目录
- 两种获取help的方法
- 使用Numpy中的info方法
- Python内置函数
- 一、文本文件
- 1、纯文本文件
- 2、表格数据:Flat文件
- 二、Excel 电子表格
- 三、SAS 文件
- 四、Stata 文件
- 五、Pickled 文件
- 六、HDF5 文件
- 七、Matlab 文件
- 八、关系型数据库
- 1、直接查询关系型数据库
- 2、使用Pandas查询关系型数据库
- 数据探索
- 1、NumPy Arrays
- 2、Pandas DataFrames
大多数情况下,会使用NumPy或Pandas来导入数据,因此在开始之前,先执行:
import numpy as np import pandas as pd
两种获取help的方法
很多时候对一些函数方法不是很了解,此时Python提供了一些帮助信息,以快速使用Python对象。
使用Numpy中的info方法
np.info(np.ndarray.dtype)

Python内置函数
help(pd.read_csv)
一、文本文件
1、纯文本文件
filename = 'demo.txt' file = open(filename, mode='r') # 打开文件进行读取 text = file.read() # 读取文件的内容 print(file.closed) # 检查文件是否关闭 file.close() # 关闭文件 print(text)
使用上下文管理器 -- with
with open('demo.txt', 'r') as file: print(file.readline()) # 一行一行读取 print(file.readline()) print(file.readline())
2、表格数据:Flat文件
使用 Numpy 读取 Flat 文件
Numpy 内置函数处理数据的速度是 C 语言级别的。
Flat 文件是一种包含没有相对关系结构的记录的文件。(支持Excel、CSV和Tab分割符文件 )
1.具有一种数据类型的文件
用于分隔值的字符串跳过前两行。在第一列和第三列读取结果数组的类型。
filename = 'mnist.txt' data = np.loadtxt(filename, delimiter=',', skiprows=2, usecols=[0,2], dtype=str)
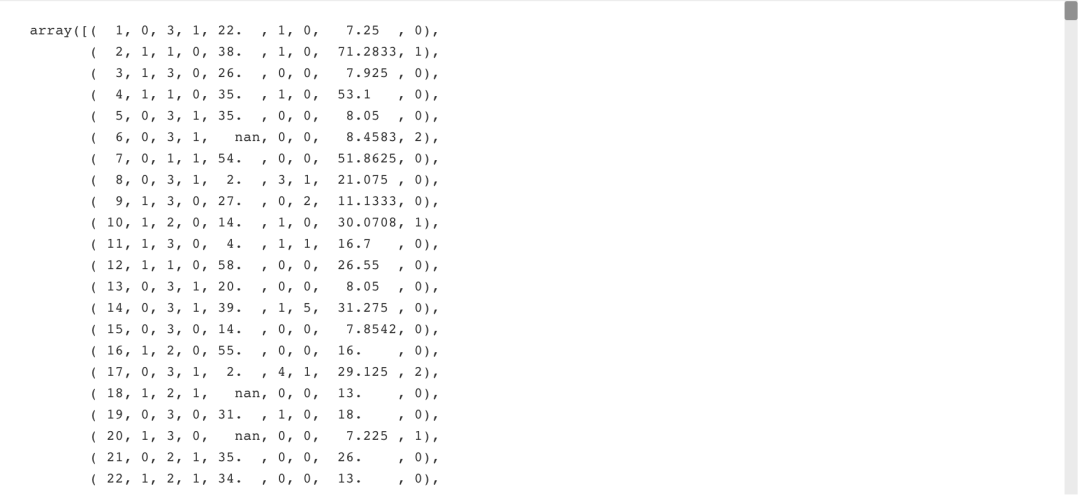
2.具有混合数据类型的文件
两个硬的要求:
- 跳过表头信息
- 区分横纵坐标
filename = 'titanic.csv' data = np.genfromtxt(filename, delimiter=',', names=True, dtype=None)
使用 Pandas 读取Flat文件
filename = 'demo.csv' data = pd.read_csv(filename, nrows=5, # 要读取的文件的行数 header=None, # 作为列名的行号 sep='\t', # 分隔符使用 comment='#', # 分隔注释的字符 na_values=[""]) # 可以识别为NA/NaN的字符串
二、Excel 电子表格
Pandas中的ExcelFile()是pandas中对excel表格文件进行读取相关操作非常方便快捷的类,尤其是在对含有多个sheet的excel文件进行操控时非常方便。
file = 'demo.xlsx' data = pd.ExcelFile(file) df_sheet2 = data.parse(sheet_name='1960-1966', skiprows=[0], names=['Country', 'AAM: War(2002)']) df_sheet1 = pd.read_excel(data, sheet_name=0, parse_cols=[0], skiprows=[0], names=['Country'])
使用sheet_names属性获取要读取工作表的名称。
data.sheet_names
三、SAS 文件
SAS (Statistical Analysis System)是一个模块化、集成化的大型应用软件系统。其保存的文件即sas是统计分析文件。
