PYTHON 相关面试题170题(大部分含答案)
基础部分
1.列出 5 个常用 Python 标准库?
os:提供了不少与操作系统相关联的函数
sys: 通常用于命令行参数
re: 正则匹配
math: 数学运算
datetime:处理日期时间
2.Python 内建数据类型有哪些?
int、bool、 str、 list、 tuple、 dict
3.简述 with 方法打开处理文件帮我我们做了什么?
打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的f.open
写法,我们需要try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行finally f.close()关闭文件,with方法帮我们实现了finally中f.close
(当然还有其他自定义功能,有兴趣可以研究with方法源码)
4.列出 Python 中可变数据类型和不可变数据类型,为什么?
可变类型(mutable):变量进行append、+=等这种操作后 == 改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。listdictsetbytearrayuser-defined classes (除非是特别定义的不可变)
不可变类型(immutable):改变了变量的值 == 新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址), python的 方法让你明白 int float decimal complex bool string tuple range frozenset bytes
例子:
``` # -- coding: utf-8 --
# 不可变类型 a = 3 b = 3 print(id(a)) print(id(b))
# 可变类型 c = [1,2,3] d = [1,2,3] print(id(c)) print(id(d)) ```
5.Python 获取当前日期?
6.统计字符串每个单词出现的次数
7.用 python 删除文件和用 linux 命令删除文件方法
python:os.remove(文件名) linux: rm 文件名
8.写一段自定义异常代码
9.举例说明异常模块中 try except else finally 的相关意义
try..except..else没有捕获到异常,执行else语句
try..except..finally不管是否捕获到异常,都执行finally语句
10.遇到 bug 如何处理
百度,问人
语言特性
1.谈谈对 Python 和其他语言的区别
三个方面:
语言特点: 简洁优雅,省略了各种大括号和分号,还有一些关键字,类型说明
语言类型: 解释型语言,运行的时候是一行一行的解释并运行,所以调试代码很方便,开发效率高
第三方库: python是开源的,并且python的定位时任由其发展,应用领域很多比如Web,运维,自动化测试,爬虫,数据分析,人工智能.Python具有非常完备的第三方库
一句话概括:Python是一门语法简洁优美,功能强大无比,应用领域非常广泛,具有强大完备的第三方库的一门弱类型的可移植,可扩展,可嵌入的解释型编程语言
2.简述解释型和编译型编程语言
解释型:就是边解释边执行 编译性:编译后再执行
3.Python 的解释器种类以及相关特点?
CPython
由C语言开发的 使用最广的解释器,在命名行下运行python,就是启动CPython解释器.
IPython
基于cpython之上的一个交互式计时器 交互方式增强 功能和cpython一样
PyPy
目标是执行效率 采用JIT技术 对python代码进行动态编译,提高执行效率
JPython
运行在Java上的解释器 直接把python代码编译成Java字节码执行
IronPython
在微软 .NET 平台上的解释器,把python编译成. NET 的字节码
4.说说你知道的Python3 和 Python2 之间的区别?
py2:print语句,语句就意味着可以直接跟要打印的东西,如果后面接的是一个元组对象,直接打印
py3:print函数,函数就以为这必须要加上括号才能调用,如果接元组对象,可以接收多个位置参数,并可以打印
如果希望在 Python2 中 把 print 当函数使用,那么可以导入 future 模块 中的 print_function
下面有个示例:
输入函数
py2:input_raw()
py3:input()在使用super()的不同
py2:必须显示的在参数中写上基类
py:直接无参数调用即可1/2的结果
py2:返回0
py3:返回0.5,没有了int和long的区别编码
py2:默认编码ascii
py3:默认编码utf-8
而且为了在py2中使用中文,在头部引入coding声明,不推荐使用字符串
py2:unicode类型表示字符串序列,str类型表示字节序列
py3::str类型表示字符串序列,byte类型表示字节序列True和False
py2:True 和 False 在 Python2 中是两个全局变量,可以为其赋值或者进行别的操作,初始数值分别为1和0,虽然修改是违背了python设计的原则,但是确实可以更改
py3:修正了这个变量,让True或False不可变迭代器
py2:当中许多返回列表的方法,如range,字典对象的 dict.keys()、dict.values() 方法, map、filter、zip;并且迭代器必须实现next方法
py3:将返回列表的方法改为了返回迭代器对象,内置了next,不用特意去实现nextnonlocal
py2:没有办法在嵌套函数中将变量声明为一个非局部变量,只能在函数中声明全局变量
py3:nonlocal方法实现了,示例如下:
5.Python3 和 Python2 中 int 和 long 区别?
python2中有long类型 python3中没有long类型,只有int类型
6.xrange 和 range 的区别?
两种用法介绍如下: 1.range([start], stop[, step]) 返回等差数列。构建等差数列,起点是start,终点是stop,但不包含stop,公差是step。 start和step是可选项,没给出start时,从0开始;没给出step时,默认公差为1。 例如:
2.xrange([start], stop[, step]) xrange与range类似,只是返回的是一个"xrange object"对象,而非数组list。 要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间。 例如:
区别如下: 1.range和xrange都是在循环中使用,输出结果一样。 2.range返回的是一个list对象,而xrange返回的是一个生成器对象(xrange object)。 3.xrange则不会直接生成一个list,而是每次调用返回其中的一个值,内存空间使用极少,因而性能非常好。两种用法介绍如下: 1.range([start], stop[, step]) 返回等差数列。构建等差数列,起点是start,终点是stop,但不包含stop,公差是step。 start和step是可选项,没给出start时,从0开始;没给出step时,默认公差为1。 例如:
2.xrange([start], stop[, step]) xrange与range类似,只是返回的是一个"xrange object"对象,而非数组list。 要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间。 例如:
区别如下: 1.range和xrange都是在循环中使用,输出结果一样。 2.range返回的是一个list对象,而xrange返回的是一个生成器对象(xrange object)。 3.xrange则不会直接生成一个list,而是每次调用返回其中的一个值,内存空间使用极少,因而性能非常好。
编码规范
7.什么是 PEP8?
