目前国内大模型行业的投资人和领军人,是否远远低估了基础设施的重要性?
比如框架、编译器
真正的顶级投资人和人工智能领军人是没有低估基础设施的重要性的。提问者本身倒可能对此并不了解。
大模型的基础设施包括
计算设备
计算设备是人工智能应用的基础,包括中央处理器(CPU)、图形处理器(GPU)、领域特定集成电路(ASIC)等。这些设备可以提供强大的计算能力,支持训练和推断任务。大家可能会听说 Nvidia 的 A100或 H100,这些是真正的基础设施。A100是NVIDIA推出的第八代数据中心GPU,基于安培架构,拥有第三代张量核心,可以提供高达312 TFLOPS的混合精度计算性能。A100支持多种精度,包括FP64,FP32,TF32,BF16,INT8和INT4。A100还支持多实例GPU(MIG)技术,可以将一个GPU划分为多个独立的虚拟GPU。H100是NVIDIA即将推出的第九代数据中心GPU,基于霍珀架构,拥有第四代张量核心,可以提供高达1 PFLOPS的混合精度计算性能。H100支持新的FP8精度,可以加速大规模语言模型(LLM)的推理。H100还支持NVLink Switch System技术,可以将多达256个H100 GPU连接起来,实现超级计算机级别的扩展。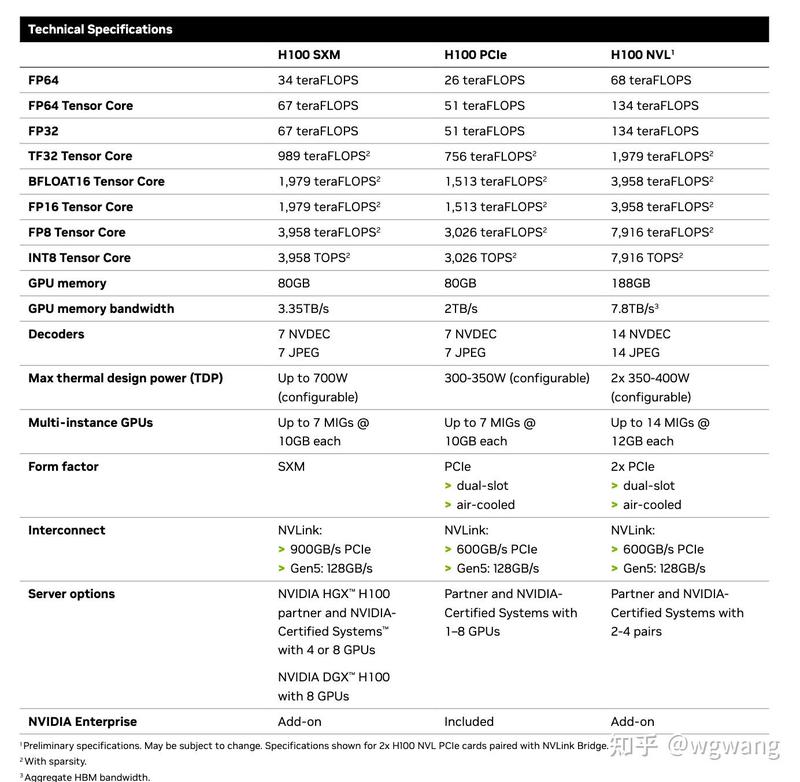 TPU是谷歌开发的专用芯片,用于加速神经网络的训练和推理。TPU目前有四代版本,每个版本都提供了比前一代更高的性能和效率。TPU支持BF16和INT8精度,以及谷歌自定义的bfloat16和int4精度。TPU还支持Pod技术,可以将多个TPU芯片组成一个大规模的集群。
TPU是谷歌开发的专用芯片,用于加速神经网络的训练和推理。TPU目前有四代版本,每个版本都提供了比前一代更高的性能和效率。TPU支持BF16和INT8精度,以及谷歌自定义的bfloat16和int4精度。TPU还支持Pod技术,可以将多个TPU芯片组成一个大规模的集群。
当然,芯片只是其中一项,还有许多技术,比如Nvidia 的 AVlink组成的 DGX,或者 google 的 TPU Pod。在服务器之上,还需要高速网络将其组成大型服务集群。相信大家听说10000卡,就是要把10000张卡组成大型计算集群,其难度也是非常大的。
大规模存储和计算集群
这块类似于云计算了,不过对于大模型来说,要清洗、处理数据,必须用到这样的基础设施。GPT-4是用PB 级的语料训练出来的,没有大规模存储和计算集群,显然不好搞。国内云计算喊了很多年了,其生态比起 google、微软和亚马逊,还是逊色一些的。PB级别的大规模存储和计算的设施是指能够处理和存储以PB(10^15字节)为单位的海量数据的计算机系统。这些设施通常需要高速的网络连接,高性能的处理器,大容量的内存,以及可靠的存储系统。以 Google 的为例:谷歌云平台(Google Cloud Platform)是谷歌提供的一系列云计算服务,包括基础设施即服务(IaaS),平台即服务(PaaS),软件即服务(SaaS),以及各种专用于人工智能,大数据,物联网等领域的解决方案。谷歌云平台利用谷歌在全球范围内部署了数百个数据中心和数千个边缘节点。谷歌云平台提供了多种存储选项,包括云存储(Cloud Storage),云文件存储(Cloud Filestore),云SQL(Cloud SQL),云大表(Cloud Bigtable),云Spanner(Cloud Spanner),云Firestore(Cloud Firestore),云内存存储(Cloud Memorystore)等。这些存储服务可以满足不同类型和规模的数据需求,从几GB到几PB甚至更多。谷歌云平台还提供了多种计算选项,包括云引擎(Compute Engine),云函数(Cloud Functions),App引擎(App Engine),Kubernetes引擎(Kubernetes Engine),云运行(Cloud Run),AI平台(AI Platform)等。这些计算服务可以支持不同类型和规模的应用程序和工作负载,从几个核心到几万个核心甚至更多。
