图文理解malloc内存分配(赶快学习起来~)
前言
由于malloc()的源码十分的繁琐,并且会调用OS所提供的API,所以我不在对malloc()的源码进行分析了,而只是会分析malloc()的动作,这就已经足够了。
好文推荐:
全网最牛Linux内核分析--Intel CPU体系结构
一文让你读懂Linux五大模块内核源码,内核整体架构设计(超详细)
嵌入式前景真的好吗?那有点悬!
一文教你如何使用GDB+Qemu调试Linux内核
Linux内核必读五本书籍(强烈推荐)
全网独一无二Linux内核Makefle系统文件详解(一)(纯文字代码)
带你深度了解Linux内核架构和工作原理!
一、malloc()分配出的内存空间
在前边的文章中已经提及到了,当malloc()分配空间时,并不是要多少就分配多少,而是会额外的加上首部和尾部,其中一些较为简单的部分我会在这里进行解释,而较为重要的部分我会在本文下面的分析中逐步的完善。图片取自侯捷C++内存分配系列教程讲义
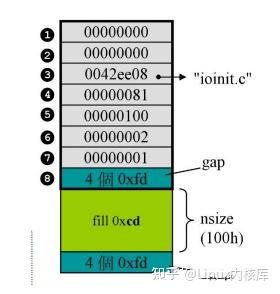
这张图片去除掉了上下两块cookie和下边的填补区pad。浅绿色的fill是调用malloc()时向系统申请的内存,该函数返回时,也会返回这块区域开头的指针。这里申请了0x100 byte的内存.fill上下两块gap预先被填充为了0xfdfdfdfd,用来分隔客户可以使用的内存区和不可使用的内存区,同时,当这块内存被归还时,编辑器也可以通过下gap的值区判断当前内存块是否被越界使用了。上gap向上连续的7个内存空间共同组成了debug header,从上向下标号为1-71、2两块空间保存了两根指针,目的是使多个内存块连接成链表。3空间保存了申请本内存块的文件名4- 空间保存了申请本内存块的代码行数5空间记录了本内存块中实际可以被用户使用的内存空间的大小6空间记录了当前内存块的流水号,即是链表中的第几个,从1开始7空间记录了当前内存块被分配的形式,后边会进行分析
【文章福利】小编推荐自己的Linux内核技术交流群:【】整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前100名进群领取,额外赠送大厂面试题。
学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈-学习视频教程-腾讯课堂ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=ke.sigusoft.com/course/?flowToken=