《Python Enhancement Proposal #8》又称之为Python 代码格式而编订的风格指南
8.了解 Python 之禅么?
开交互界面 输入import this 回车就OK了。
9.了解 docstring 么?
在软件工程中,其实编码所占的部分是非常小的,大多是其它的事情,比如写文档。文档是沟通的工具。 在python中,比较推崇在代码中写文档,代码即文档,比较方便,容易维护,直观,一致。 代码写完,文档也出来了。其实Markdown也差不多这种思想,文本写完,排版也完成了。
简单来说,就是出现在模块、函数、类、方法里第一个语句的,就是docstring。会自动变成属性doc。
可通过foo.doc访问得到’ This is function foo’.
10.了解类型注解么?
类型注解介绍 我们知道 Python 是一种动态语言,变量以及函数的参数是不区分类型。 Python解释器会在运行的时候动态判断变量和参数的类型,这样的好处是编写代码速度很快,很灵活,但是坏处也很明显,不好维护,可能代码写过一段时间重新看就很难理解了,因为那些变量、参数、函数返回值的类型,全都给忘记了。 而且当你在读别人的代码的时候,也无法一眼看出变量或者参数的类型,经常要自己推敲,这样给学习带来了很大的障碍。 所以Python3里有了这个新特性,可以给参数、函数返回值和变量的类型加上注解,不过这个仅仅是注释而已,对代码的运行来说没有任何影响,变量的真正类型还是会有Python解释器来确定,你所做的只是在提高代码的可读性,仅此而已。
11.例举你知道 Python 对象的命名规范,例如方法或者类等
module_name, 模块
package_name, 包
ClassName, 类
method_name, 方法
ExceptionName, 异常
function_name, 函数
GLOBAL_VAR_NAME, 全局变量
instance_var_name, 实例
function_parameter_name, 参数
local_var_name. 本变量
12.Python 中的注释有几种?
1.python单行注释符号(#) 2.批量、多行注释符号。多行注释是用三引号''' '''包含的
3.对于函数还有文档注释
为函数添加文档注释,需要在函数头(包含def关键字的那一行)的下一行用一对单引号或双引号将注释括起来。
13.如何优雅的给一个函数加注释?
见12文档注释
14.如何给变量加注释?
变量的声明同一行加上#的注释
15.Python 代码缩进中是否支持 Tab 键和空格混用。 16.是否可以在一句 import 中导入多个库?
支持,但是不提倡
17.在给 Py 文件命名的时候需要注意什么?
1.模块名和包名采用小写字母并且以下划线分隔单词的形式; 如:regex_syntax,py_compile,_winreg 2.类名或异常名采用每个单词首字母大写的方式; 如:BaseServer,ForkingMixIn,KeyboardInterrupt 3.全局或者类常量,全部使用大写字母,并且以下划线分隔单词; 如:MAX_LOAD 4.其余变量命名包括方法名,函数名,普通变量名则是采用全部小写字母,并且以下划线分隔单词的形式命名。 如:my_thread 5.以上的内容如果是内部的,则使用下划线开头命名。 如:init,new
18.例举几个规范 Python 代码风格的工具
PyCharm,vscode
数据类型
19.列举 Python 中的基本数据类型? 20.如何区别可变数据类型和不可变数据类型
可变数据类型:在id不变的情况下,value可改变(列表和字典是可变类型,但是字典中的key值必须是不可变类型)
不可变数据类型:value改变,id也跟着改变。(数字,字符串,布尔类型,都是不可类型)
21.将"hello world"转换为首字母大写"Hello World"
22.如何检测字符串中只含有数字?
23.将字符串"ilovechina"进行反转
24.Python 中的字符串格式化方式你知道哪些?
1、最传统的用%格式化字符串
“Hello, %s. You are %s.” % (name, age)
2、string.format ()
“Hello,{}. You are {}”.format(name,age)
3、f-string python3.6诞生的新方法
该方法叫做“F字符串方法”,又称为“格式化字符串文字”。F字符串是开头有一个f的字符串文字,以及包含表达式的大括号将被其值替换。表达式在运行时进行渲染,然后使用format协议进行格式化。
f’his name is {name}’
25.有一个字符串开头和末尾都有空格,比如“ adabdw ”,要求写一个函数把这个字符串的前后空格都去掉。
26.获取字符串”“最后的两个字符。
27.一个编码为 GBK 的字符串 ,要将其转成 UTF-8 编码的字符串,应如何操作?
str.encode("GBK") str.encode("UTF-8") (1)s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong'] ``` -- coding: utf-8 -- import re s="info:xiaoZhang 33 shandong" def reStr1(s): return re.split(r'[\s\:\:]+', s) print(reStr1(s)) ``` (2)a = "你好 中国 ",去除多余空格只留一个空格。 (1)怎样将字符串转换为小写
s2.upper()(2)单引号、双引号、三引号的区别?
单引号和双引号平时使用时候,是没有太多区别的。但是在定义字符串时候,可以单双引号混用来避免转义问题。 三引号作用:
-可以作为格式化输出
-可以作为多行注释
列表
30.已知 AList = [1,2,3,1,2],对 AList 列表元素去重,写出具体过程。
list(set(list)) --先将列表转化为set,再转化为list就可以实现去重操作
31.如何实现 "1,2,3" 变成 ["1","2","3"]
32.给定两个 list,A 和 B,找出相同元素和不同元素
利用集合:
33.[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
l1 = [[1,2],[3,4],[5,6]] l = [j for t in l1 for j in t]
34.合并列表[1,5,7,9]和[2,2,6,8]
35.如何打乱一个列表的元素?