框架和工具
这块包括多方面的内容,一块是TensorFlow、PyTorch和 Paddle,相信大家都很熟。TensorFlow是谷歌开发的一个开源的深度学习框架,支持多种编程语言,如Python,C++,Java等。TensorFlow提供了灵活的计算图机制,可以表示复杂的神经网络结构和运算。TensorFlow还提供了多种工具和库,如Keras,TensorBoard,TFX等,以方便用户开发和部署深度学习应用。TensorFlow支持多种硬件平台,如CPU,GPU,TPU等,并且可以实现分布式训练和推理。PyTorch是Facebook开发的一个开源的深度学习框架,主要使用Python语言,也支持C++等。PyTorch提供了动态的计算图机制,可以实现即时编译和执行神经网络运算。PyTorch还提供了多种工具和库,如TorchVision,TorchText,TorchAudio等,以方便用户处理不同类型的数据和任务。PyTorch支持多种硬件平台,如CPU,GPU等,并且可以实现分布式训练和推理。Paddle是百度开发的一个开源的深度学习框架,主要使用Python语言,也支持C++等。Paddle提供了同时支持静态和动态计算图机制的混合编程模式,可以根据用户的需要选择不同的编程范式。Paddle还提供了多种工具和库,如PaddleHub,PaddleNLP,PaddleClas等,以方便用户快速使用预训练模型和完成不同类型的任务。Paddle支持多种硬件平台,如CPU,GPU等,并且可以实现分布式训练和推理。
在这之下,还有一个非常重要的框架,就是分布式训练和推断的,比如 DeepSpeed,Triton 等。DeepSpeed是微软开发的一个开源的深度学习优化库,旨在提高大规模模型训练的效率,速度,成本和易用性。DeepSpeed提供了多项创新的技术,如ZeRO(零冗余优化器),3D并行(数据并行,模型并行和流水线并行的灵活组合),DeepSpeed-MoE(混合专家模块),ZeRO-Infinity(无限内存训练)等。这些技术可以实现对百亿至万亿参数模型的高效训练,同时节省显存,提升吞吐量,降低通信开销,并保证收敛性。DeepSpeed还提供了多种工具和库,如稀疏注意力(Sparse Attention),1比特Adam(1-bit Adam),DeepSpeed-Chat(基于深度学习的聊天机器人)等。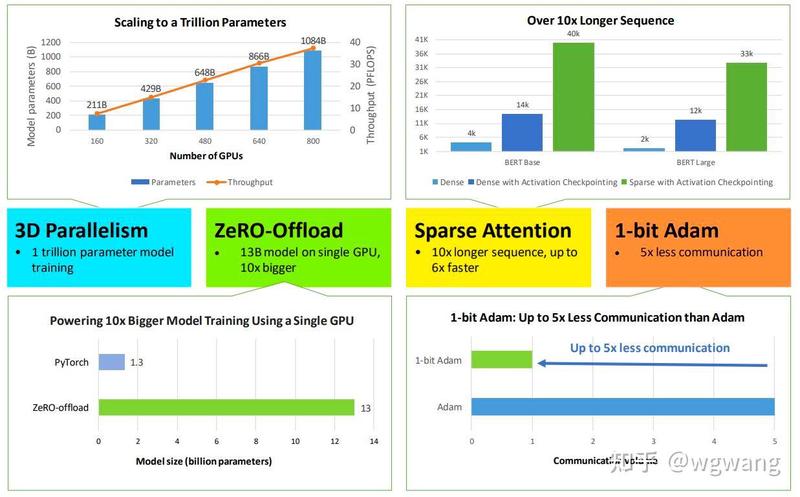 Triton是NVIDIA开发的一个开源的编程语言和编译器,旨在简化并加速深度学习推理的定制化。Triton可以让用户使用类似Python的语法编写高效的GPU内核,而无需了解底层硬件架构或CUDA编程。Triton还提供了多种优化技术,如自动调整,自动融合,自动向量化等,以提升GPU内核的性能和可移植性。Triton可以用于实现各种深度学习算子,如卷积,注意力,池化等,并且可以与PyTorch等框架无缝集成。
