正常运行
cpu: 100m
memory: 100Mi
livenessProbe: # pod内部的容器的健康检查的设置。当探测无响应几次后将自动重启该容器
# 检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
httpGet: # 通过httpget检查健康,返回200-399之间,则认为容器正常
path: /healthCheck # URI地址。如果没有心跳检测接口就为/
port: 8089 # 端口
scheme: HTTP # 协议
# host: 127.0.0.1 # 主机地址
# 也可以用这两种方法进行pod内容器的健康检查
# exec: # 在容器内执行任意命令,并检查命令退出状态码,如果状态码为0,则探测成功,否则探测失败容器重启
# command:
# - cat
# - /tmp/health
# 也可以用这种方法
# tcpSocket: # 对Pod内容器健康检查方式设置为tcpSocket方式
# port: number
initialDelaySeconds: 30 # 容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 5 # 对容器健康检查等待响应的超时时间,单位秒,默认1秒
periodSeconds: 30 # 对容器监控检查的定期探测间隔时间设置,单位秒,默认10秒一次
successThreshold: 1 # 成功门槛
failureThreshold: 5 # 失败门槛,连接失败5次,pod杀掉,重启一个新的pod
readinessProbe: # Pod准备服务健康检查设置
httpGet:
path: /healthCheck # 如果没有心跳检测接口就为/
port: 8089
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 5
lifecycle: # 生命周期管理
postStart: # 容器运行之前运行的任务
exec:
command:
- 'sh'
- 'yum upgrade -y'
preStop: # 容器关闭之前运行的任务
exec:
command: ['service httpd stop']
initContainers: # 初始化容器
- command:
- sh
- -c
- sleep 10; mkdir /wls/logs/nacos-0
env:
image: {{ .Values.busyboxImage }}
imagePullPolicy: IfNotPresent
name: init
volumeMounts:
- mountPath: /wls/logs/
name: logs
volumes:
- name: logs
hostPath:
path: {{ .Values.nfsPath }}/logs
volumes: # 在该pod上定义共享存储卷列表
- name: string # 共享存储卷名称 (volumes类型有很多种)
emptyDir: {} # 类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
- name: string
hostPath: # 类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string # Pod所在宿主机的目录,将被用于同期中mount的目录
- name: string
secret: # 类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
imagePullSecrets: # 镜像仓库拉取镜像时使用的密钥,以key:secretkey格式指定
- name: harbor-certification
hostNetwork: false # 是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
terminationGracePeriodSeconds: 30 # 优雅关闭时间,这个时间内优雅关闭未结束,k8s 强制 kill
dnsPolicy: ClusterFirst # 设置Pod的DNS的策略。默认ClusterFirst
# 支持的策略:[Default | ClusterFirst | ClusterFirstWithHostNet | None]
# Default : Pod继承所在宿主机的设置,也就是直接将宿主机的/etc/resolv.conf内容挂载到容器中
# ClusterFirst : 默认的配置,所有请求会优先在集群所在域查询,如果没有才会转发到上游DNS
# ClusterFirstWithHostNet : 和ClusterFirst一样,不过是Pod运行在hostNetwork:true的情况下强制指定的
# None : 1.9版本引入的一个新值,这个配置忽略所有配置,以Pod的dnsConfig字段为准
affinity: # 亲和性调试
nodeAffinity: # 节点亲和力
requiredDuringSchedulingIgnoredDuringExecution: # pod 必须部署到满足条件的节点上
nodeSelectorTerms: # 节点满足任何一个条件就可以
- matchExpressions: # 有多个选项时,则只有同时满足这些逻辑选项的节点才能运行 pod
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
tolerations: # 污点容忍度
- operator: "Equal" # 匹配类型。支持[Exists | Equal(默认值)]。Exists为容忍所有污点
key: "key1"
value: "value1"
effect: "NoSchedule" # 污点类型:[NoSchedule | PreferNoSchedule | NoExecute]
# NoSchedule :不会被调度
# PreferNoSchedule:尽量不调度
# NoExecute:驱逐节点
在Nginx.conf配置中,添加
location ~ [^/].php(/|$){
fastcgi_pass unix:/tmp/php-cgi.sock;
fastcgi_index index.php;
fastcgi_split_path_info ^(.+.php)(.*)$;
fastcgi_param PATH_INFO $fastcgi_path_info;
include fastcgi.conf;
include pathinfo.conf;
}
在Nginx低版本中,是不支持PATHINFO的,但是可以通过在Nginx.conf中配置转发规则实现。
location / { if (!-e $request_filename) {
rewrite ^(.*)$ /index.php?s=/$1 last;
break;
}
}
一个完整示例,请根据自己服务器加以修改
server {
listen 80;
server_name www.dolphinphp.com *.dolphinphp.com;
root "/home/www/wwwroot/dolphinphp";
location / { index index.html index.htm index.php; #主要是这一段一定要确保存在
if (!-e $request_filename) {
rewrite ^(.*)$ /index.php?s=$1 last; break;
} #结束
#autoindex on;
}
location ~ .php(.*)$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_split_path_info ^(.+.php)(.*)$;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
fastcgi_param PATH_TRANSLATED $document_root$fastcgi_path_info;
include fastcgi_params;
}
}
pathinfo是什么:pathinfo不是nginx的功能,pathinfo是php的功能。
php中有两个pathinfo,一个是环境变量$_SERVER['PATH_INFO'];另一个是pathinfo函数,pathinfo() 函数以数组的形式返回文件路径的信息;。
nginx能做的只是对$_SERVER['PATH_INFO]值的设置。
php中的pathinfo()
pathinfo()函数可以对输入的路径进行判断,以数组的形式返回文件路径的信息,数组包含以下元素。
● [dirname] 路径的目录
● [basename] 带后缀 文件名
● [extension] 文件后缀
● [filename] 不带后缀文件名(需php5.2以上版本)
例如
[php]
<?php
print_r(pathinfo("/nginx/test.txt"));
?>
[/php]
输出
PHP
1234567 Array( [dirname] => /nginx [basename] => test.txt [extension] => txt [filename] => test)
php中的$_SERVER['PATH_INFO']
PHP中的全局变量$_SERVER['PATH_INFO'],PATH_INFO是一个CGI 1.1的标准,经常用来做为传参载体。
被很多系统用来优化url路径格式,最著名的如THINKPHP框架。
对于下面这个网址:
http://www.test.cn/index.php/test/my.html?c=index&m=search
我们可以得到 $_SERVER['PATH_INFO'] = ‘/test/my.html’,而此时 $_SERVER['QUERY_STRING'] = 'c=index&m=search';
如果不借助高级方法,php中http://www.test.com/index.php?type=search 这样的URL很常见,大多数人可能会觉得不太美观而且对于搜索引擎也是非常不友好的(实际上有没有影响未知),因为现在的搜索引擎已经很智能了,可以收入带参数的后缀网页,不过大家出于整洁的考虑还是想希望能够重写URL登录后复制
操作系统分为抢占式内核和非抢占式内核,通常RTOS都是抢占式内核。
下面就来讲讲抢占式内核和非抢占式内核的内容。
非抢占式内核
非抢占式内核要求每个任务(线程)都做一些事情来明确放弃对 CPU 的控制,为了保持多任务并发的错觉,必须要有这一步操作。
非抢占式调度也称为协作多任务,任务相互协作以共享 CPU,异步事件仍然由 ISR 处理。ISR 可以使更高优先级的任务准备好运行,但 ISR 总是返回到被中断的任务。只有当当前任务放弃 CPU 时,新的更高优先级任务才会获得对 CPU 的控制。
非抢占式内核的优点之一是中断延迟更低,在任务级别,非抢占内核也可以使用不可重入函数。每个任务都可以使用不可重入函数,而不必担心被另一个任务破坏。这是因为每个任务都可以在放弃 CPU 之前运行到完成。但是,不应允许不可重入函数放弃对 CPU 的控制。
使用非抢占式内核的任务级响应可能比前台/后台系统低得多,因为任务级响应现在由最长任务的时间给出。
非抢占式内核的另一个优点是较少需要通过使用信号量来保护共享数据。每个任务都拥有 CPU,你不必担心任务会被抢占。当然,这不是绝对的,在某些情况下,仍应使用信号量。共享 I/O 设备可能仍需要使用互斥信号量;例如,任务可能仍需要对打印机的独占访问。
非抢占式内核在执行用户进程的过程中接收到中断的处理流程入下:
(1) 任务正在执行但被中断。
(2) 如果中断被使能,CPU 向量(跳转)到 ISR。
(3) ISR 处理事件并使更高优先级的任务准备好运行。
(4) ISR完成后,执行返回指令,CPU返回被中断的任务。
(5) 任务代码在中断指令之后的指令处恢复。
(6) 当任务代码完成时,它调用内核提供的服务,将 CPU 交给另一个任务。
(7) 内核看到更高优先级的任务已经准备好运行,因此,内核执行上下文切换,以便它可以运行(即执行)更高优先级的任务来处理由 ISR 发出信号的事件。
非抢占式内核最重要的缺点是响应性:已准备好运行的较高优先级任务可能需要等待很长时间才能运行,因为当前任务应该及时放弃CPU使用权。
与前台/后台系统中的后台执行一样,非抢占式内核中的任务级响应时间是不确定的;你永远不知道最高优先级的任务何时才能获得 CPU 的控制权。这个操作由你的应用程序来决定怎么时候放弃对 CPU 的控制。
总而言之,非抢占式内核允许每个任务运行,直到它自愿放弃对 CPU 的控制。中断抢占任务,ISR 完成后,ISR 返回到被中断的任务。任务级响应比前台/后台系统要好得多,但仍然是不确定的,因此,很少有商业内核是非抢占式的。
抢占式内核
μC/OS、RTT等大多数实时内核都是抢占式的,准备运行的最高优先级任务始终被赋予 CPU 控制权。
当一个任务使更高优先级的任务准备好运行时,当前任务被抢占(挂起)并且更高优先级的任务立即获得 CPU 的控制权。
如果 ISR 使更高优先级的任务准备就绪,当 ISR 完成时,被中断的任务被挂起并恢复新的更高优先级任务。