字典
36.字典操作中 del 和 pop 有什么区别?
del 可以删除指定key的键值对,并且没有返回。用法:del dict[key]; 也可以使用del来清空整个字典 pop是从字典中取走指定key的键值对,并且返回键值。是字典的一个方法。用法:dict.pop(key)
37.按照字典的内的数值排序
38.请合并下面两个字典 a = {"A":1,"B":2},b = {"C":3,"D":4}
39.如何使用生成式的方式生成一个字典,写一段功能代码。
40.如何把元组("a","b")和元组(1,2),变为字典{"a":1,"b":2}
41.Python 常用的数据结构的类型及其特性?
一、基础数据类型
标准数据类型:
·不可变数据类型
Number(数字):int、float、bool、complex(复数)
String(字符串)
Tuple(元祖):不可变,无法通过下标来修改值
·可变数据类型
List(列表):[ ]
Set(集合):{ }
Dictionary(字典):{ key:value}
可变数据类型:当值改变时,id编号不变化【可以使用id()函数来查看】
不可变数据类型:当值改变时,会产生新的id编号
二、基本数据结构(列表、集合、字典、元祖):
· 列表(list):
特点:是一个可变集合,不仅结构可变,里面还可以放不同类型的对象:num = [1,2,3,‘123’,True,321]
常规操作:
·获取元素:可以通过下标获取:num[0],输出:1
可以通过切片获取:num[3:5],输出:'123',321
·添加元素:
num.append(3):在列表后方添加元素
num.insert(index,value):插入到列表的指定位置 num + [1,2,3] 或 num.extend([1,2,3]):连接两个列表
·元祖(tuple)
特点:不可变
常规操作:
·可以通过下标取值,但无法修改
·可以通过 index(value1,value2) 来获取制定元素在元祖中出现的位置
·可以通过count(value) 来统计指定元素在元祖中出现的个数
·集合({ })
特点:集合是一个无序不重复元素的集
常规操作:
推导式:
42.如何交换字典 {"A":1,"B":2}的键和值?
43.Python 里面如何实现 tuple 和 list 的转换?
list(tup) tuple(list)
44.我们知道对于列表可以使用切片操作进行部分元素的选择,那么如何对生成器类型的对象实现相同的功能呢?
这个题目考察了 Python 标准库的itertools模快的掌握情况,该模块提供了操作生成器的一些方法。 对于生成器类型我们使用islice方法来实现切片的功能。例子如下
45.请将[i for i in range(3)]改成生成器
直接将中括号改成小括号就行了
(i for i in range(3))
46.a="hello"和 b="你好"编码成 bytes 类型
47.下面的代码输出结果是什么?

48.下面的代码输出的结果是什么?
(1, 2, 3, [2, 5, 6, 7], 8)
49.Python 交换两个变量的值
50.在读文件操作的时候会使用 read、readline 或者 readlines,简述它们各自的作用
1)read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,输出的结果是字符串对象 2)readline():每次读出一行内容,所以,读取时占用内存小,比较适合大文件,输出的结果也是一个字符串对象。 3)readlines():读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存。 总结:read和readline返回的是字符串,而readlines返回的是列表,其中每行是作为列表的一个元素。
51.json 序列化时,可以处理的数据类型有哪些?如何定制支持 datetime
1、可以处理的数据类型是 string、int、list、tuple、dict、bool、null 2、自定义时间序列化转换器
52.json 序列化时,默认遇到中文会转换成 unicode,如果想要保留中文怎么办?
53.有两个磁盘文件 A 和 B,各存放一行字母,要求把这两个文件中的信息合并(按字母顺序排列),输出到一个新文件 C 中。
54.如果当前的日期为 ,要求写一个函数输出 N 天后的日期,(比如 N 为 2,则输出 )。
55.写一个函数,接收整数参数 n,返回一个函数,函数的功能是把函数的参数和 n 相乘并把结果返回。
56.下面代码会存在什么问题,如何改进?

无法编译通过。 将函数内的str变量换为其他名称即可
57.一行代码输出 1-100 之间的所有偶数。
58.with 语句的作用,写一段代码?
59.python 字典和 json 字符串相互转化方法
在Python中自带json库。通过import json导入。 在json模块有2个方法, loads():将json数据转化成dict数据 dumps():将dict数据转化成json数据 load():读取json文件数据,转成dict数据 dump():将dict数据转化成json数据后写入json文件
60.请写一个 Python 逻辑,计算一个文件中的大写字母数量
请写一段 Python连接 Mongo 数据库,然后查询的代码。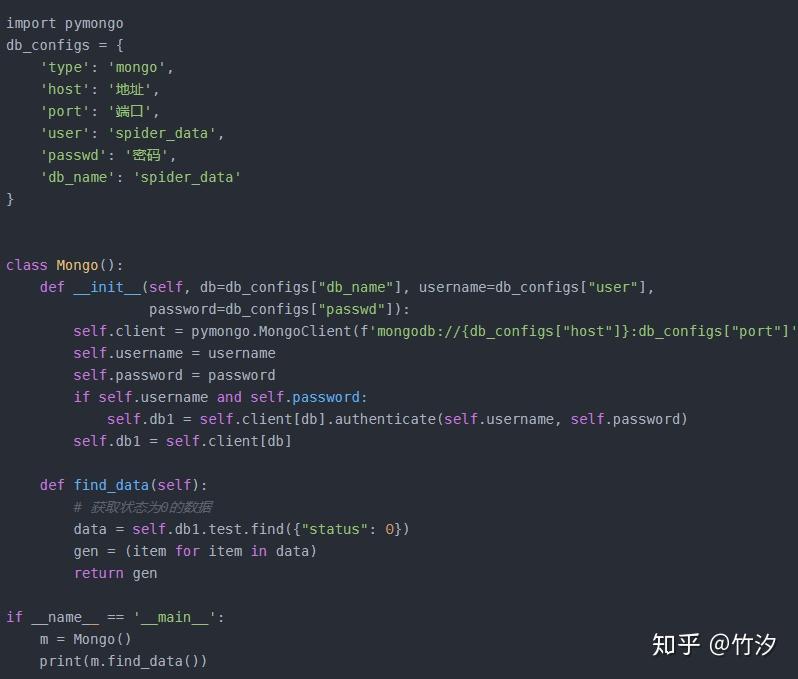
说一说 Redis 的基本类型。
redis是一个key-value存储系统,和Memcache类似,它支持存储的value类型相对更多,包括string(字符串),list(链表),set(集合),zset(有序集合),hash(哈希类型)。这些数据类型都支持push/pop,add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在次基础上,redis支持各种不同方式的排序,与memcached一样,为了保证效率,数据都是缓冲在内存中。区别是redis会周期性的把更新的数据写入磁盘或把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
备注:默认redis有16个数据库,即db0~db15, 一般存取数据如果不指定库的话,默认都是存在db0中。 Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。请写一段 Python连接 Redis 数据库的代码
``` import redis # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库
r = redis.Redis(host='localhost', port=6379, decode_responses=True) # host是redis主机,需要redis服务端和客户端都启动 redis默认端口是6379 r.set('name', 'junxi') # key是"foo" value是"bar" 将键值对存入redis缓存 print(r['name']) print(r.get('name')) # 取出键name对应的值 print(type(r.get('name'))) ```写一段 Python 连接 MySQL 数据库的代码。
了解 Redis 的事务么?