Triton是NVIDIA开发的一个开源的编程语言和编译器,旨在简化并加速深度学习推理的定制化。Triton可以让用户使用类似Python的语法编写高效的GPU内核,而无需了解底层硬件架构或CUDA编程。Triton还提供了多种优化技术,如自动调整,自动融合,自动向量化等,以提升GPU内核的性能和可移植性。Triton可以用于实现各种深度学习算子,如卷积,注意力,池化等,并且可以与PyTorch等框架无缝集成。
这些基础设施对于投资人来说,其实并不是好标的,对于领军人来说,肯定理解其重要性。其实,大厂都在做了。只不过,这些基础设施,可不是一时半会就能搞出来的。属于投资周期长的,这也是为什么投资人几乎不谈这个。
在这些基础设施之外,还有重要的一环,就是知识。这也许是知识图谱,或者是Woform Alpha这样的知识计算引擎。这是由于 AGI 需要这样的工具。从 AGI 视角来说:
神经网络大模型 ⊕ 知识图谱 ⊕ 强化学习=人本AGI
其中,⊕表示了某种组合/融合的方法,并且:神经网络大模型:连接主义发展至今的代表性成果,随着 AGI 的发展,大语言模型未必会是最终形态,比如多模态跨模态的神经网络大模型;神经网络大模型(Neural Network Large Models)是指由很多参数(通常是数十亿个或更多的权重)组成的神经网络,它们可以在大量的无标注文本上使用自监督学习进行训练。神经网络大模型从2018年左右开始出现,它们在很多任务上都表现出了优异的性能。随着 AGI 的发展,大语言模型未必会是最终形态,比如多模态跨模态的神经网络大模型。花书《深度学习》对这个主题进行了深入的解析。神经网络大模型的一个典型代表是GPT-3,神经网络大模型的规模可以用参数的数量来衡量。参数是神经网络中的一些值,它们在训练过程中不断地被调整,并且在预测时被使用。简单来说,一个模型有更多的参数,就意味着它可以从训练数据中吸收更多的信息,并且对新数据的预测更加准确。 花书《深度学习》知识图谱 :符号主义发展至今的代表性成果,随着 AGI 的发展,知识图谱本身也需要不断发展,目前这种知识图谱未必是最终形态,比如拥有更强表达能力、知识计算的计算、推理和规划能力的知识图谱;对知识图谱有兴趣的,建议学习珠峰书《知识图谱:认知智能理论与实战》深入了解知识图谱的构建、存储、规划和推理等技术原理。知识图谱是目前用以解决 AGI 有关事实性问题的核心技术。关于解决事实性的问题是迫在眉睫的,著名的马斯克也是这么说的。《知识图谱:认知智能理论与实战》全面介绍了如何构建、存储和使用知识图谱,特别是知识推理部分,是辅助大模型解决高阶推理的核心技术。具体来说,王文广这本《知识图谱:认知智能理论与实战》涵盖了知识图谱的理论基础、技术体系和应用实战。首先,它详细讲解了知识图谱的概念、发展历程、架构模型、存储与检索等基本知识。接着,书中介绍了知识图谱构建的整体流程和关键技术,包括实体识别、关系抽取、属性抽取、实体链接、本体构建等。同时,书中还介绍了知识图谱的表示学习、图神经网络等前沿技术,以及多个知识图谱应用场景,如智能问答、知识推理、智能推荐、金融、医疗、智能制造等领域的应用等。总之,王文广的《知识图谱:认知智能理论与实战》是一本涵盖知识图谱理论、技术和应用实践的全面性专业书籍,对于从事人工智能、知识图谱相关领域的技术人员、学者和研究人员都具有极强的参考价值。