可抢占式内核的处理流程如下:
(1) 任务正在执行但被中断。
(2) 如果中断被使能,CPU 向量(跳转)到 ISR。
(3) ISR 处理事件并使更高优先级的任务准备好运行。ISR 完成后,调用内核提供的服务(即调用内核提供的函数)。
(4) & (5) 该函数知道一个更重要的任务已经准备好运行,因此内核将执行上下文切换并执行更重要的代码而不是返回到被中断的任务任务。当更重要的任务完成时,内核提供的另一个函数被调用,让任务进入休眠状态,等待事件(即 ISR)发生。
(6) & (7) 然后内核“看到”需要执行一个较低优先级的任务,并完成另一个上下文切换以恢复被中断任务的执行。
使用抢占式内核,最高优先级任务的执行是确定性的;你可以确定它何时可以控制 CPU。因此,通过使用抢占式内核可以最大限度地减少任务级响应时间。
使用抢占式内核的应用程序代码不应使用不可重入函数,除非通过使用互斥信号量确保对这些函数的独占访问,因为低优先级和高优先级任务都可以使用公共函数。如果较高优先级的任务抢占正在使用该功能的较低优先级的任务,则可能会发生数据损坏。
总而言之,抢占式内核始终执行准备运行的最高优先级任务。中断抢占任务,完成 ISR 后,内核将继续执行准备运行的最高优先级任务(而不是被中断的任务)。任务级别的响应是最佳的和确定性的,当系统响应性很重要时,建议使用抢占式内核。
抢占和时间片
在linux内核中,上下文的切换有两种方式:第一种是进程主动让出CPU,这样的操作成为“让步”。第二种是由内核调度程序决定进程运行时间,在在运行时间结束(如时间片耗尽)或者需要切换高优先级进程时强制挂起进程,这样的操作叫“抢占”。
抢占是我一直误解的概念,我一直以为抢占是一个进程强制切换到另一进程。最近才知道,执行抢占的是内核,并不是进程。
抢占分为两种:用户抢占和内核抢占。下面将一一介绍。
用户抢占
如果只是靠每个进程主动放弃CPU,这是相当不明智的做法,所以,内核使用need_resched标志(在每个进程对应的thread_info结构体内)来表示进程是否需要被调度。当一个进程的时间片耗尽,或者有更高优先级的进程进入可执行队列,当前运行的进程对应的need_reched标志会被设置(该标志位应该是由内核的调度程序来负责的)。
在内核即将要返回用户空间的时候,如果need_resched标志被设置,内核会在继续执行原来的进程之前调用调度程序,此时就会发生用户抢占。
要注意,用户抢占是发生在即将返回用户空间前,内核调用调度程序,重新选择一个更加合适的进程来运行(如高优先级),当然也可以是原来的程序。
总的来说,在以下情况下会发生用户抢占:
1、从系统调用返回用户空间。
2、从中断处理程序返回用户空间。
内核返回用户空间后,每个进程有独立的4G虚拟空间,这时的进程调度并不会出现内核资源的争夺。
内核抢占
内核抢占是2.6内核的新特征,在之前的内核中,调度程序是不能调度正在运行在内核中的进程,即使时间片已经用完,只有在进程返回用户空间或者阻塞,才能进行进程的调度。
在2.6内核中,内核提供了为高优先级进程抢占正在内核运行的进程的机会。但是,对于多个同时运行的进程,内核空间的资源的共享的。所以,内核在抢占并且调度进程的时候,必须要保证调度是安全的。所谓的安全,就是不会因为新进程的调度导致一些共享资源的错乱,这就是下一节要讨论的内核同步。
内核进程可以调用函数来禁止内核抢占,在禁止这段时间内,抢占是不允许的,这样也是保护内核共享资源的一种方法。
所以,内核抢占发生在以下时候:
1、当终端处理程序将要执行完毕,返回内核空间之前。
2、执行在可以抢占的代码的时候。
3、内核进程让出CPU后,如阻塞。
用户抢占在可抢占内核和不可抢占内核中都会发生,而内核抢占只发生在可抢占内核系统中。
1、当网络包到达一个网关的时候,可以通过路由表得到下一个网关的 IP 地址,直接通过 IP 地址找就可以了,为什么还要通过本地的 MAC 地址呢?
答:IP报文端到端的传输过程中,在没有NAT情况下,目的地址和源地址是不变的,但每通过一个网关,源MAC和目的MAC一直在变。所谓的下一跳,看起来是 IP 地址,其实是要通过 ARP 得到 MAC 地址,将下一跳的 MAC 地址放在目标 MAC 地址里面。
2、MAC 地址可以修改吗?
答:MAC 本来设计为唯一性的,但是后来设备越来越多,而且还有虚拟化的设备和网卡,有很多工具可以修改,就很难保证不冲突了。但是至少应该保持一个局域网内是唯一的。
3、TCP 重试有没有可能导致重复下单?
答:因为 TCP 层收到了重复包之后,TCP 层自己会进行去重,发给应用层、HTTP 层。还是一个唯一的下单请求,所以不会重复下单。
那什么时候会导致重复下单呢?因为网络原因或者服务端错误,导致 TCP 连接断了,这样会重新发送应用层的请求,也即 HTTP 的请求会重新发送一遍。
如果服务端设计的是无状态的,它记不住上一次已经发送了一次请求。如果处理不好,就会导致重复下单,这就需要服务端除了实现无状态,还需要根据传过来的订单号实现幂等,同一个订单只处理一次。
还会有的现象是请求被黑客拦截,发送多次,这在 HTTPS 层可以有很多种机制,例如通过 Timestamp 和 Nonce 随机数联合起来,然后做一个不可逆的签名来保证。
4、IP 地址和 MAC 地址的关系?
答:IP 是有远程定位功能的,MAC 是没有远程定位功能的,只能通过本地 ARP 的方式找到。
5、如果最后一跳的时候,IP 改变了怎么办?
答:对于 IP 层来讲,当包到达最后一跳的时候,原来的 IP 不存在了。比如网线拔掉了,或者服务器直接宕机了,则 ARP 就找不到了,所以这个包就会发送失败了。
对于 IP 层的工作就结束了。但是 IP 层之上还有 TCP 层,TCP 会重试的,包还是会重新发送,但是如果服务器没有启动起来,超过一定的次数,最终放弃。
6、TCP 层报平安,怎么确认浏览器收到呢?
答:TCP 报平安,只能保证 TCP 层能够收到,不保证浏览器能够收到。但是可以想象,如果浏览器是你写的一个程序,你也是通过 socket 编程写的,你是通过 socket,建立一个 TCP 的连接,然后从这个连接里面读取数据,读取的数据就是 TCP 层确认收到的。
7、ARP 协议属于哪一层?
答:ARP 属于哪个层,一直是有争议的。比如《TCP/IP 详解》把它放在了二层和三层之间,但是既然是协议,只要大家都遵守相同的格式、流程就可以了,在实际应用的时候,不会有歧义的。
8、 层级之间真实的调用方式是什么样的?
答:其实下层的协议知道上层协议的,因为在每一层的包头里面,都会有上一层是哪个协议的标识,所以不是一个回调函数,每一层的处理函数都会在操作系统启动的时候,注册到内核的一个数据结构里面,但是到某一层的时候,是通过判断到底是哪一层的哪一个协议,然后去找相应的处理函数去调用。
1、如果需要创建全局 DBLink,则需要先确定用户有创建 dblink 的权限:
select * from user_sys_privs where privilege like upper('%DATABASE LINK%');
如果没有,则需要使用 sysdba 角色给用户赋权:
grant create public database link to dbusername;
2、使用该用户登录 PL/SQL,使用命令:
-- 第一种方法:要求数据库服务器 A 上 tnsnames.ora 中有 数据库 B 的映射
create database link 数据库链接名 connect to 用户名 identified by 密码 using '本地配置的数据的实例名';
采用图形配置界面则如下所示:
-- 第二种方法:直接配置
-- 如果创建全局 dblink,必须使用 systm 或 sys 用户,在 database 前加 public。
create /* public */ database link dblink1
connect to dbusername identified by dbpassword
using '(DESCRIPTION =(ADDRESS_LIST =(ADDRESS =(PROTOCOL = TCP)(HOST = 192.168.0.1)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = orcl)))';
-- 数据库参数 global_name=true 时要求数据库链接名称跟远端数据库名称一样。数据库全局名称可以用以下命令查出
-- select * from global_name;
3、查询数据:
-- 查询、删除和插入数据和操作本地的数据库是一样的,只不过表名需要写成“表名@dblink服务器”而已。
select xxx FROM 表名@数据库链接名;
4、删除 DBLink
drop /* public */ database link dblink1;
5、创建和删除同义词
create or replace synonym 同义词名 for 表名;
create or replace synonym 同义词名 for 用户.表名;
create or replace synonym 同义词名 for 表名@数据库链接名;
drop synonym 同义词名;
6、创建和删除视图
create or replace view 视图名 as (select 字段 from 用户.表名@dblink1);
drop view 视图名;
7、注意:
创建 DBLink 很简单,但是在使用中后台却出现锁,查看这个锁的方法可以去 console 中看到或者查询数据库。每次使用dblink查询的时候,均会与远程数据库创建一个连接,dblink 应该不会自动释放这个连接,如果是大量使用 dblink 查询,会造成 web 项目的连接数不够,导致系统无法正常运行,导致系统无正常运行。
8、查看db_link
select * from ALL_DB_LINKS;
9、创建DBLINK实例
--创建DBLINK
create /*public*/ database link DBLINK名称
connect to 数据库账号 identified by 数据库密码
using '(description =(address_list =(address =(protocol = tcp)(host = 10.10.2.12)(port = 1521)))(connect_data =(SID = orcl)))'; /*首次创建*/
在当今网络环境中,为网站启用SSL加密是确保数据传输安全和用户信任的重要步骤。虽然许多SSL证书需要付费购买,但幸运的是,现在有一些选择免费获得SSL证书的选项。本文将向您介绍如何申请免费SSL证书,为您的网站提供安全性保护。
.jpg")
首先,了解不同的免费SSL证书提供商。目前,有几家知名的机构提供可靠的免费SSL证书服务,如Let's Encrypt、JoySSL等。这些服务提供商通过自动化流程,使您能够轻松且快速地获取和安装SSL证书。
其次,选择合适的免费SSL证书提供商。请根据您的需求和技术背景选择最适合您的提供商。供应商通常提供有关设置和使用他们服务的详细文档和指南。阅读相关文档,确保您理解其流程并满足其要求。
接下来,按照提供商的指导进行证书申请和配置。免费SSL证书的申请过程通常基于域名验证而简化。您可能需要添加一条特定的DNS记录,或在您的服务器上上传和验证特定的文件。根据提供商的要求,按照步骤执行,并确保正确配置您的网站服务器。
.jpg")
在完成证书申请和配置后,您将获得免费SSL证书。这时,您可以下载证书文件或通过提供商的工具自动安装证书到您的服务器。如果您对安装过程不熟悉,可以参考提供商的文档或寻求相关技术支持。