内核资料直通车:2022全新Linux内核源码分析学习路线图+完整视频+完整资料docs.sigusoft.com/doc/DYXFObEFJa0p4bUNUdocs.sigusoft.com/doc/DYXFObEFJa0p4bUNUdocs.sigusoft.com/doc/DYXFObEFJa0p4bUNUdocs.sigusoft.com/doc/DYXFObEFJa0p4bUNUdocs.sigusoft.com/doc/DYXFObEFJa0p4bUNUdocs.sigusoft.com/doc/DYXdLeWZSakRRUnFW
二、内存分配
1.内存管理所用到的结构层次
首先,在进入程序之前,系统就已经分配出了一个结构去管理内存,我们先来看看这个结构
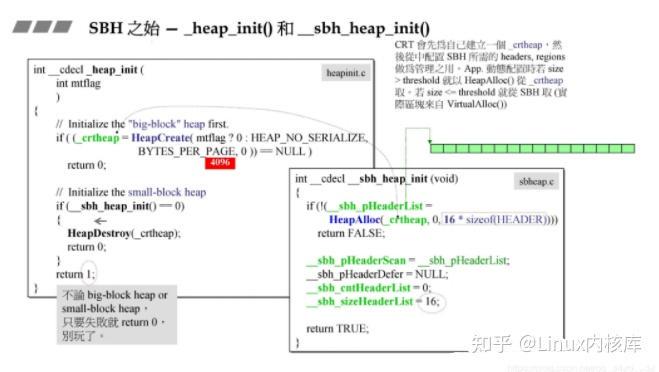
代码比较难看懂,我这里分析一下。系统首先会调用__cdecl_heap_init()函数去分配一个堆空间,用在这里分配的堆空间去管理程序中会产生的动态分配内存的请求。而在__cdecl_heap_init()这个函数中,回去创建一个长度为16的类型为HEADER的链表,这个链表的每个节点将在以后的程序中去管理1MB的内存。我们去看下这个链表的节点的结构:

这里需要重点的是两根指针:指针pHeapData将被指向这个header所管理的那1MB的内存空间的开头。pRegion将会被指向一个管理用的结构,这个结构将会在下边展开
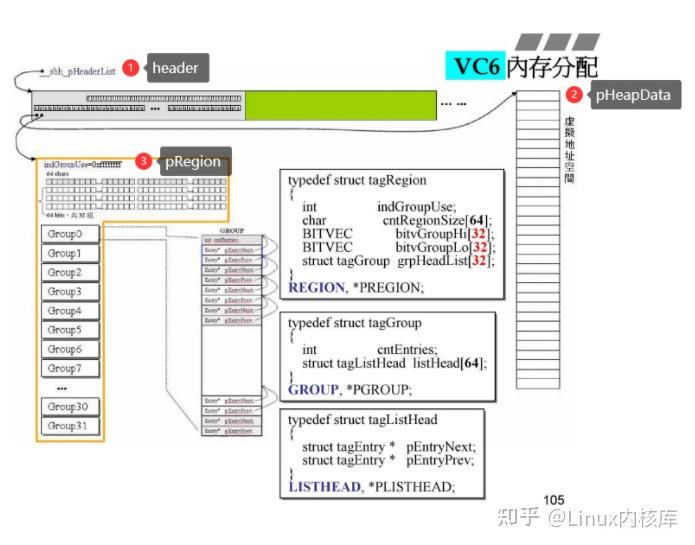
这张图对应了上边的关系在这个图中显示的,pHeapData指向的是虚拟地址空间,没错,现在还是虚拟的,并没有为其分配内存,我们可以将他想象成门牌号的集合。这里只保存了门牌号,但是房子还没有建起来。这里以后将要分配的空间一共是1MB,将被分为32个32KB的内存段。接下来我们详细去看pRegion所指向的结构,也就是tagRegion;
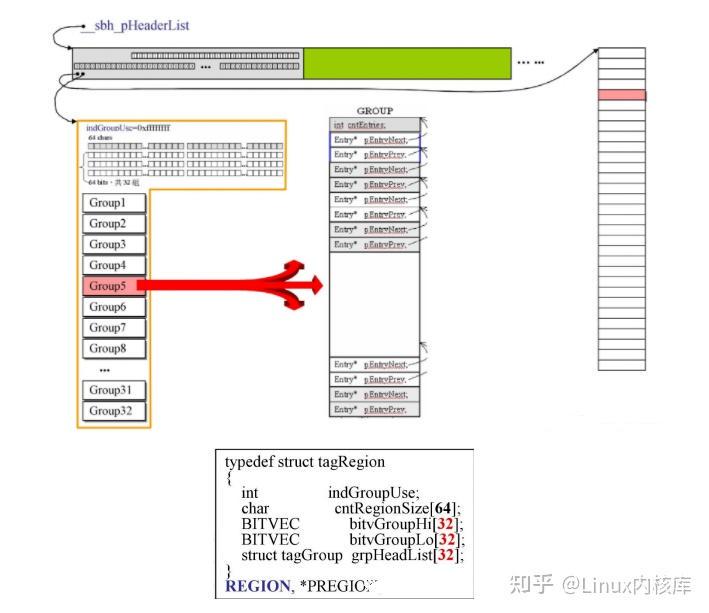
indGroupUse表示了当前会提供内存的group编号,从0开始cntRegionSize[64]用64个字节去对应后边group所将会展开链表,当对应链表挂在有内存时,将会变成1.bitvGroupHi和bitvGroupLo共同构成了一个的byteMap共64个byte(分为32组),将来用于对应每个group中所挂载的64条双向链表,当对应的位置挂载有内存时,会变成1.grpHeadList就是32个group,每个group负责32KB