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
批量操作在发送 EXEC 命令前被放入队列缓存。 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。 一个事务从开始到执行会经历以下三个阶段:
开始事务。 命令入队。 执行事务。了解数据库的三范式么?
1.第一范式(确保每列保持原子性) 第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。 2.第二范式(确保表中的每列都和主键相关) 第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中 3.第三范式(确保每列都和主键列直接相关,而不是间接相关) 第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。 了解分布式锁么? 用 Python 实现一个 Reids 的分布式锁的功能。 写一段 Python 使用 Mongo 数据库创建索引的代码。
70.函数装饰器有什么作用?请列举说明?
python装饰器本质上就是一个函数,它可以让其他函数在不需要做任何代码变动的前提下增加额 外的功能,装饰器的返回值也是一个函数对象(函数的指针)。
71.Python 垃圾回收机制?
python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略。
引用计数机制的优点:
简单 实时性:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
引用计数机制的缺点: 维护引用计数消耗资源 循环引用 list1 = [] list2 = [] list1.append(list2) list2.append(list1)
list1与list2相互引用,如果不存在其他对象对它们的引用,list1与list2的引用计数也仍然为1,所占用的内存永远无法被回收,这将是致命的。 对于如今的强大硬件,缺点1尚可接受,但是循环引用导致内存泄露,注定python还将引入新的回收机制。(标记清除和分代收集)
72.魔法函数 call怎么使用?
可以将一个类实例变成一个可调用对象,在这个类实例中实现__call__方法就好了。
73.如何判断一个对象是函数还是方法?
用内置的isinstance 来判断
74.@classmethod 和@staticmethod 用法和区别
75.Python 中的接口如何实现?
什么是接口 ?
接口只是定义了一些方法,而没有去实现,多用于程序设计时,只是设计需要有什么样的功能,但是并没有实现任何功能,这些功能需要被另一个类(B)继承后,由 类B去实现其中的某个功能或全部功能。
方法一:用抽象类和抽象函数实现方法(适用于单继承)
方法二:用普通类定义接口(推荐)
76.Python 中的反射了解么?
什么是反射机制呢?
反射就是通过字符串的形式,导入模块;通过字符串的形式,去模块寻找指定函数,并执行。利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
77.metaclass 作用?以及应用场景?
元类
78.hasattr() getattr() setattr()的用法
hasattr(object, name)
判断一个对象里面是否有name属性或者name方法,返回BOOL值,有name特性返回True, 否则返回False。
getattr(object, name[,default])
获取对象object的属性或者方法,如果存在打印出来,如果不存在,打印出默认值,默认值可选。
需要注意的是,如果是返回的对象的方法,返回的是方法的内存地址,如果需要运行这个方法,可以在后面添加一对括号。
setattr(object, name, values)
给对象的属性赋值,若属性不存在,先创建再赋值。
一种综合的用法是:判断一个对象的属性是否存在,若不存在就添加该属性。
79.请列举你知道的 Python 的魔法方法及用途。
del
call
repr
new
str
init
[python魔法方法总结]
80.如何知道一个 Python 对象的类型?
type()
81.Python 的传参是传值还是传址?
传值:被调函数局部变量改变不会影响主调函数局部变量 传址:被调函数局部变量改变会影响主调函数局部变量
Python参数传递采用的肯定是“传对象引用”的方式。实际上,这种方式相当于传值和传址的一种综合。
如果函数收到的是一个可变对象(比如字典或者列表)的引用,就能修改对象的原始值——相当于传址。如果函数收到的是一个不可变对象(比如数字、字符或者元组)的引用(其实也是对象地址!!!),就不能直接修改原始对象——相当于传值。
所以python的传值和传址是比如根据传入参数的类型来选择的
传值的参数类型:数字,字符串,元组(immutable)
传址的参数类型:列表,字典(mutable)
82.Python 中的元类(metaclass)使用举例
83.简述 any()和 all()方法
any函数非常简单:判断一个tuple或者list是否全为空,0,False。如果全为空,0,False,则返回False;如果不全为空,则返回True。
all函数正好和any相反:判断一个tuple或者list是否全为不为空,0,False。如果全不为空,则返回True;否则返回False。
84.filter 方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
85.什么是猴子补丁?