最后,在证书安装完成后,确保将您的网站从HTTP切换为HTTPS协议。这涉及到将网站链接中的URL更改为使用加密的443端口,并确保所有页面和资源都通过HTTPS提供。这样做可以确保所有的数据传输都受到SSL加密保护,并在浏览器地址栏中显示安全锁形图标。
总结起来,获取免费SSL证书可以为您的网站提供必要的安全性保护。首先选择合适的免费SSL证书提供商,然后按照他们的指导进行申请和配置。完成证书安装后,务必切换网站至HTTPS协议。通过这些简单的步骤,您可以为您的网站提供额外的安全保障,并增强用户对网站的信任和满意度。记住,保护用户数据是网络世界中至关重要的责任,而免费SSL证书为您提供了实现这一目标的机会。
点击申请免费证书保护你的网站
https://www.joyssl.com/certificate/select/free.html?nid=5
//获取来自搜索引擎入站时的关键词
function get_keyword($url,$kw_start)
{
$start=stripos($url,$kw_start);
$url=substr($url,$start+strlen($kw_start));
$start=stripos($url,'&');
if ($start>0)
{
$start=stripos($url,'&');
$s_s_keyword=substr($url,0,$start);
}
else
{
$s_s_keyword=substr($url,0);
}
return $s_s_keyword;
}
$url=isset($_SERVER['HTTP_REFERER'])?$_SERVER['HTTP_REFERER']:'';//获取入站url。
$search_1="google.com"; //q= utf8
$search_2="baidu.com"; //wd= gbk
$search_3="yahoo.cn"; //q= utf8
$search_4="sogou.com"; //query= gbk
$search_5="soso.com"; //w= gbk
$search_6="bing.com"; //q= utf8
$search_7="youdao.com"; //q= utf8
$google=preg_match("/b{$search_1}b/",$url);//记录匹配情况,用于入站判断。
$baidu=preg_match("/b{$search_2}b/",$url);
$yahoo=preg_match("/b{$search_3}b/",$url);
$sogou=preg_match("/b{$search_4}b/",$url);
$soso=preg_match("/b{$search_5}b/",$url);
$bing=preg_match("/b{$search_6}b/",$url);
$youdao=preg_match("/b{$search_7}b/",$url);
$s_s_keyword="";
$bul=$_SERVER['HTTP_REFERER'];
//获取没参数域名
preg_match('@^(?:http://)?([^/]+)@i',$bul,$matches);
$burl=$matches[1];
//匹配域名设置
$curl="www.netxu.com";
if($burl!=$curl){
if ($google)
{//来自google
$s_s_keyword=get_keyword($url,'q=');//关键词前的字符为"q="。
$s_s_keyword=urldecode($s_s_keyword);
$urlname="谷歌:";
$_SESSION["urlname"]=$urlname;
$_SESSION["s_s_keyword"]=$s_s_keyword;
//$s_s_keyword=iconv("GBK","UTF-8",$s_s_keyword);//引擎为gbk
}
else if($baidu)
{//来自百度
$s_s_keyword=get_keyword($url,'wd=');//关键词前的字符为"wd="。
$s_s_keyword=urldecode($s_s_keyword);
$s_s_keyword=iconv("GBK","UTF-8",$s_s_keyword);//引擎为gbk
$urlname="百度:";
$_SESSION["urlname"]=$urlname;
$_SESSION["s_s_keyword"]=$s_s_keyword;
}
else if($yahoo)
{//来自雅虎
$s_s_keyword=get_keyword($url,'q=');//关键词前的字符为"q="。
$s_s_keyword=urldecode($s_s_keyword);
//$s_s_keyword=iconv("GBK","UTF-8",$s_s_keyword);//引擎为gbk
$urlname="雅虎:";
$_SESSION["urlname"]=$urlname;
$_SESSION["s_s_keyword"]=$s_s_keyword;
}
else if($sogou)
{//来自搜狗
$s_s_keyword=get_keyword($url,'query=');//关键词前的字符为"query="。
$s_s_keyword=urldecode($s_s_keyword);
$s_s_keyword=iconv("GBK","UTF-8",$s_s_keyword);//引擎为gbk
$urlname="搜狗:";
$_SESSION["urlname"]=$urlname;
$_SESSION["s_s_keyword"]=$s_s_keyword;
}
else if($soso)
{//来自搜搜
$s_s_keyword=get_keyword($url,'w=');//关键词前的字符为"w="。
$s_s_keyword=urldecode($s_s_keyword);
$s_s_keyword=iconv("GBK","UTF-8",$s_s_keyword);//引擎为gbk
$urlname="搜搜:";
$_SESSION["urlname"]=$urlname;
$_SESSION["s_s_keyword"]=$s_s_keyword;
}
else if($bing)
{//来自必应
$s_s_keyword=get_keyword($url,'q=');//关键词前的字符为"q="。
$s_s_keyword=urldecode($s_s_keyword);
//$s_s_keyword=iconv("GBK","UTF-8",$s_s_keyword);//引擎为gbk
$urlname="必应:";
$_SESSION["urlname"]=$urlname;
$_SESSION["s_s_keyword"]=$s_s_keyword;
}
else if($youdao)
{//来自有道
$s_s_keyword=get_keyword($url,'q=');//关键词前的字符为"q="。
$s_s_keyword=urldecode($s_s_keyword);
//$s_s_keyword=iconv("GBK","UTF-8",$s_s_keyword);//引擎为gbk
$urlname="有道:";
$_SESSION["urlname"]=$urlname;
$_SESSION["s_s_keyword"]=$s_s_keyword;
}
else{
$urlname=$burl;
$s_s_keyword="";
$_SESSION["urlname"]=$urlname;
$_SESSION["s_s_keyword"]=$s_s_keyword;
}
$s_urlname=$urlname;
$s_urlkey=$s_s_keyword;
}
else{
$s_urlname=$_SESSION["urlname"];
$s_urlkey=$_SESSION["s_s_keyword"];
}登录后复制
机柜的一些基本知识点
服务器机柜和网络机柜之间的区别服务器机柜是在IDC机房内的统称,一般是安装服务器、UPS或者显示器等一系列19标准设备的专用型的机柜,组合安装插件、面板、器件或者电子元件等等,构成一个统一的整体的安装箱,服务器机柜为电子设备的正常工作提供相适应的环境和安全防护能力。
网络机柜一般是用过安装的,对面板、插箱、插件、器件或者电子元件、机械零件进行安装等等这样让其构成一个统一的整体性的安装箱,根据目前的类型来看,容量一般都是在2V到42V的范围内。
机柜类型不同具有的功能也不一样,所以在选择的时候要根据自己的业务需求,选择不同的机柜
生成根 CA 的私钥
openssl genrsa -out rootCA.key 2048
使用私钥生成根 CA 的证书
openssl req -x509 -new -nodes -key rootCA.key -sha256 -days 1024 -out rootCA.crt
为 10.12.0.2 生成私钥和证书请求文件(CSR)
生成 10.12.0.2 的私钥
openssl genrsa -out 10.12.0.2.key 2048
使用私钥生成证书请求文件
openssl req -new -key 10.12.0.2.key -out 10.12.0.2.csr
创建证书扩展文件
为了确保为 10.12.0.2 签名的证书能够用作服务器身份验证,需要为它创建一个扩展文件。创建一个名为 v3.ext 的文件,并添加以下内容:
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
subjectAltName = @alt_names
[alt_names]
这里 IP 替换成 DNS 就可以签名域名了
IP.1 = 10.12.0.2
使用根 CA 的证书为 10.12.0.2 签名证书
openssl x509 -req -in 10.12.0.2.csr -CA rootCA.crt -CAkey rootCA.key -CAcreateserial -out 10.12.0.2.crt -days 500 -sha256 -extfile v3.ext
此时文件夹内应该有以下文件:
rootCA.key - 根 CA 的私钥。
rootCA.crt - 根 CA 的证书。
10.12.0.2.key - 10.12.0.2 的私钥。
10.12.0.2.csr - 10.12.0.2 的证书请求文件。
10.12.0.2.crt - 由根 CA 签名的 10.12.0.2 的证书。
来源:https://www.cnblogs.com/aobaxu/p/17754721.html#生成
前言
大一小学期,我迎来了人生中的第一次实训,“宅急送”订餐管理系统是一个非常好的检验该阶段所学知识的实训项目,本篇文章我会围绕这一实训项目以及在实训中遇到的问题和收获与大家进行探讨,内容包括流程图、函数调用关系图、算法描述以及代码实现等等,可供大家进行参考,希望大家多多点赞收藏支持🔥
1.详细设计
1.1上班1.1.1算法描述
首先对套餐顺序表进行初始化,然后从文件中读取套餐信息,并将其存储到套餐顺序表中,提示用户套餐信息读取完成,而后对订单信息队列进行初始化,从文件中读取订单信息,并将其存储到订单信息队列中,同样提示用户订单信息读取完成,最后则是对图进行初始化,从文件中分别读取地点信息和地点间距离信息,并将其存储到图中,提示地址和距离信息读取完成,而后等待用户进行下一步操作。
1.1.2流程图

