Python常用的正则表达式
Python常用的正则表达式
「—通过实例总结 Python 正则表达式的使用」
内容概要
正则表达式(regular expression)用于描述一种字符串匹配的模式,它是一组由字母和符号组成的特殊文本,可以用于检查一个字符串是否包含某个子字符串、将匹配的子字符串替换或提取出来等操作。
Python 中自带的标准库,可用于实现字符串的正则匹配。本文将通过实际案例,总结 Python 中常见的正则表达式的使用方法。
目录
元字符概括字符集数量词边界匹配组匹配模式参数替换字符分组
1. 元字符
正则表达式中匹配规则如下: 

接下里通过实际案例来介绍如何使用正则表达式来提取字符串中的目标子字符串。
使用正则表达式之前,需要先导入模块:
提取字符串 s1 中指定范围(0-9)的数字:
输出结果: 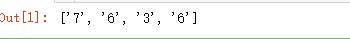
提取字符串 s1 中 1-6 之间的数字:
输出结果: 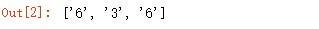
提取字符串 s2 中间字母为 d 或 e 的单词:
输出结果: 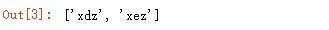
提取字符串 s2 中间字母不为 d 或 e 的单词:
输出结果: 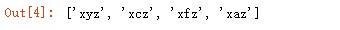
提取字符串中间字母为 d 或 e 或 f 的单词:
输出结果: 
2. 概括字符集
使用提取所有数字
输出结果: 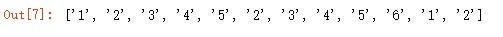
使用提取所有非数字:
输出结果: 
使用用于匹配中文,下划线,数字,英文,但无法提取空格,\n,$,\t 等特殊字符:

大写的 W,用于提取提取特殊字符、空格、\n、\t 等:
输出结果: 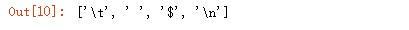
小写 s 用于提取空白字符,如空格、换行符、制表符等[\t\n\r\f\v]:
输出结果: 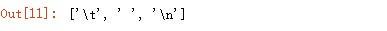
大写 S,与相反,用于提取非空白字符:
输出结果: 
3. 数量词
提取字符串中的单词,其中{3,5}表示单词字母个数,最小为 3,最大为 5:
输出结果: 
匹配 0 次或无限多次号,前面的字符出现 0 次或无限次。下面例子中前面为字母 l,当匹配 0 次时,返回的是 exce,1 次时返回为 excel,2 次时返回的为 excell:
输出结果: 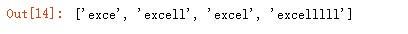
使用+号,匹配 1 次或无限次,即+号前面的字符至少出现一次,可以结合的作用,对比来理解:
输出结果: 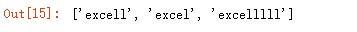
?号用于匹配 0 次或 1 次,即?前面的字符出现 0 次或 1 次,经常用来去重:
输出结果: 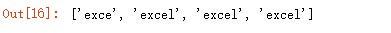
4. 边界匹配
^表示开始标记,$ 表示结束标记,{11}限制长度为 11:
输出结果: 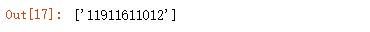
输出结果: 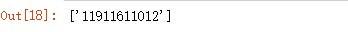
输出结果: 
5. 组
将 abc 打成一个组,{2}指的是重复 2 次,匹配 abcabc,s7 中出现两次,所以返回两个'abc':
输出结果: 
输出结果: 
{1}则代表出现一次 abc 就能匹配,可以省略:
输出结果: 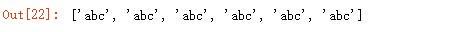
6. 匹配模式参数
忽略大小写,对比加与不加的匹配差异:
输出结果: 
输出结果: 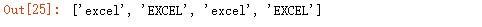
改变.的行为,用于匹配所有字符,包括换行符。不添加 re.S 时,当出现\n 时,被判定不符合要求,不进行匹配:
输出结果: 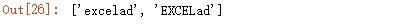
添加之后,可匹配换行符。不同匹配规则之间,用竖线连接:
输出结果: 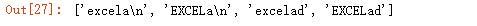
7. 替换字符
将字符串中 excel 替换为 ppt:
输出结果: 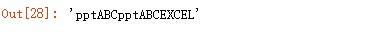
第四个参数传入 1,表明只替换 1 次:
输出结果: 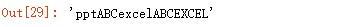
替换值可以为定义的函数名,定义函数返回的为空,所以是将 s9 中的 excel 替换为空:
输出结果: 
在正则表达式中用于获取分段截获的字符串,下例中为获取到 FBI:
输出结果: 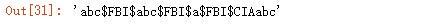
定义函数,对字符串中 0-4 的数字替换为 0,5-9 的数字替换为 9:
输出结果: 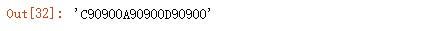
8. 分组
search 遍历字符串,找到正则表达式匹配的第一个位置:
输出结果: 
group() 与 group(0)相同,用于匹配正则表达式整体结果:
输出结果: 
group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分: 
完整正则匹配:
输出结果: 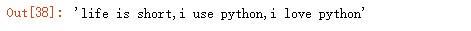
第一个分组的值:
输出结果: 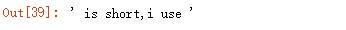
第二分组的值:
输出结果: 
以上便是 Python 中常用的正则表达式匹配规则,用于处理字符串非常方便。