猴子补丁的叫法有些莫名其妙,只要和“模块运行时替换的功能”对应就行了。
Monkey patch就是在运行时对已有的代码进行修改,达到hot patch的目的
86.在 Python 中是如何管理内存的?
Python引用了一个内存池(memory pool)机制,即Pymalloc机制(malloc:n.分配内存),用于管理对小块内存的申请和释放 内存池(memory pool)的概念: 当 创建大量消耗小内存的对象时,频繁调用new/malloc会导致大量的内存碎片,致使效率降低。内存池的概念就是预先在内存中申请一定数量的,大小相等 的内存块留作备用,当有新的内存需求时,就先从内存池中分配内存给这个需求,不够了之后再申请新的内存。这样做最显著的优势就是能够减少内存碎片,提升效率。 内存池的实现方式有很多,性能和适用范围也不一样。 python中的内存管理机制——Pymalloc: python中的内存管理机制都有两套实现,一套是针对小对象,就是大小小于256bits时,pymalloc会在内存池中申请内存空间;当大于256bits,则会直接执行new/malloc的行为来申请内存空间。 关于释放内存方面,当一个对象的引用计数变为0时,python就会调用它的析构函数。在析构时,也采用了内存池机制,从内存池来的内存会被归还到内存池中,以避免频繁地释放动作。
87.当退出 Python 时是否释放所有内存分配?
答案是no,循环引用其他对象或引用自全局命名空间的对象的模块,在python退出时并非完全释放
另外,也不会释放c库保留的内存部分
91.解释一下 python 中 pass 语句的作用?
1、空语句,什么也不做 2、在特别的时候用来保证格式或是语义的完整性
92.简述你对 input()函数的理解
在 Python3 中,input()获取用户输入,不论用户输入的是什么,获取到的都是字符串类型的。
在 Python2 中有 raw_input()和 input(), raw_input()和 Python3 中的 input()作用是一样的, input()输入的是什么数据类型的,获取到的就是什么数据类型的。
93.python 中的 is 和==
在讲is和==这两种运算符区别之前,首先要知道Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
is和==都是对对象进行比较判断作用的,但对对象比较判断的内容并不相同。下面来看看具体区别在哪。
==比较操作符和is同一性运算符区别
==是python标准操作符中的比较操作符,用来比较判断两个对象的value(值)是否相等
is也被叫做同一性运算符,这个运算符比较判断的是对象间的唯一身份标识,也就是id是否相同。
94.Python 中的作用域
95.三元运算写法和应用场景?
96.了解 enumerate 么?
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
97.列举 5 个 Python 中的标准模块
98.如何在函数中设置一个全局变量
使用global关键字
99.pathlib 的用法举例
内置模块,用于pathlib中的Path类可以创建path路径对象, 属于比os.path更高抽象级别的对象
100.Python 中的异常处理,写一个简单的应用场景
101.Python 中递归的最大次数,那如何突破呢?
1000次
102.什么是面向对象的 mro
MRO的全称是Method Resolution Order(方法解析顺序),它指的是对于一棵类继承树,当调用最底层类对象所对应实例对象的方法时,Python解释器在继承树上搜索方法的顺序。
对于一棵类继承树,可以调用最底层类对象的方法mro()或访问最底层类对象的特殊属性 mro ,获得这颗类继承树的MRO。
在子类重写后的方法通过super()调用父类被重写的方法时,在父类中搜索方法的顺序基于以该子类为最底层类对象的类继承树的MRO。 如果想调用指定父类中被重写的方法,可以给super()传入两个实参:super(a_type, obj),其中,第一个实参a_type是个类对象,第二个实参obj是个实例对象,这样,被指定的父类是: obj所对应类对象的MRO中,a_type后面的那个类对象。
103.isinstance 作用以及应用场景?
判断类的继承关系。
104.什么是断言?应用场景?
Python的assert是用来检查一个条件,如果它为真,就不做任何事。如果它为假,则会抛出AssertError并且包含错误信息。
那什么时候应该使用assert?没有特定的规则,断言应该用于:
☆防御型的编程 ☆运行时检查程序逻辑 ☆检查约定 ☆程序常量 ☆检查文档
105.lambda 表达式格式以及应用场景?
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数 函数名 = lambda 参数 :返回值
106.新式类和旧式类的区别
107.dir()是干什么用的?
使用dir()函数可以查看对像内所有属于及方法,在python中任何东西都是对象,一种数据类型,一个模块等,都有自己的属性和方法,除了常用方法外,其它的你不需要全部记住它,交给dir()函数就好了。
108.一个包里有三个模块,demo1.py, demo2.py, demo3.py,但使用 from tools import 导入模块时,如何保证只有 demo1、demo3 被导入了。增加_init_.py 文件,并在文件中增加:--all-- = ['demo1','demo3']
109.列举 5 个 Python 中的异常类型以及其含义
AttributeError 对象没有这个属性
NotImplementedError 尚未实现的方法
StopIteration 迭代器没有更多的值
TypeError 对类型无效的操作
IndentationError 缩进错误
110.copy 和 deepcopy 的区别是什么?
copy 和deepcopy就是浅复制和深复制
我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。
对于简单的 object,用 shallow copy 和 deep copy 没区别
复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。
111.代码中经常遇到的args, *kwargs 含义及用法。
*arg代表任意个位置参数,kwargs代表任意个关键字参数,使用顺序为def 函数名(位置参数,args,默认参数,**kwargs),即arg一定在kwargs之前。
112.Python 中会有函数或成员变量包含单下划线前缀和结尾,和双下划线前缀结尾,区别是什么?