1.2订单管理1.2.1算法描述
1.接收订单
从用户输入获取订单信息,包括订餐人姓名、订单号和目的地等,并判断输入的订单信息是否合法,然后创建一个临时变量用来存储订单信息,最后将该临时变量入队。
2.根据订单号查询订单
从用户输入获取订餐人姓名,遍历队列中的每个节点,直到找到订单号匹配的节点为止,如果找到匹配的订单号,返回该节点的指针,否则返回空指针。
3.根据订餐人姓名查询订单
从用户输入获取订餐人姓名,遍历队列中的每个节点,直到找到订餐人姓名匹配的节点为止,如果找到匹配的订餐人姓名,返回 true,否则返回 false。
4.根据订单号查询并修改订单
调用订单号查询函数,获取该订单地址,根据用户输入的信息修改相应的订单属性,同样在其中穿插判断订单信息的合法性,最后更新订单信息。
5.根据订单号查询并取消订单
从用户输入获取订单号,调用订单号查询函数,获取该订单地址,判断该订单是否已派送,将该订单状态信息更新为取消。1.2.2流程图

1.3派送订单1.3.1算法描述
1.遍历未派送订单
以队列的size大小界定循环次数,遍历该队列,当派送状态为未派送时输出订单信息即可。
2.逐个派送
首先找到订单队列中最靠近队首的未派送订单,然后利用弗洛伊德算法计算最短路径并生成最短距离矩阵D得到最短距离,和最短路径矩阵Path,利用PrintShortedPath函数输出最短路径,设骑手速度为30,计算出送达时间并输出,将订单状态修改为已派送,最后提示用户派送成功。1.3.2流程图

