目录
- 1. Go语言本地缓存的实现
- 2. 锁竞争严重问题如何解决?
- 2.1 分片数量N如何选择?
- 2.2 hash函数如何选择?
- 3. 零GC的实现
- 3.1 使用堆外内存
- 3.2 map非指针优化
- 4. 内存占用和过期淘汰策略的抉择?
- 4.1 覆盖写 or 自动扩容?
- 4.2 数据过期需要支持吗?
- 5. 小结
1. Go语言本地缓存的实现
Go语言实现本地缓存是非常容易的,考虑到语言本身的特性,只要解决了“并发安全”问题,基本就可以在生产环境中使用了,常见的解决方案有两种:
- 使用 sync.Map
- 使用 map 配合 sync.RWMutex
Go语言内置的map是非并发数据安全的结构,对于缓存这种读多写少的业务,选择 sync.RWMutex 是比较合适的。sync.Map 则是采用了“空间换时间“的思路,在读多写少的缓存场景中,锁竞争的频率比 map + sync.RWMtex 更小。这两种方案实现本地缓存也都存在一些缺陷:
- 缓存对象很多时,锁竞争严重,性能急剧下降
- 大量缓存对象的写入导致gc扫描标记stw时间过长,cpu毛刺严重
- 内存占用不可控,缓存对象不支持按写入时间过期和淘汰
为了解决上述问题,大多数开发者会选择使用开源成熟的库;当然也可以自己开发一个库,前提是你要有解决这些问题的思路和过硬的编码能力。无论从哪个角度考虑,学习一下开源库的设计,读一下源码都是非常有收益的,下边就带着这几个问题结合bigcache、fastcache开源库的设计思路展开。
2. 锁竞争严重问题如何解决?
从实现上来讲,cache的实现本质上是一个并发安全的map,sync.RWMutex虽然对读写进行了优化,但对于写操作是串行执行的,缓存对象过多,写操作的频率也将变得不可控。一把大锁终究是问题的瓶颈所在,解决思路是将锁分片:将大的map拆分成小的map,每个小map配合一个sync.RWMutex做保护。bigcache 和 fastcache都采用了这种方式,bigcache中分片数量是可配置的。

fastcache更粗暴一点,直接硬编码写死了512个分片。
// source : https://github.com/VictoriaMetrics/fastcache/blob/master/fastcache.go
const bucketsCount = 512
type Cache struct {
buckets [bucketsCount]bucket
bigStats BigStats
}2.1 分片数量N如何选择?
关于N的选择,几乎所有相关的开源库都选择了2的幂,毕竟位运算相对于取模运算可是要快很多的。对于2的幂N,等式 x mod N = (x & (N − 1)) 成立。
下边是bigcache作者的实现:
// source : https://github.com/allegro/bigcache/blob/main/bigcache.go#L249
func (c *BigCache) Get(key string) ([]byte, error) {
hashedKey := c.hash.Sum64(key)
shard := c.getShard(hashedKey)
return shard.get(key, hashedKey)
}
func (c *BigCache) Set(key string, entry []byte) error {
hashedKey := c.hash.Sum64(key)
shard := c.getShard(hashedKey)
return shard.set(key, hashedKey, entry)
}
func (c *BigCache) getShard(hashedKey uint64) (shard *cacheShard) {
return c.shards[hashedKey&c.shardMask]
}fastcache的作者似乎并没有意识到这一点(也许觉得这点cpu不值一提),还是采用了取模的方法:
// source : https://github.com/VictoriaMetrics/fastcache/blob/master/fastcache.go
func (c *Cache) Set(k, v []byte) {
h := xxhash.Sum64(k)
idx := h % bucketsCount
c.buckets[idx].Set(k, v, h)
}
func (c *Cache) Get(dst, k []byte) []byte {
h := xxhash.Sum64(k)
idx := h % bucketsCount
dst, _ = c.buckets[idx].Get(dst, k, h, true)
return dst
}2.2 hash函数如何选择?
map查找时间复杂度是O(1),核心实现就在于hash函数。hash函数实现有很多,对于本地缓存应用场景来说,主要考虑的点有:
- 哈希值产生的速度,这是衡量hash函数好坏最关键的指标,越快越好。
- 哈希值的随机程度,产生的哈希值越随机越不容易产生hash冲突,查找性能就越好。
- 耗费资源情况(需要分配多少内存,对gc是否产生压力)。当然越小越好。
bigcache 默认采用了fnv64a算法。这个算法的好处是采用位运算的方式在栈上进行运算,避免在堆上分配。
// source : https://github.com/allegro/bigcache/blob/main/fnv.go
type fnv64a struct{}
const (
// offset64 FNVa offset basis. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hash
offset64 = 14695981039346656037
// prime64 FNVa prime value. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hash
prime64 = 1099511628211
)
// Sum64 gets the string and returns its uint64 hash value.