“单下划线” 开始的成员变量叫做保护变量,意思是只有类对象和子类对象自己能访问到这些变量; “双下划线” 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。
113.w、a+、wb 文件写入模式的区别
r : 读取文件,若文件不存在则会报错
w: 写入文件,若文件不存在则会先创建再写入,会覆盖原文件
a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
rb,wb:分别于r,w类似,但是用于读写二进制文件
r+ : 可读、可写,文件不存在也会报错,写操作时会覆盖
w+ : 可读,可写,文件不存在先创建,会覆盖
a+ :可读、可写,文件不存在先创建,不会覆盖,追加在末尾
114.举例 sort 和 sorted 的区别、
sort()与sorted()的不同在于,sort是在原位重新排列列表,而sorted()是产生一个新的列表。
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
对于一个无序的列表a,调用a.sort(),对a进行排序后返回a,sort()函数修改待排序的列表内容。而对于同样一个无序的列表a,调用sorted(a),对a进行排序后返回一个新的列表,而对a不产生影响。
115.什么是负索引?
负索引是从右边开始检索的,一般用于列表中的切片造作
116.pprint 模块是干什么的?
pprint模块 提供了打印出任何Python数据结构类和方法。
117.解释一下 Python 中的赋值运算符
118.解释一下 Python 中的逻辑运算符
python中有三个逻辑运算符:and、or、not
119.讲讲 Python 中的位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13,二进制格式如下:

120.在 Python 中如何使用多进制数字?
1、二进制数字由0和1组成,我们使用0b或0B前缀表示二进制数
2、使用bin()函数将一个数字转换为它的二进制形式
3、八进制数由数字0-7组成,用前缀0o或0O表示8进制数
4、十六进数由数字0-15组成,用前缀0x或者0X表示16进制数
121.怎样声明多个变量并赋值?
122.已知:
123.用 Python 实现一个二分查找的函数
124.python 单例模式的实现方法
单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
实现单例的五种方式:
使用模块
使用装饰器
使用类
基于——new——方法实现(推荐使用,方便)
基于metaclass方式实现
125.使用 Python 实现一个斐波那契数列
126.找出列表中的重复数字
127.找出列表中的单个数字
128.写一个冒泡排序
129.写一个快速排序
130.写一个拓扑排序
131.python 实现一个二进制计算
132.有一组“+”和“-”符号,要求将“+”排到左边,“-”排到右边,写出具体的实现方法。
133.单链表反转
134.交叉链表求交点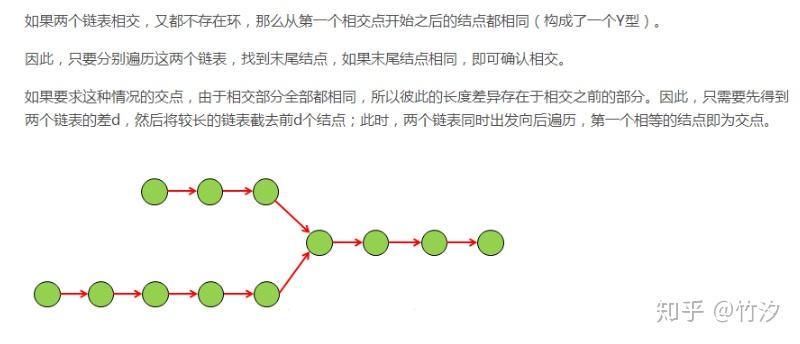
135.用队列实现栈
136.找出数据流的中位数
137.二叉搜索树中第 K 小的元素
爬虫相关
138.在 requests 模块中,requests.content 和 requests.text 什么区别
139.简要写一下 lxml 模块的使用方法框架
lxml是处理网页数据的第三方库,用Cython实现。
140.说一说 scrapy 的工作流程
141.scrapy 的去重原理
142.scrapy 中间件有几种类,你用过哪些中间件
scrapy的中间件理论上有三种(Schduler Middleware,Spider Middleware,Downloader Middleware),在应用上一般有以下两种
1.爬虫中间件Spider Middleware
主要功能是在爬虫运行过程中进行一些处理.
2.下载器中间件Downloader Middleware
主要功能在请求到网页后,页面被下载时进行一些处理.
143.你写爬虫的时候都遇到过什么反爬虫措施,你是怎么解决的?
静态页面
动态页面
144.为什么会用到代理?
145.代理失效了怎么处理?
146.列出你知道 header 的内容以及信息
147.说一说打开浏览器访问 百度一下,你就知道 获取到结果,整个流程。
148.爬取速度过快出现了验证码怎么处理
149.scrapy 和 scrapy-redis 有什么区别?为什么选择 redis 数据库?
150.分布式爬虫主要解决什么问题
151.写爬虫是用多进程好?还是多线程好? 为什么?
152.解析网页的解析器使用最多的是哪几个
153.需要登录的网页,如何解决同时限制 ip,cookie,session(其中有一些是动态生成的)在不使用动态爬取的情况下?
154.验证码的解决(简单的:对图像做处理后可以得到的,困难的:验证码是点击,拖动等动态进行的?)
155.使用最多的数据库(mysql,mongodb,redis 等),对他的理解?