1.4数据维护1.4.1算法描述
1.添加套餐
调用函数 CheckSetList检测套餐列表容量是否已满,如果已满则扩容,通过用户输入获取套餐信息,包括套餐编号、套餐名称、套餐描述、套餐价格和套餐状态,将获取的套餐信息依次存储到顺序表的末尾,增加顺序表长度,提示用户添加成功。
2.删除套餐
通过用户输入获取要删除的套餐的编号,遍历顺序表中的每个套餐,直到找到与输入的编号匹配的套餐为止,如果找到匹配的套餐,询问用户是否确定删除该套餐,并根据用户的选择进行相应操作,如果用户确定删除套餐,则将该套餐从顺序表中删除,并提示用户删除成功。
3.根据套餐编号修改套餐信息
通过用户输入获取要修改的套餐的编号,然后遍历顺序表中的每个套餐,直到找到与输入的编号匹配的套餐为止,如果找到匹配的套餐,通过用户输入修改套餐的名称、描述、价格和状态,提示用户修改成功,如果未找到匹配的套餐,提示用户修改失败并声明原因。
4.根据套餐名称修改套餐信息
通过用户输入获取要修改的套餐的名称,然后遍历顺序表中的每个套餐,直到找到与输入的名称匹配的套餐为止,如果找到匹配的套餐,通过用户输入修改套餐的名称、描述、价格和状态,提示用户修改成功,如果未找到匹配的套餐,提示用户修改失败并声明原因。
5.恢复套餐信息
首先初始化顺序表,然后调用函数 LoadSetList加载文件中的套餐信息,并将其存储到顺序表中,提示用户恢复套餐成功,之后调用函数 TraverseSet 遍历并打印顺序表中的套餐信息。1.4.2流程图

1.5统计1.5.1算法描述
1.当天统计
遍历订单队列,获取订单的时间信息,判断订单的时间是否为当天,如果是则进行统计,统计未派送数量、已派送数量、总套餐数和总金额,输出统计结果。
2.当月统计
遍历订单队列,获取订单的时间信息,判断订单的月份是否为当月,如果是则进行统计,遍历套餐列表,匹配订单的套餐编号,统计未派送数量、已派送数量、套餐数和总金额,最终输出统计结果。
3.当周统计
遍历订单队列,获取订单的时间信息,判断订单的日期是否在本周范围内,如果是则进行统计,遍历套餐列表,匹配订单的套餐编号,统计未派送数量、已派送数量、套餐数和总金额,最终输出统计结果。
4.按地址统计
遍历订单队列,获取订单的地址信息,遍历地址数组,匹配订单的地址,遍历套餐列表,匹配订单的套餐编号,统计订单数量和总金额,最终输出统计结果。1.5.2流程图

1.6下班1.6.1算法描述
将顺序表中的内容存储到文本文件中,然后销毁为顺序表开辟的动态内存空间,将队列中的内容存储到文本文件中,销毁为队列开辟的动态内存空间,提示用户信息储存完毕,等待用户退出程序。1.6.2流程图

2.代码实现
=========================================================================
GITEE相关代码:🌟fanfei_c的仓库🌟
=========================================================================
3.函数调用关系
该图采用Mindmaster(亿图脑图)创作完成。

4.遇到的问题
1.fread与fwrite只能读取和写入二进制文件,不能读取文本文件(造成乱码的原因)
在实训初期,文件读取操作是比较棘手的难题,由于对于文件操作函数使用的不熟练,常常陷入读取文本出现乱码的问题,经过仔细研究文件操作函数,最终成功解决了这一问题。
为了以后方便学习,在套餐信息的读取和写入中我使用了二进制读取写入方式,而订单信息和图的信息我才用了文本读取写入方式。
二进制读取举例:
void Save_Set(SetList* s)//存储套餐信息文件
{
FILE* pf = fopen("Menu_Info.txt", "w");//保存套餐信息到文件
if (pf == NULL)
{
perror("fopen Menu_Info");
return;
}
int i = 0;
for (i = 0; i < s->length; i++)
{
fwrite(&s->setmea[i], sizeof(Meal), 1, pf);
}
}
void LoadSetList(SetList* s)//加载套餐信息文件
{
FILE* pf = fopen("Menu_Info.txt", "rb");
if (pf == NULL)
{
perror("LoadSetList");
return;
}
Meal tmp = { 0 };
while (fread(&tmp, sizeof(Meal), 1, pf))
{
CheckSetList(s);
s->setmea[s->length] = tmp;
s->length++;
}
printf("Menu_Info.txt加载成功!
");
fclose(pf);
return;
}
文本读取举例:
void Save_Book(Que* pq)// 存储订单信息文件
{
FILE* pf = fopen("Book_Info.txt", "w");
if (pf == NULL)
{
perror("fopen Book_Info");
return;
}
while (!QueueEmpty(pq))
{
Order_Info tmp = { 0 };
tmp = QueueFront(pq);
fprintf(pf, "%s ", tmp.Order_Num);
fprintf(pf, "%s ", tmp.Menu_Num);
fprintf(pf, "%d ", tmp.Num);
fprintf(pf, "%s ", tmp.Orderer_Name);
fprintf(pf, "%s ", tmp.Order_Tele);
fprintf(pf, "%s ", tmp.Address);
fprintf(pf, "%s ", tmp.Order_Time);
fprintf(pf, "%d ", tmp.Deliver_State);
fprintf(pf, "%d
", tmp.timestamp);
QueuePop(pq);
}
}
void LoadBook(Que* pq)//加载订单信息
{
FILE* pf = fopen("Book_Info.txt", "r");
if (pf == NULL)
{
perror("LoadBook");
return;
}
char line[150];
while (fgets(line, sizeof(line), pf)) // 逐行读取文件内容
{
Order_Info tmp = { 0 };
sscanf(line, "%s %s %d %s %s %s %s %d %d", tmp.Order_Num, tmp.Menu_Num, &tmp.Num,
tmp.Orderer_Name,tmp.Order_Tele,tmp.Address,tmp.Order_Time,&tmp.Deliver_State,&tmp.timestamp); // 解析行中的数据
QueuePush(pq, tmp);
}
printf("Book_Info.txt加载成功!
");
fclose(pf);
return;
}
大家如果对文件操作相关知识有所欠缺,可以浏览下我之前写的博客->【C语言】文件操作🍎
2.使用feof()函数判断文件结束是不合适的
在处理文件指针时,判断文件是否已经到达末尾的一种常见方法是使用feof()函数(feof()函数会在文件指针到达文件末尾时返回非零值,否则返回0)
因此,在循环中使用while (!feof(pf))来判断文件是否到达末尾,看起来似乎是一种合理的做法。
然而,实际上在循环中使用while (!feof(pf))可能会导致最后一次循环读取无效数据的问题。这是因为feof()函数的返回值只有在文件指针尝试读取文件末尾之后才会为真。也就是说,在feof()函数返回真之前,文件指针可能已经读取了文件末尾之后的数据,但循环仍然会继续执行一次。因此,在最后一次循环中,会读取到文件末尾之后的无效数据。
为了避免这个问题,可以使用替代方案来处理文件指针。一种常见的替代方案是使用fgets()函数来逐行读取文件内容,并在循环中检查fgets()函数的返回值是否为NULL,以判断是否到达文件末尾。如果fgets()函数返回NULL,说明文件已经到达末尾,循环应该结束。这种方式可以确保最后一次循环不会读取无效数据。
使用fgets()函数逐行读取文件内容,当fgets()函数返回NULL时,循环结束。这样确保了最后一次循环不会读取无效数据。
while (fgets(line, sizeof(line), pf))
{
// 处理每一行的数据
// ...
}
总结起来,建议避免在循环中使用feof()函数来判断文件是否到达末尾,而是使用替代方案如fgets()函数来处理文件指针,以确保最后一次循环不会读取无效数据。
下面是feof函数的正确使用方法:
int main()
{
FILE* file = fopen("data.txt", "r");
if (file == NULL)
{
perror("fopen");
return 1;
}
char buffer[100];
while (fgets(buffer, sizeof(buffer), file) != NULL)
{
printf("%s", buffer);
}
if (feof(file))//将feof的判断放在循环末尾
{
printf("Reached end of file.
");
}
else
{
printf("Error occurred while reading file.
");
}
fclose(file);
return 0;
}
由于当fgets(buffer, sizeof(buffer), file)函数的返回值为NULL时,说明文件已经到达末尾,此时循环结束,再利用feof(file)做判断,如果此时feof(file)的返回值为真,证明文件确实到达了末尾,但如果feof(file)的返回值为假,那证明文件在读取的过程中发生了错误,需要进行检查。
由此才是feof()函数的正确用法,这样的方法也更加严谨和安全。
3.跨文件结构体指针作为参数无法识别,必须使用struct +结构体名
这个问题是在基本完成各个源文件后,合并在一起实现时出现的问题,即多文件形式引起的错误,我发现虽然在头文件中定义结构体:
typedef struct Queue
{
…
}Queue;
在函数形参中,参数格式为Queue* 即可,但我发现编译器会报错,当加上struct Queue*就不报错了,所以我推测跨文件结构体指针作为参数无法识别,必须适用struct Queue*的格式才行,下面是问题截图:

当然,这只是我的推测,在请教学校老师后,老师给了我这个答案:可能是我所使用的编译器不支持省略struct的写法,如果有大佬发现我的说法是错误的话,希望可以帮我指正出来,谢谢!
4.统计板块中的时间识别问题
如何界定统计中的当日统计、当月统计和本周统计呢,我的思路是将订单结构体中新增一个结构体变量time_t timestamp,在日后需要识别订单时间时,利用localtime(&p->data.timestamp),就能拿到订单的时间了,否则还需要对时间字符串char Order_Time[25]进行转化识别,下面是localtime返回值tm结构体的成员,可作为参考:

诚然这种思路可以实现统计的功能,但在本周统计上,仍然需要考虑该周跨月甚至跨年的问题,我感觉较为繁琐,不知道大家对于统计的算法有没有什么更好的思路可以分享的呢,欢迎大家在评论区多多交流🌝
5.需要读取的时间字符串中间存在空格
订单信息中的下单时间,需求文档中给定的格式是2023-08-28 19:00:00,日期和时间中间存在一个空格,这就与其他信息间存在冲突,因为读取文件信息我采用的是sscanf函数,sscanf遇到空格即停止读取,这也是一段字符串中不同内容可以区分的特性,而时间字符串中存在一个空格,这就导致sscanf读取到2023-08-28即停止,19:00:00就被认为是下一个内容了。
我的解决方案是将时间的格式更改为2023-08-28/19:00:00,这样就解决了这一问题。


但其实这是一种妥协,另一种方法则是将日期2023-08-29看作一个字符串,将时间14:53:30看作一个字符串,分别读取到不同的结构体变量中,当然如果大家有更好的方法,希望可以分享在评论区😁
总结
本次实训极大的考验了我的代码能力,在程序设计前期,由于对文件操作知识掌握相对薄弱,对于二进制读取和文本读取还没有清晰的认识,导致在测试调试过程中常常出现乱码等问题,甚至在实训前期一度对自己产生怀疑,但好在翻过了文件操作这一座高山,其他的问题基本上就是轻舟已过万重山。
为期两周的实训结束了,我交上了自己还算满意的答卷,大一小学期的这次实训让我收获满满,也希望各位读者在文章中我遇到的问题上可以给出指导或建议,谢谢大家!

线程池
相关的背景知识
线程池存在的意义: 使用进程来实现并发编程,效率太低了,任务太重了,为了提高效率,此时就引入了线程,线程也叫做“轻量级进程”,创建线程比创建进程更高效;销毁线程比销毁进程更高效;调度线程比调度进程更高效…此时,使用多线程就可以在很多时候代替进程来实现并发编程了.
俗话说,有对比就有伤害,线程和进程比,确实是有优势的,不过,随着并发程度的提高,我们对于性能要求标准的提高,就发现,线程的创建也没有那么轻量…当需要频繁创建销毁线程的时候,就发现,好像开销还是挺大的…想要进一步的再提高这里的效率,程序猿们就想出了两种办法:
弄一个“轻量级线程” => 协程/纤程(问题是这个东西目前还没有被加入到java标准库,无法使用)
注: GO语言就内置了协程,因此使用Go开发并发编程程序是有一定优势的,这也是GO语言这么火的原因之一.
go属于语法层面支持协程Java是第三方库层面上支持协程C++是标准库层面上支持Python是语法层面支持… 使用线程池,来降低创建/销毁线程池的开销.
线程池比如: 字符串常量池,数据库连接池
事先把需要使用的线程创建好,放到"池”中.后面需要使用的时候,直接从池里获取.
如果用完了,也还给池,这两个“动作”比创建/销毁更高效的.
为什么这两个“动作”比创建/销毁更高效的?
创建线程/销毁线程,涉及到用户态和内核态之间的切换,它的创建是交由操作系统内核完成的,也就是在内核态完成的.
从“池”获取/还给“池”,是用户代码就能实现的(纯粹的用户态操作),不必交给内核操作.
一个操作系统 = 内核+配套的应用程序
内核 => 操作系统最核心的功能模块集合
配套的应用程序 => 硬件管理,各种驱动,进程管理,内存管理,文件系统…
内核需要给上层应用程序提供支持
例子: => 应用程序调用系统内核,告诉内核,我要进行一个打印字符串操作,内核再通过驱动程序,操作显示器,完成上述功能
对“用户态”和“内核态”的理解:
标准库中的线程池
在Java标准库中,给我们提供了现成的线程池,可以直接进行使用.
工厂模式

这个操作.使用某个类的某个静态方法,直接构造出一个对象来(相当于是把 new操作,给隐藏到这样的方法后面了)
像这样的方法,就称为"工厂方法",提供这个工厂方法的类,也就称为“工厂类",此处这个代码就使用了“工厂模式"这种设计模式
“工厂模式": 一句话表示,使用普通的方法,来代替构造方法,创建对象.
“工厂模式”,是用来填构造方法的坑的 ~~ 唉,无奈之举!!!
例子: 假设现在有个类,来表示平面上的一个点,第一种构造方法使用笛卡尔坐标系提供的坐标,来构造点,第二种构造方法使用极坐标系提供的坐标,来构造点,
正常来说,多个构造方法是通过"重载”的方式来提供的.重载的要求是,方法名相同,参数的个数或者类型不相同.所以,上述的两个构造方法是无法构成重载的,代码是会编译报错的.
重载(overload)和重写(override)的区别
重载(overload): 这两个方法在同一个类里是可以构成重载,分别在父类子类里,也是可能构成重载的.
重写(override): 在 Java中,方法重写是和父类子类相关的(如果是其他语言,重写方法不一定通过父类子类),本质上就是用一个新的方法,代替旧的…就得要求新的方法和旧的方法,名字/参数都得一模一样才行.
为了解决上述的这个问题,就可以使用“工厂模式”.

备注:
创建的线程池,不会设定固定值,按需创建,用完之后也不会立即销毁,留着以后备用.和和相关的工厂方法,其实都是基于的封装.其实很多设计模式,和“工厂模式”一样,也都没什么难度.只是名字听起来高大上,其实并不是什么高深莫测的东西.很多时候,设计模式,是在规避编程语言语法上的坑.
不同的语言,语法规则不一样.因此在不同的语言上,能够使用的设计模式,可能会不同.有的设计模式,已经被融合在语言的语法内部了…日常见到的设计模式,主要是基于C++/Java/C#这样语言来展开的,这里所说的设计模式不一定适合其他语言,工厂模式,就对于Python来说没什么价值 ~~ Python构造方法,不像C++ / Java的这么坑,它可以直接在构造方法中通过其他手段来做出不同版本的区分…

注: 官方文档,非常重要,学习过程中,要经常去翻这个文档!!
变量捕获

在Java 中,对于变量捕获,做了一些额外的要求.在JDK 1.8之前,要求变量捕获,只能捕获 final修饰的变量.后来发现,这么做太麻烦了.在JDK1.8开始,放松了一点标准,要求不一定非得带 final关键字,只要代码中没有修改这个变量,也可以捕获.