花书《深度学习》知识图谱 :符号主义发展至今的代表性成果,随着 AGI 的发展,知识图谱本身也需要不断发展,目前这种知识图谱未必是最终形态,比如拥有更强表达能力、知识计算的计算、推理和规划能力的知识图谱;对知识图谱有兴趣的,建议学习珠峰书《知识图谱:认知智能理论与实战》深入了解知识图谱的构建、存储、规划和推理等技术原理。知识图谱是目前用以解决 AGI 有关事实性问题的核心技术。关于解决事实性的问题是迫在眉睫的,著名的马斯克也是这么说的。《知识图谱:认知智能理论与实战》全面介绍了如何构建、存储和使用知识图谱,特别是知识推理部分,是辅助大模型解决高阶推理的核心技术。具体来说,王文广这本《知识图谱:认知智能理论与实战》涵盖了知识图谱的理论基础、技术体系和应用实战。首先,它详细讲解了知识图谱的概念、发展历程、架构模型、存储与检索等基本知识。接着,书中介绍了知识图谱构建的整体流程和关键技术,包括实体识别、关系抽取、属性抽取、实体链接、本体构建等。同时,书中还介绍了知识图谱的表示学习、图神经网络等前沿技术,以及多个知识图谱应用场景,如智能问答、知识推理、智能推荐、金融、医疗、智能制造等领域的应用等。总之,王文广的《知识图谱:认知智能理论与实战》是一本涵盖知识图谱理论、技术和应用实践的全面性专业书籍,对于从事人工智能、知识图谱相关领域的技术人员、学者和研究人员都具有极强的参考价值。 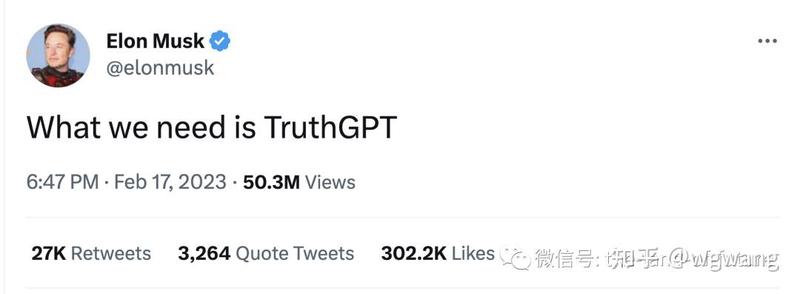 马斯克认为 ChatGPT 还不够 Truth,这需要知识图谱来支撑。
马斯克认为 ChatGPT 还不够 Truth,这需要知识图谱来支撑。 珠峰书《知识图谱:认知智能理论与实战》强化学习:行为主义发展至今的代表性成果,随着 AGI 的发展,强化学习本身也会不断发展,PPO 未必是最佳的形式。对强化学习有兴趣的,推荐Richard S. Sutton的《强化学习》(Reinforcement Learning: An Introduction)(下载抵制:https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf)。这是强化学习领域最为经典的教科书之一。这本书系统地介绍了强化学习的基本概念、主要算法和应用领域。它对强化学习的发展和应用具有重要的推动作用,被广泛应用于人工智能、机器人、自动化控制、游戏等领域。而Richard S. Sutton是加拿大阿尔伯塔大学计算机科学教授、加拿大计算机科学协会Fellow、加拿大皇家科学院Fellow,以及加拿大计算机学会和国际机器学习协会的会员。他在人工智能和机器学习领域有着极高的声誉和影响力,被誉为强化学习领域的创始人之一。
珠峰书《知识图谱:认知智能理论与实战》强化学习:行为主义发展至今的代表性成果,随着 AGI 的发展,强化学习本身也会不断发展,PPO 未必是最佳的形式。对强化学习有兴趣的,推荐Richard S. Sutton的《强化学习》(Reinforcement Learning: An Introduction)(下载抵制:https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf)。这是强化学习领域最为经典的教科书之一。这本书系统地介绍了强化学习的基本概念、主要算法和应用领域。它对强化学习的发展和应用具有重要的推动作用,被广泛应用于人工智能、机器人、自动化控制、游戏等领域。而Richard S. Sutton是加拿大阿尔伯塔大学计算机科学教授、加拿大计算机科学协会Fellow、加拿大皇家科学院Fellow,以及加拿大计算机学会和国际机器学习协会的会员。他在人工智能和机器学习领域有着极高的声誉和影响力,被誉为强化学习领域的创始人之一。 Reinforcement Learning:An Introduction
Reinforcement Learning:An Introduction
其实,投资人看到这里的话,给一个建议:
除了长周期的基础设施之外,专业数据、知识图谱、知识计算引擎等,也能够占据关键一环,可以考虑投资这方面的标的。
至于领军人物,肯定都已经着手在干了!