网络编程
156.TCP 和 UDP 的区别?TCP 是面向连接的,UDP 是面向无连接的UDP程序结构较简单TCP 是面向字节流的,UDP 是基于数据报的TCP 保证数据正确性,UDP 可能丢包TCP 保证数据顺序,UDP 不保证
要想理解 TCP 和 UDP 的区别,首先要明白什么是 TCP,什么是 UDP
TCP 和 UDP 是传输层的两个协议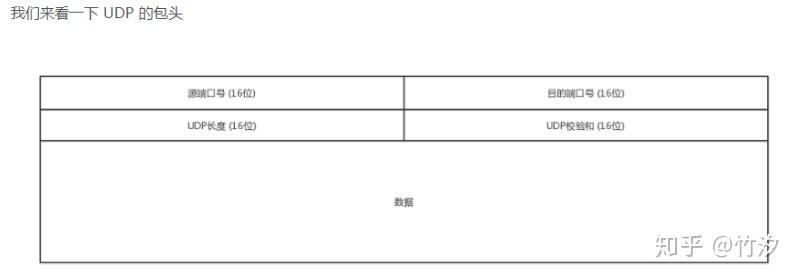
UDP 除了端口号,基本啥都没有了。如果没有这两个端口号,数据就不知道该发给哪个应用。
所以 UDP 就像一个小孩子,特别简单,有如下三个特点沟通简单,不需要大量的数据结构,处理逻辑和包头字段轻信他人。它不会建立连接,但是会监听这个地方,谁都可以传给它数据,它也可以传给任何人数据,甚至可以同时传给多个人数据。愣头青,做事不懂变通。不会根据网络的情况进行拥塞控制,无论是否丢包,它该怎么发还是怎么发
因为 UDP 是"小孩子",所以处理的是一些没那么难的项目,并且就算失败的也能接收。基于这些特点的话,UDP 可以使用在如下场景中
需要资源少,网络情况稳定的内网,或者对于丢包不敏感的应用,比如 DHCP 就是基于 UDP 协议的。 不需要一对一沟通,建立连接,而是可以广播的应用。因为它不面向连接,所以可以做到一对多,承担广播或者多播的协议。 需要处理速度快,可以容忍丢包,但是即使网络拥塞,也毫不退缩,一往无前的时候 基于 UDP 的几个例子
直播。直播对实时性的要求比较高,宁可丢包,也不要卡顿的,所以很多直播应用都基于 UDP 实现了自己的视频传输协议 实时游戏。游戏的特点也是实时性比较高,在这种情况下,采用自定义的可靠的 UDP 协议,自定义重传策略,能够把产生的延迟降到最低,减少网络问题对游戏造成的影响 物联网。一方面,物联网领域中断资源少,很可能知识个很小的嵌入式系统,而维护 TCP 协议的代价太大了;另一方面,物联网对实时性的要求也特别高。比如 Google 旗下的 Nest 简历 Thread Group,推出了物联网通信协议 Thread,就是基于 UDP 协议的
TCP: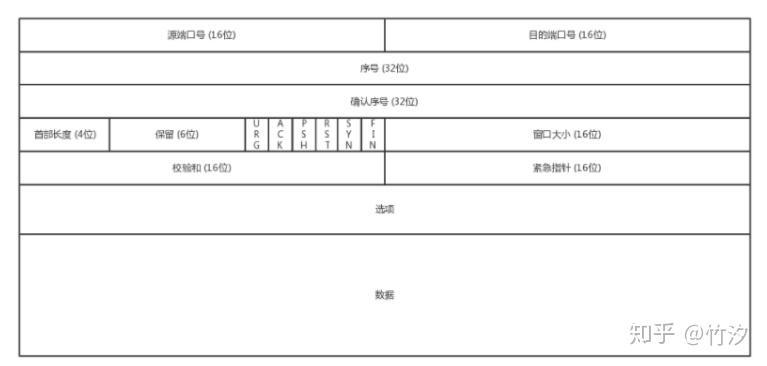
TCP 的包头有哪些内容,分别有什么用
首先,源端口和目标端口是不可少的。 接下来是包的序号。主要是为了解决乱序问题。不编好号怎么知道哪个先来,哪个后到 确认序号。发出去的包应该有确认,这样能知道对方是否收到,如果没收到就应该重新发送,这个解决的是不丢包的问题 状态位。SYN 是发起一个链接,ACK 是回复,RST 是重新连接,FIN 是结束连接。因为 TCP 是面向连接的,因此需要双方维护连接的状态,这些状态位的包会引起双方的状态变更 窗口大小,TCP 要做流量控制,需要通信双方各声明一个窗口,标识自己当前的处理能力。
什么是面向连接,什么是面向无连接
在互通之前,面向连接的协议会先建立连接,如 TCP 有三次握手,而 UDP 不会
TCP 为什么是可靠连接
通过 TCP 连接传输的数据无差错,不丢失,不重复,且按顺序到达。 TCP 报文头里面的序号能使 TCP 的数据按序到达 报文头里面的确认序号能保证不丢包,累计确认及超时重传机制 TCP 拥有流量控制及拥塞控制的机制 TCP 的顺序问题,丢包问题,流量控制都是通过滑动窗口来解决的 拥塞控制时通过拥塞窗口来解决的
157.简要介绍三次握手和四次挥手
TCP 的建立连接称为三次握手,可以简单理解为下面这种情况
所谓三次握手(Three-Way Handshake)即建立TCP连接,是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。在socket编程中,这一过程由客户端执行connect来触发
(1)第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
(2)第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack (number )=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
(3)第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。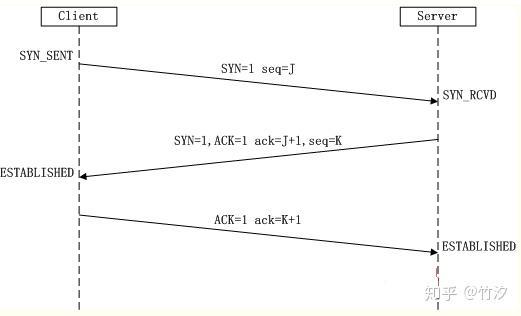 三次握手
三次握手
三次握手耳熟能详,四次挥手估计就..所谓四次挥手(Four-Way Wavehand)即终止TCP连接,就是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。在socket编程中,这一过程由客户端或服务端任一方执行close来触发,整个流程如下图所示: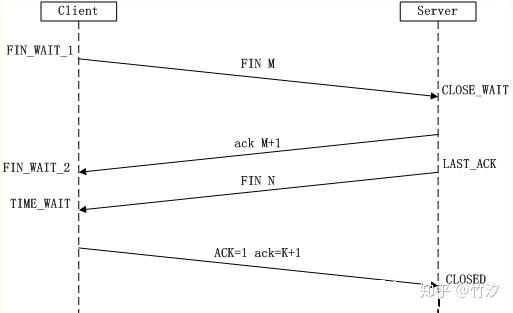 四次挥手
四次挥手
由于TCP连接时全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN。首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭,上图描述的即是如此。
(1)第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
(2)第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
(3)第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
(4)第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
这是因为服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而关闭连接时,当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即close,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送。
158.什么是粘包? socket 中造成粘包的原因是什么? 哪些情况会发生粘包现象?