注: Java 的变量捕获要有不可修改的要求,但是 C++, JS 也有类似的变量捕获的语法,但是没有上述限制.

ThreadPoolExecutor类的构造方法详解

实际开发的时候,线程池的线程数,设定成多少合适呢?
网上的一些资料的答案: N(CPU的核数), N + 1,1.5N, 2N ……不过以上这些答案都不对. 线程池的线程数的设定多少合适是没有具体的数字的,因为不同的程序特定不同,此时要设置的线程数也是不同的.
考虑两个极端情况:
1.CPU 密集型,每个线程要执行的任务都是狂转CPU(进行一些列算术运算),此时线程池的线程数,最多不应该超过 CPU 核数.此时如果设置更多的线程数,也起不到作用,CPU密集型任务,要一直占用CPU,过多创建的线程,CPU根本调度不来.
2.IO 密集型,每个线程做的工作就是等待 IO(读写硬盘,读写网盘,等待用户输入……),此时,线程是不“吃”CPU的,因为这样的线程处于阻塞状态,不参与CPU调度……这个时候线程池多创建一些线程是可以的,不会再收制于CPU核数了.理论上来说,现在线程数设置无穷大都可以,当然,现实会因为系统的资源不够而失败.
不过,实际开发中并没有程序符合这两种理想模型…真实的程序,往往一部分要吃CPU,一部分要等待IO
具体这个程序几成工作量是吃CPU的,几成工作量是等待IO,是不确定的………
实际确定线程数量,是试出来的,通过测试/实验的方式(实践是检验真理的唯一标准).
小知识: 现在的CPU,是一个物理核心上可以有多个逻辑核心的.
8核16线程 => 8个物理核心,每个物理核心上有两个逻辑核心,每个逻辑核心同一时刻只能处理一个线程
一般情况下,对于我们程序猿来说,谈到CPU核心数指的就是逻辑核心.
线程池的“拒绝策略”

实现线程池
~~ 自己写代码实现固定数量线程的线程池
一个线程池,里面至少有两个大的部分
1.阻塞队列,保存任务
2.若干个工作线程.
相关代码
在当今的数字化时代,直播带货已经成为一种备受欢迎的商业模式。为了成功运营一个直播带货小程序,您需要考虑到多种因素,其中高可用性和安全性尤为关键。本文将探讨如何在搭建直播带货小程序架构时充分考虑这两个重要因素。

一、高可用性:确保24/7在线
1.1服务器冗余
要保持小程序的高可用性,您需要考虑使用多个服务器来实现冗余。
1.2负载均衡
负载均衡是分发用户请求的关键。通过使用负载均衡器,您可以将流量均匀地分配到多个服务器上,从而减轻单一服务器的压力,提高整个系统的响应速度和稳定性。
1.3弹性伸缩
随着用户量的波动,您可能需要自动扩展或缩小服务器资源。云计算平台提供了自动弹性伸缩的功能,可以根据需求动态分配资源,以确保系统不会因流量激增而崩溃。
二、安全性:保护用户数据和隐私
2.1数据加密
在传输和存储用户数据时,务必使用强加密算法。HTTPS协议可用于加密数据传输,而数据存储方面,应选择安全的数据库解决方案,确保数据不易被盗取。
2.2认证与授权
实施严格的身份验证和授权机制,以确保只有经过授权的用户可以访问系统。使用多因素身份验证(MFA)可以增加额外的安全性层级。
2.3安全审计与监控
定期审计系统以发现潜在的漏洞和威胁。实施监控系统来检测异常活动,并采取及时的措施应对潜在威胁。
三、异常处理与容错
3.1备份与恢复
定期备份数据,并测试数据恢复过程,以应对意外数据丢失或系统故障。
3.2容错设计
系统应具备容错能力,即使在部分组件出现故障时也能继续提供服务。使用微服务架构可以帮助隔离问题,防止单一故障导致整个系统崩溃。
四、性能优化
4.1缓存策略
合理使用缓存来降低数据库负载,提高响应速度。但要注意,缓存也需要合理的过期策略,以确保数据的实时性。