func (f fnv64a) Sum64(key string) uint64 {
var hash uint64 = offset64
for i := 0; i < len(key); i++ {
hash ^= uint64(key[i])
hash *= prime64
}
return hash
}fastcache 则采用了XXH64哈希算法,优点在于高度可移植性,可以在不同平台上生成64位相同的哈希值。bigcache还为为Hash函数的实现定义了一个接口Hasher,开发者可以选择不同的hash函数实现:
type Hasher interface {
Sum64(string) uint64
}3. 零GC的实现
Go语言自带垃圾回收机制,对于map,垃圾回收器会并发标记(mark)和扫描(scan)其中的每一个元素,如果缓存中包含数百万的缓存对象,垃圾回收器对这些对象的无意义的检查导致不必要的时间开销。
如果我们使用sync.Map或map + sync.RWMutex的实现方案,垃圾回收将不可避免。而bigcache和fastcache库都实现了零GC。它们都是采用了哪些手段呢?我们一起来看一下。
3.1 使用堆外内存
垃圾回收器检查的是堆上资源,如果不把对象放到堆上,就自然没有GC的压力了。fastcache 使用了这个思路,分配缓存数据内存时使用了golang.org/x/sys/unix库,它提供了定制的Mmap方法。但是堆外内存非常容易造成内存泄漏,慎用!
3.2 map非指针优化
Go的开发者在1.5版本中针对map的垃圾回收进行了优化runtime: do not scan maps when k/v do not contain pointers,对于不包含指针的map,虽然也是分配在堆上,但是垃圾回收可以无视它们。所以说只要将map定义成map[int]int,就能减少gc的压力。
但是业务中我们无法要求缓存对象只包含int、bool这样的基础数据类型,为了解决这个问题,bigcache和fastcache都采用了一种相同的巧妙的解决方法:使用哈希值作为map[uint64]uint32的key。 把缓存对象序列化后放到一个预先分配的大的字节数组中,然后将它在数组中的offset作为map[uint64]uint32的value。下面是bigcache实现原理架构图:
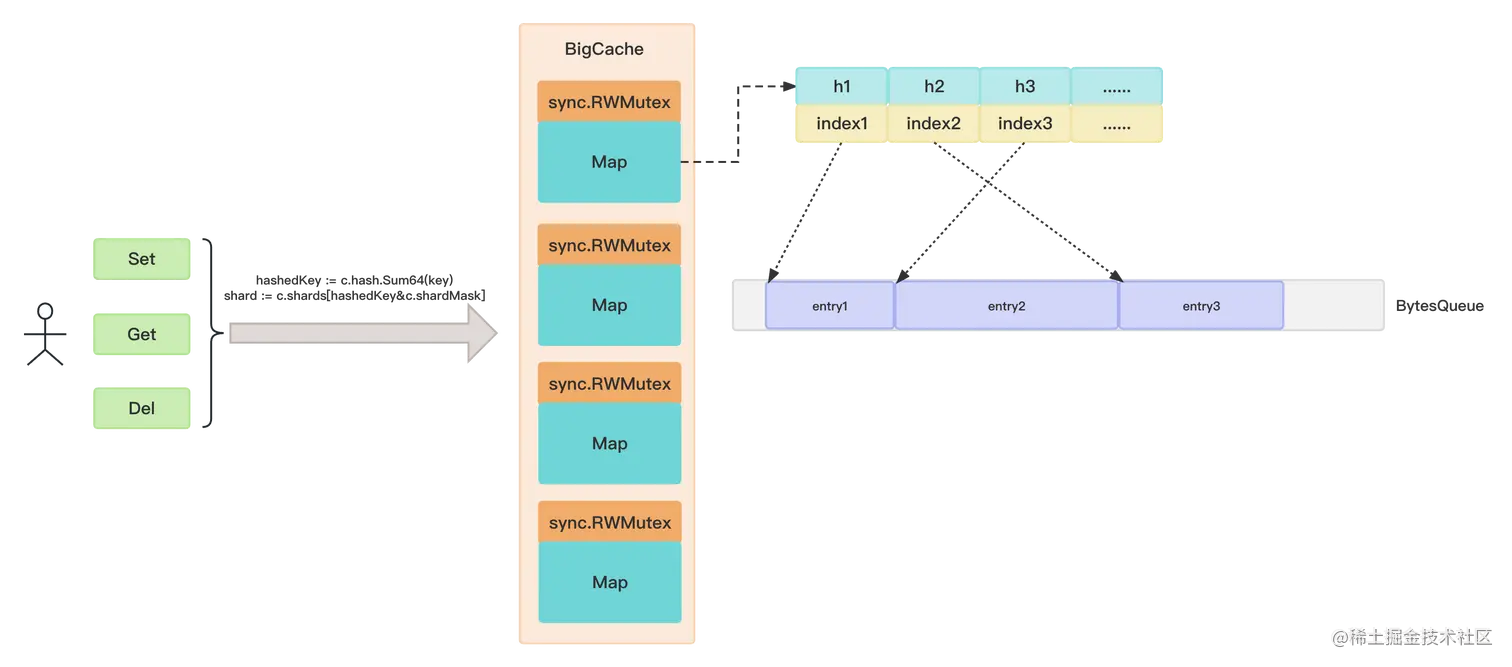
BytesQueue是一个字节数组,能够做到按需分配,所以bigcache是能够根据缓存大小,自动扩容的,当加入一个entry时,会将它转化为[]byte添加到末尾,也就是说更新元素的值,只是在末尾新增了元素的新值,更新了map[uint64]uint32中的index而已。删除操作也是将缓存key从map[uint64]uint32中剔除了而已。
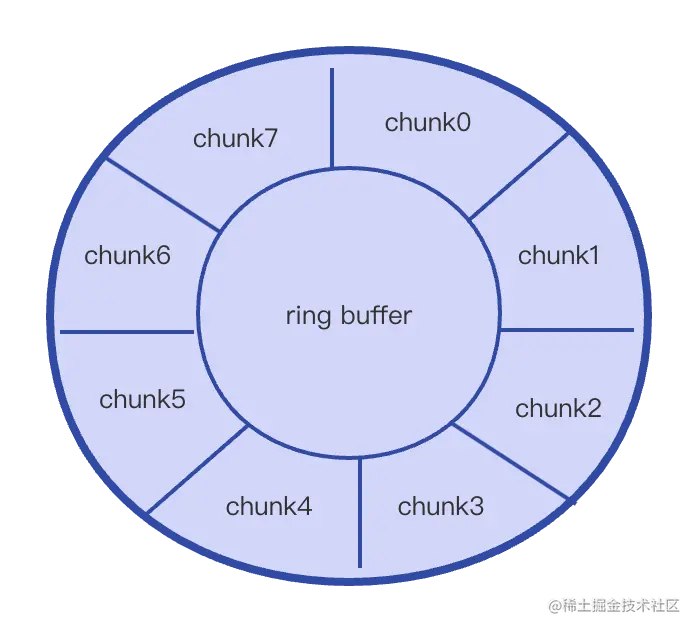