1、粘包的概念 粘包:多个数据包被连续存储于连续的缓存中,在对数据包进行读取时由于无法确定发生方的发送边界,而采用某一估测值大小来进行数据读出,若双方的size不一致时就会使指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。
2、出现粘包的原因 出现粘包现象的原因是多方面的,它既可能由发送方造成,也可能由接收方造成。
发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一包数据。若连续几次发送的数据都很少,通常TCP会根据优化算法把这些数据合成一包后一次发送出去,这样接收方就收到了粘包数据。
接收方引起的粘包是由于接收方用户进程不及时接收数据,从而导致粘包现象。这是因为接收方先把收到的数据放在系统接收缓冲区,用户进程从该缓冲区取数据,若下一包数据到达时前一包数据尚未被用户进程取走,则下一包数据放到系统接收缓冲区时就接到前一包数据之后,而用户进程根据预先设定的缓冲区大小从系统接收缓冲区取数据,这样就一次取到了多包数据。
4、粘包的处理方式: (1)当时短连接的情况下,不用考虑粘包的情况 (2)如果发送数据无结构,如文件传输,这样发送方只管发送,接收方只管接收存储就ok,也不用考虑粘包 (3)如果双方建立长连接,需要在连接后一段时间内发送不同结构数据
接收方创建预处理线程,对接收到的数据包进行预处理,将粘连的包分开;
分包是指在出现粘包的时候我们的接收方要进行分包处理。(在长连接中都会出现) 数据包的边界发生错位,导致读出错误的数据分包,进而曲解原始数据含义。
粘包情况有两种,一种是粘在一起的包都是完整的数据包,另一种情况是粘在一起的包有不完整的包。
159.举例说明 conccurent.future 的中线程池的用法
160.说一说多线程,多进程和协程的区别。
161.简述 GIL
GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。
162.进程之间如何通信
1. 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2. 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
4. 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5. 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
6. 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
7. 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同进程间的进程通信。
8. 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
http://163.IO 多路复用的作用?
164.select、poll、epoll 模型的区别?
165.什么是并发和并行?
举个简单的例子:你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行.你吃饭吃到一半,电话来了,你停了下来接了电话,接完后电话以后继续吃饭,这说明你支持并发。
你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。 并行与并发的理解 并发:交替处理多个任务的能力; 并行:同时处理多个任务的能力; 并发的关键是你有处理多个任务的能力,不一定要同时。
并行的关键是你有同时处理多个任务的能力,强调的是同时.
所以它们最大的区别就是:是否是『同时』处理任务。
167.解释什么是异步非阻塞?
这篇文章想通过一个老王“候车”的案例来解释这概念。
同步阻塞
放假了,老王回到了乡下,由于乡下的基础设施比较差,当他在车站候车的时候,只能一直在干等着,直到公交车的到站。 这时候对于公交车(被调用着者)来说,它是“同步“的。老王(调用者)被公交车(被调用者)“阻塞”在站台上。
异步阻塞
放完假了,老王回到了大城市开始上班,同样在车站候车,一样在车站干等着,但是大城市的基础设施建设得比较好,当公交车到站的时候,会有广播提示提醒乘客。
那么这时候对于公交车(被调用着者)来说,它是“异步“的,到站后会通知调用者。但是此时老王(调用者)还是被公交车(被调用者)“阻塞”在站台上。
同步非阻塞
过年了,老王放假回来了乡下,又要开始候车了,这时候他变聪明了,没有一直在车站上干等着,而是去找隔壁的小花叙叙旧。但是又害怕车到站了自己会错过,就只能隔一段时间过来看看车到了没。
那么这时候对于公交车(被调用着者)来说,它是“同步“的。但是此时老王(调用者)可以在候车的时候去干其他的的事情,所以他是“非阻塞”的。
异步非阻塞
春风吹满地,新农村建设正在火热进行中,此时的乡下,公交车里面也安装了车辆到站的提醒广播。现在老王在候车的时候,可以安心的跟小花叙旧了,当听到自己需要乘坐的车辆到站广播时,才过去车站上车。
这时候对于公交车(被调用着者)来说,它是“异步“的,到站后会广播提醒,此时老王(调用者)可以在候车的时候去干其他的的事情,所以他是“非阻塞”的
从上面的示例中,我们可以明白一件事情,同步异步,阻塞非阻塞他们针对的对象是不一样的。对于调用者来说是阻塞跟非阻塞,被调用者是同步跟异步。
同步:A调用B,此时只有等B有结果了才返回。 异步: A调用B,B立即返回,无须等待。当B处理完之后会通过通知或者回调函数的方式来告诉A结果。 阻塞:A调用B,A会被被挂起,一直在等待B的结果,什么事都不能干。 非阻塞:A调用B,自己用被挂起等待B的结果,可以去干其他的事情。
168.threading.local 的作用?
为每个线程创建一个独立的空间,使得线程对自己的空间中的数据进行操作(数据隔离)
Git 面试题
169.说说你知道的 git 命令
git init
git clone
git status
git add
git commit
git push
git diff 查看文件修改内容
170.git 如何查看某次提交修改的内容
首先可以git log显示历史的提交列表
之后我们用git show 便可以显示某次提交的修改内容
同样 git show filename 可以显示某次提交的某个内容的修改信息。