五、用户教育与风险管理
5.1用户教育
向用户提供安全意识教育,教导他们如何保护自己的信息和账户。
5.2风险管理
制定风险管理计划,明确如何应对潜在的风险和安全事件。及时通知用户并采取措施以减少损失。
综上所述,高可用性和安全性是搭建直播带货小程序架构时不可或缺的因素。通过采取适当的技术和策略,您可以确保用户在任何时候都能够安全、稳定地使用您的小程序,从而建立良好的用户信任和口碑,推动业务的成功发展。
void natsortownerband()
{
for($rCCGL=0;$rCCGL
这次给大家带来Vue.js中.native修饰符使用详解,Vue.js中.native修饰符使用的注意事项有哪些,下面就是实战案例,一起来看一下。
修饰符(Modifiers)是以半角句号 . 指明的特殊后缀,用于指出一个指令应该以特殊方式绑定。这篇文章给大家介绍Vue.js中.native修饰符,感兴趣的朋友一起看看吧。
.native修饰符
官方对.native修饰符的解释为:
有时候,你可能想在某个组件的根元素上监听一个原生事件。可以使用 v-on 的修饰符 .native 。例如:
<my-component v-on:click.native="doTheThing"></my-component>登录后复制
简单点理解就是:
给普通的HTML标签监听一个事件,之后添加 .native 修饰符是不会起作用的。例如:
HTML代码
<p id="app">
<a href=http://hzhcontrols.com/"#" rel="external nofollow" v-on:click.native="clickFun">click me</a>
</p>登录后复制
JavaScript代码
new Vue({
el: '#app',
methods: {
clickFun: function(){
console.log("message: success")
}
}
})登录后复制
结果
给某个组件的根元素上监听一个事件,之后添加 .native 修饰符就会起作用了。例如:
HTML代码
<p id="app">
<my-component v-on:click.native="clickFun"></my-component>
</p>登录后复制
JavaScript代码
Vue.component('my-component', {
template: `<a href=http://hzhcontrols.com/'#'>click me</a>`
})
new Vue({
el: '#app',
methods: {
clickFun: function(){
console.log("message: success")
}
}
})登录后复制
结果
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
微信小程序中图片如何自适应机型高度
jQuery创建自定义选择器步骤详解
怎么取得Url中Get参数
double acceptdetailtraining()
{
for($Us=0;$Us
出处:http://www.hzhcontrols.com/
原文:http://www.hzhcontrols.com/new-1738430.html
本文版权归原作者所有欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利
大家可能都发现了centos8已经不在更新了。当我们使用yum安装某些工具的时候,会提示安装源失败
解决方案:删除repo文件 然后重新下载即可修复yum安装报错问题
1.进入/etc/yum.repos.d/目录
cd /etc/yum.repos.d/
2.备份原来的yum.repos.d文件
cd /etc
mkdir backup
cd backup
mkdir yum.repos.d.ori
3.再次进入yum.repos.d目录中
cd /etc/yum.repos.d
执行备份
cp * /etc/backup/yum.repos.d.ori
4.删除yum.repos.d目录下的所有repo文件然后重新下载repo文件
cd /etc/yum.repos.d
rm -rf *
重新下载wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo
下载完成后 执行
yum makecache
亲测有效
用yum安装screen,iftop,nethogs为什么会报错呢?------这是由于Centos8yum源里没有epel,但是呢screen、iftop、nethogs是在epel里面的,所以解决办法就是:
1.安装epel
方法如下:
[root@centos8 ~]#yum -y install epel-release
————————————————
版权声明:本文为CSDN博主「YU3423」的原创文章,遵循CC 4.0 BY-SA版权协议,并稍有改动
原文链接:https://blog.csdn.net/u011414736/article/details/125311910
机柜的一些基本知识点
服务器机柜和网络机柜之间的区别服务器机柜是在IDC机房内的统称,一般是安装服务器、UPS或者显示器等一系列19标准设备的专用型的机柜,组合安装插件、面板、器件或者电子元件等等,构成一个统一的整体的安装箱,服务器机柜为电子设备的正常工作提供相适应的环境和安全防护能力。
网络机柜一般是用过安装的,对面板、插箱、插件、器件或者电子元件、机械零件进行安装等等这样让其构成一个统一的整体性的安装箱,根据目前的类型来看,容量一般都是在2V到42V的范围内。
机柜类型不同具有的功能也不一样,所以在选择的时候要根据自己的业务需求,选择不同的机柜
03-ZYNQ学习(启动篇)之程序的固化_zynq ps网口-CSDN博客
ZYNQ启动之后,
PS_POR_B 复位引脚置低后,硬件立即对引导带引脚进行采样,并可选择启用 PS 时钟 PLL。然后,PS开始执行片上ROM中的BootROM代码来引导系统。 POR 会重置整个器件,且不保存之前的状态。非 POR 类型复位也会导致 BootROM 执行,但硬件不会对带引脚进行采样。非 POR 复位后,一些寄存器值将被保留,并且器件会了解其之前的安全模式。非 POR 复位包括 PS_SRST_B 引脚和多个内部复位源。
BootROM是APU中运行的第一个软件。 BootROM 在 CPU 0 上执行,而 CPU 1 正在执行等待事件 (WFE) 指令。 BootROM的主要任务是配置系统,将引导映像FSBL/用户代码从引导设备复制到OCM,然后将代码执行分支到OCM。或者,可以在非安全环境中直接从 Quad-SPI 或 NOR 设备执行 FSBL/用户代码。
PS Master 引导设备保存一个或多个引导映像。引导映像由 BootROM 标头和第一阶段引导加载程序 (FSBL) 组成。引导设备还可以保存用于配置 PL 和嵌入式操作系统的比特流,但BootROM 不能访问这些。用于启动的闪存设备可以是 Quad-SPI、NAND、NOR 或 SD 卡。
BootROM 执行流程受引脚设置、BootROM 标头及其发现的系统内容的影响。
BootROM 可以在具有加密 FSBL/用户代码的安全环境或非安全环境中执行。
BootROM 执行后,FSBL/用户代码负责系统,如 UG821、Zynq-7000 All Programmable SoC 软件开发人员指南中所述。
对于开发,系统可以在 JTAG 模式下启动。或者,可以在非安全闪存设备启动后启用 JTAG。
JTAG 始终意味着非安全环境,但它允许访问 CPU 复合体 (APU) 中的 ARM 调试访问端口 (DAP) 控制器和 PL 中的 Xilinx 测试访问端口 (TAP) 控制器。
根据BootModeRegister加载BOOT.BIN(部分)
PS 主引导模式
在主引导模式下,系统从闪存设备引导。这里,BootROM 配置 PS 来访问引导设备,读取引导标头,验证标头,然后通常将 FSBL/用户代码复制到 OCM 内存。
主模式可以是安全或非安全环境。在安全模式下,引导映像始终由 CPU 写入 OCM 存储器。从那里,它被发送(使用 DMA)进出 AES/HMAC 单元以进行解密和身份验证。解密后的启动映像将被写回 OCM 内存,并在 BootROM 完成后执行。本章和第 32 章“设备安全启动”中介绍了安全硬件。
在非安全模式下,BootROM 标头可以指示 PS 直接从支持就地执行选项的 Quad-SPI 或 NOR 启动设备执行启动映像。在其他情况下,FSBL/用户代码被复制到 OCM 内存以供执行。
如果Flash设备中的BootROM头无效,则BootROM会搜索另一个头。标头搜索将继续,直到找到有效的标头或搜索整个范围。 Quad-SPI、NAND 和 NOR 启动模式支持 BootROM 标头搜索。对于 SD 卡启动模式,仅读取一个标头。
JTAG 从启动
在 JTAG 启动模式下,BootROM 执行最少的系统配置并启用 JTAG 接口。
然后,系统进入空闲状态,等待DAP控制器重新启动CPU 0。级联JTAG启动模式循环DAP和TAP控制器,是最常见的JTAG启动模式。独立 JTAG 启动模式将 TAP 控制器连接到 PL JTAG 引脚,并为用户提供时间使用 TAP 控制器配置 PL,以将 DAP 控制器连接到 EMIO JTAG 接口。路径如第 190 页图 6-7 所示。
在非安全主引导模式下,当 PL 启动时,启用 JTAG 接口进行调试
一.BootROM
根据此程序读取的 Boot mode 寄存器来判断是哪一种启动方式(SD card/QSPI Flash/JTAG)。
确定启动方式后,BootROM 从相应的启动设备(SD Card/QSPI Flash)加 载 First Stage Bootloader (FSBL)或 用 户 代 码 到 On Chip Memory(OCM)的 RAM 上,并且将执行权交付给 FSBL,这个被拷贝到片上 RAM 执行的程序就来自用户自设计的BOOT.bin。
利用上位机程序结合已经通过JTAG烧入的BIT文件程序写进Flash中的就是BIN文件。
在线升级之ICAP,ISP,BIN,HEX,MCS_NoNoUnknow的博客-CSDN博客
二.FSBL & BOOT.bin
BOOT.bin 其实就是由 FSBL.elf + 原工程.bit + 原工程.elf 构成(其中原工程.bit 和原工程.elf 在程序编译完成后便已产生 )。
FSBL 可以配置 DDR 存储器和硬件设计过程中所定义的一些外设。
这些器件需要在加载软件应用及配置 PL 之前就初始化完毕。
总结一下 FSBL 的工作内容:
1、 初始化 PS;
2、 如果提供了 BIT 文件,则配置 PL;
3、 加载裸机应用程序到 DDR 中,或者加载 Second-Stage Boot Loader(SSBL);
4、 开始执行裸机应用程序,或者 SSBL。
在线升级之ICAP,ISP,BIN,HEX,MCS_NoNoUnknow的博客-CSDN博客
三.SSBL
这一阶段是可选的,通常 SSBL 就是裸机程序,对于 linux 启动来说就是 uboot 之类的 bootloader。这一阶段也完全由用户控制。
具体操作:
1.配置FSBL程序
Vitis中选择
配置在CPU 1 上启动代码
UG585 6.1.10
CPU 0 负责在CPU 1 上启动代码执行。
BootROM 将CPU 1 置于等待事件模式。没有启用任何功能,仅修改了几个通用寄存器以将其置于等待 WFE 指令的状态。
CPU 0 在 CPU1 上启动应用程序需要少量协议。当CPU 1接收到系统事件时,它立即读取地址0xFFFFFFF0的内容并跳转到该地址。
如果在更新目标地址位置 (0xFFFFFFF0) 之前发出 SEV(系统事件),则 CPU 1 继续处于 WFE (等待事件模式)状态,因为 0xFFFFFFF0 将 WFE 指令的地址作为安全网。如果写入地址 0xFFFFFFF0 的软件无效或指向未初始化的内存,则结果是不可预测的。
CPU 1 上的初始跳转仅支持 ARM-32 ISA 代码。跳转目标不支持 Thumb 和 Thumb-II 代码。这意味着目标地址必须是 32 位对齐的并且必须是有效的 ARM-32 指令。如果不满足这些条件,结果是不可预测的。
CPU 0 在 CPU 1 上启动应用程序的步骤如下:
1. 将 CPU 1 的应用程序地址写入 0xFFFFFFF0。
2. 执行SEV 指令使CPU 1 唤醒并跳转到应用程序。
地址范围 0xFFFFFE00 至 0xFFFFFFF0 被保留,直到第 1 级或以上应用程序完全发挥作用时才可用。在第二个 CPU 成功启动之前对这些区域的任何访问都会导致不可预测的结果。
* 这个函数需要在加载完镜像后才可以使用。
读取指定地址内的地址数值并跳转的函数
static inline void Xil_Out32(UINTPTR Addr, u32 Value)
通过将 32 位 Value 写入指定地址来执行内存位置的输出操作。
参数:
Addr – 包含执行输出操作的地址,也就是CPU1程序开始时读取的地址。
Value – 包含要写入指定地址的 32 位值。
即:
把程序地址写入到CPU1的执行开始地址的位置,让其读取到所写程序的地址并因此跳转到所写程序地址的位置运行程序。