fastcache官方文档介绍,它的灵感来自于bigcache。所以整体的思路和bigcache很类似,数据通过bucket进行分片。fastcache由512个bucket构成。每个bucket维护一把读写锁。在bucket内部数据同理是索引、数据两部分构成。索引用map[uint64]uint64存储。数据采用chunks二维的切片(二维数组)存储。我们前边提到了fastcache使用的是堆外内存,根据chunks大小进行内存分配与管理,下边是fastcache实现的原理架构图:

4. 内存占用和过期淘汰策略的抉择?
4.1 覆盖写 or 自动扩容?
对于内存占用和过期淘汰策略这两点特性支持上,bigcache和fastcache分别采用了不同的处理思路。
首先fastcache受初始化时内存的限制,初始化时指定的内存大小平均分配给512个bucket(例如总量为 2GB, 那么每个桶的数据就是 4MB),当桶中的数据写满时,会根据ringbuffer的特性覆盖写,剔除比较旧的内容。
而bigcache则会根据缓存对象大小自动扩容,扩容是个很耗时的工作,可能会产生大量数据的copy。这是fastcache性能比bigcache好的一个原因。
4.2 数据过期需要支持吗?
fastcache比bigcache性能好的另外一个原因是:fastcache不支持缓存数据的自动过期,因此也就没必要像bigcache一样做额外的检查与数据清理工作了。对bigcache而言,要维护数据的过期策略首先在增加一个元素之前,会检查最老的元素要不要删除;其次,在添加一个元素失败后,会清理空间删除最老的元素。同时,还会专门有一个定时的清理goroutine, 负责移除过期数据。而这些都是以牺牲性能为代价的,那么这样做到底有没有意义呢?
或许有吧!不过fastcache官方文档上提出的另外一个观点是:其实数据的过期,可以由业务方将数据的过期时间戳写入到缓存数据中,自行判断数据是否过期。从其功能实现上而言,也确实是这样,毕竟删除数据支持操作了map[uint64]uint64的映射关系,数据并没有从ringbuffer中真正的清理掉。
5. 小结
本节我们围绕Go语言本地缓存的设计展开,提出了设计一个本地缓存需要考虑的几大因素。然后结合bigcache和fastcache两个优秀的开源库分析了它们的实现,还有一些思路上的折中。这些思路都是可以在业务开发中借鉴的。
也并不是说这些开源库的实现都那么的尽善尽美,如果业务中有特殊的需求,还可以基于开源库做二次开发,比如:是否有可能实现一个本地缓存库,既支持缓存对象单独设置缓存时间,又能实现高性能、占用内存少呢?又比如:是否能实现一个只占用固定内存,但可以占用大量磁盘空间,依然保持高性能的缓存库呢?我曾经思考过这些问题,但是奈何水平有限,没有什么突破性的进展。如果有感兴趣或者有思路的小伙伴,可以在评论区进行交流~
以上就是Go语言实现本地缓存的策略详解的详细内容,更多关于Go本地缓存的资料请关注本网站其它相关文章!
您可能感兴趣的文章:
- Go本地测试小技巧解耦任务拆解
- go 下载非标准库包(部份包被墙了)到本地使用的方法
- go本地环境配置及vscode go插件安装的详细教程
- 使用Go实现健壮的内存型缓存的方法
- 深入理解go缓存库freecache的使用
- Go应该如何实现二级缓存
