没什么可解释的,接下来,便应该是整理阶段了。我们来看当整理阶段处理完以后,内存的布局是如何的,如下图。
激活码:
激活码在线下载地址:www.sigusoft.com
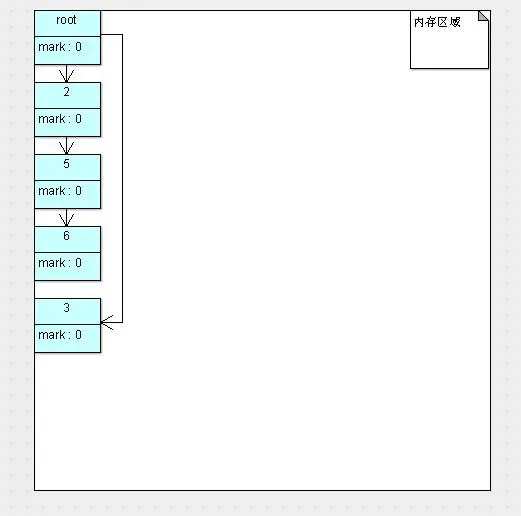
可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
不难看出,标记/整理算法不仅可以弥补标记/清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价,可谓是一举两得,一箭双雕,一石两鸟,一。。。。一女两男?
不过任何算法都会有其缺点,标记/整理算法唯一的缺点就是效率也不高,不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。
算法总结
这里LZ给各位总结一下三个算法的共同点以及它们各自的优势劣势,让各位对比一下,想必会更加清晰。
它们的共同点主要有以下两点。
1、三个算法都基于根搜索算法去判断一个对象是否应该被回收,而支撑根搜索算法可以正常工作的理论依据,就是语法中变量作用域的相关内容。因此,要想防止内存泄露,最根本的办法就是掌握好变量作用域,而不应该使用前面内存管理杂谈一章中所提到的C/C++式内存管理方式。
2、在GC线程开启时,或者说GC过程开始时,它们都要暂停应用程序(stop the world)。
它们的区别LZ按照下面几点来给各位展示。(>表示前者要优于后者,=表示两者效果一样)
效率:复制算法>标记/整理算法>标记/清除算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。
内存整齐度:复制算法=标记/整理算法>标记/清除算法。
内存利用率:标记/整理算法=标记/清除算法>复制算法。
可以看到标记/清除算法是比较落后的算法了,但是后两种算法却是在此基础上建立的,俗话说“吃水不忘挖井人”,因此各位也莫要忘记了标记/清除这一算法前辈。而且,在某些时候,标记/清除也会有用武之地。
