目录
- 一、什么是停用词
- 二、加载停用词字典
- 三、删除停用词
- 四、分词以及删除停用词
- 五、直接删除停用词(不分词)
一、什么是停用词
在汉语中,有一类没有多少意义的词语,比如组词“的”,连词“以及”、副词“甚至”,语气词“吧”,被称为停用词。一个句子去掉这些停用词,并不影响理解。所以,进行自然语言处理时,我们一般将停用词过滤掉。
而HanLP库提供了一个小巧的停用词字典,它位于Lib\site-packages\pyhanlp\static\data\dictionary目录中,名字为:stopwords.txt。该文本收录了常见的中英文无意义的词汇,每行一个词语。示例如下:

我们在进行自然语言处理时,可以用BinTrie、DoubleArrayTrie和AhoCorasickDoubleArrayTrie中的任意一个来存储词典。考虑到该词典中都是短语且比较多,用双数组字典树更划算,处理时间更快。
二、加载停用词字典
通过前文的介绍,我们知道了使用双数组字典树加载停用词字典更划算。下面,我们来加载其停用词,并返回键值对结构。代码如下:
def load_dictionary(path):
map=JClass('java.util.TreeMap')()
with open(path,encoding='utf-8') as src:
for word in src:
word=word.strip()
map[word]=word
return JClass('com.hankcs.hanlp.collection.trie.DoubleArrayTrie')(map)
三、删除停用词
通过上面的停用词加载,我们获取了DoubleArrayTrie树结构的词汇。如果要删除停用词,可以直接使用分词后的结果剔除停用词即可。剔除的方法如下:
def remove_stopwords(termlist,trie):
return [term.word for term in termlist if not trie.containsKey(term.word)]四、分词以及删除停用词
在前面的博文中,我们已经学会了如何分词,现在我们又学会了如何剔除停用词。这里,我们将两者结合起来,实现分词效果。代码如下:
if __name__ == "__main__":
HanLP.Config.ShowTermNature=False
trie=load_dictionary(HanLP.Config.CoreStopWordDictionaryPath)
text="今天就这样吧!明天我们在说可以吗?"
segment=DoubleArrayTrieSegment()
termlist=segment.seg(text)
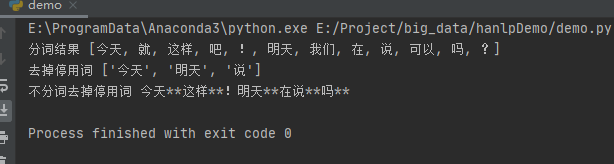
print("分词结果",termlist)
print("去掉停用词",remove_stopwords(termlist,trie))
运行之后,得到如下结果:

五、直接删除停用词(不分词)
对应上面的结果,我们先分词在删除停用词。但是,有时候我们也喜欢先删除停用词在进行分词。下面,我们来实现直接删除停用词。
代码如下:
#直接过滤方法
def direct_remove_stopwords(text,replacement,trie):
JString=JClass('java.lang.String')
searcher=trie.getLongestSearcher(JString(text),0)
offset=0
result=''
while searcher.next():
begin=searcher.begin
end=begin+searcher.length
if begin>offset:
result+=text[offset:begin]
result+=replacement
offset=end
if offset<len(text):
result+=text[offset:]
return result
if __name__ == "__main__":
HanLP.Config.ShowTermNature = False
trie = load_dictionary(HanLP.Config.CoreStopWordDictionaryPath)
text = "今天就这样吧!明天我们在说可以吗?"
segment = DoubleArrayTrieSegment()
termlist = segment.seg(text)
print("分词结果", termlist)
print("去掉停用词", remove_stopwords(termlist, trie))
print("不分词去掉停用词", direct_remove_stopwords(text, "**", trie))
运行之后,效果如下:
到此这篇关于python基础之停用词过滤详解的文章就介绍到这了,更多相关python停用词过滤内容请搜索本网站以前的文章或继续浏览下面的相关文章希望大家以后多多支持本网站!
您可能感兴趣的文章:
- python使用jieba实现中文分词去停用词方法示例
- 利用Python过滤相似文本的简单方法示例
- Python实现敏感词过滤的4种方法
- Python过滤序列元素的方法
- python numpy实现多次循环读取文件 等间隔过滤数据示例
- python正则过滤字母、中文、数字及特殊字符方法详解