from sas7bdat import SAS7BDAT with SAS7BDAT('demo.sas7bdat') as file: df_sas = file.to_data_frame()
四、Stata 文件
Stata 是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。其保存的文件后缀名为.dta的Stata文件。
data = pd.read_stata('demo.dta')
五、Pickled 文件
python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化。python的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
import pickle with open('pickled_demo.pkl', 'rb') as file: pickled_data = pickle.load(file) # 下载被打开被读取到的数据
与其相对应的操作是写入方法pickle.dump() 。
六、HDF5 文件
HDF5文件是一种常见的跨平台数据储存文件,可以存储不同类型的图像和数码数据,并且可以在不同类型的机器上传输,同时还有统一处理这种文件格式的函数库。
HDF5 文件一般以 .h5 或者 .hdf5 作为后缀名,需要专门的软件才能打开预览文件的内容。
import h5py filename = 'H-H1_LOSC_4_v1--4096.hdf5' data = h5py.File(filename, 'r')
七、Matlab 文件
其由matlab将其工作区间里的数据存储的后缀为.mat的文件。
import scipy.io filename = 'workspace.mat' mat = scipy.io.loadmat(filename)
八、关系型数据库
from sqlalchemy import create_engine engine = create_engine('sqlite://Northwind.sqlite')
使用table_names()方法获取一个表名列表
table_names = engine.table_names()
1、直接查询关系型数据库
con = engine.connect() rs = con.execute("SELECT * FROM Orders") df = pd.DataFrame(rs.fetchall()) df.columns = rs.keys() con.close()
使用上下文管理器 -- with
with engine.connect() as con: rs = con.execute("SELECT OrderID FROM Orders") df = pd.DataFrame(rs.fetchmany(size=5)) df.columns = rs.keys()
2、使用Pandas查询关系型数据库
df = pd.read_sql_query("SELECT * FROM Orders", engine)
数据探索
数据导入后会对数据进行初步探索,如查看数据类型,数据大小、长度等一些基本信息。这里简单总结一些。
1、NumPy Arrays
data_array.dtype # 数组元素的数据类型 data_array.shape # 阵列尺寸 len(data_array) # 数组的长度
2、Pandas DataFrames
df.head() # 返回DataFrames前几行(默认5行) df.tail() # 返回DataFrames最后几行(默认5行) df.index # 返回DataFrames索引 df.columns # 返回DataFrames列名 df.info() # 返回DataFrames基本信息 data_array = data.values # 将DataFrames转换为NumPy数组
以上就是Python中八种数据导入方法总结的详细内容,更多关于Python数据导入的资料请关注本网站其它相关文章!
您可能感兴趣的文章:
- Python导入txt数据到mysql的方法
- Python制作数据导入导出工具
- python Django批量导入数据
- Python 中导入csv数据的三种方法
- 用Python将Excel数据导入到SQL Server的例子