这里的cntEntries代表当前链表中挂载的内存块被切分的次数listHead对应64对指针,也就是形成了64条链表,用于挂载不同大小的内存块,间隔为16byte,最后一条链表将挂载所有大于等于1K的内存块编号1就是上边所说的每grop中的那64条双向链表现在只有最后一条双向链表中挂载有内存页。编号2是这个group所对应的那32K的内存段,将他分为了8份,每份就是4K,将这8个内存页串成链表,由于每一个内存页都大于1K,所以都将挂载在最后一条链表上。当一切准备好,挂载的对应方式如下图:
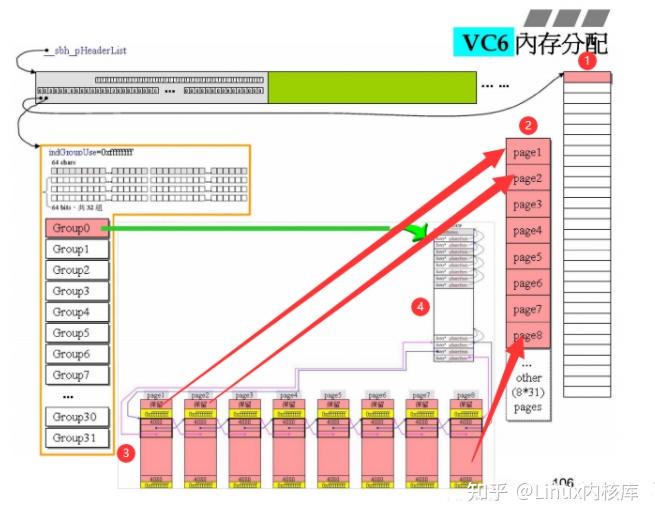
编号1是当前header所管理的1MB的空间,将其32等分,每一份的32KB由一个group去负责分配编号2是一个group所管理的32K的空间,将其分为8个4KB大小的内存页挂载于最后一条链表上编号3是分割好的内存页链表,他们被串成一个双向链表。编号4是一个group中的64条链表
2.内存页的划分
下面我们来看每个崭新的内存页的内容
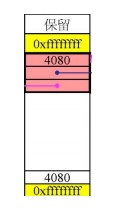
这是一个4K大小的内存页:中间的空白区域代表了可共malloc()索取的4080byte的内存空间空白的最下边和红色的最上边,两个标有4080的空间是用来记录剩余可用空间大小的cookie剩余的两块红色部分是两根指针,指向链表中前边和后边的内存页黄色的标有0xfdfdfdfd的是两根分割区域,具体作用上边已经提及最上边的保留区域是为了让下边空白区域成为16byte的整数倍
内存页划分的规则
当申请一个内存空间时,首先先去符合的链表中寻找,如果链表中没有挂载内存块,就从编号较大的链表中最近的挂有内存块的链表中划分。
内存页被划分之后的情况
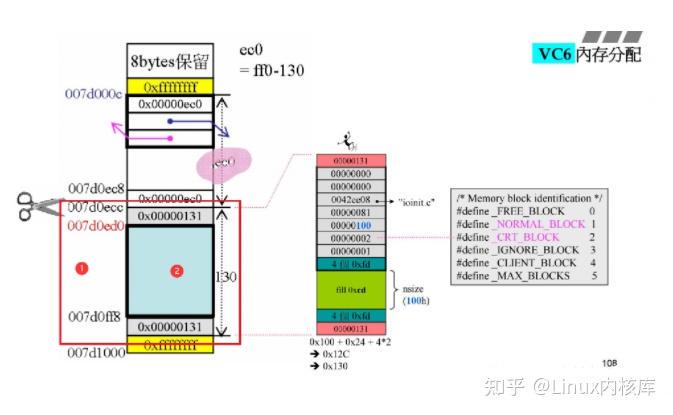
最左边原先是一个崭新的内存页(4K = ff0),然后我们从内存页中划分出0x130 byte的空间:编号为1的是被划分出的实际空间编号2是实际可以为用户所使用的实际空间,这个空间应该是0x100上下两根cookie记录了被划分出去的实际空间,至于为什么是0x131,之前的文章有提及内存被划分出去后,malloc()再对其进行复写,然后将实际空间交付给客户。当这块内存被分配出去之后,原来内存页中的cookie = ff0-130 = ec0,此时仍然大于1KB,所以不用转移挂载的位置。
3.内存分配的动作
我们刚刚分配出了0x130的空间,我们先看看这个空间分配出去之后的动作
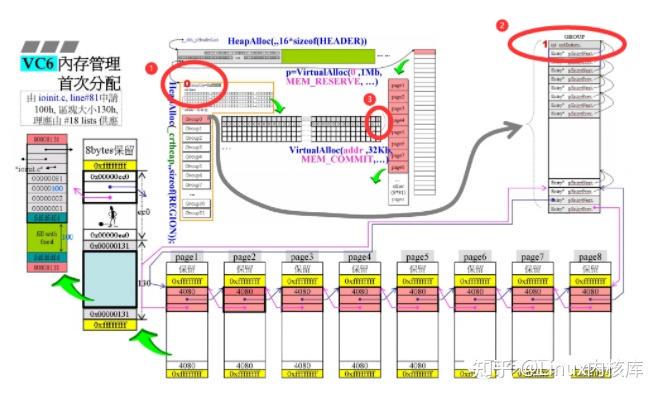
编号1:此时由group0分配内存,所以Region 中的 indGroupUse被设置为0编号2:整个group的内存页被划分了一次,所以Group 中的 cntEntries被置为1编号3:此时group0只有最后一个链表空间上挂载了链表,所以Region 中对应的byte被置为1此时page1中剩余空间为ec0 byte;
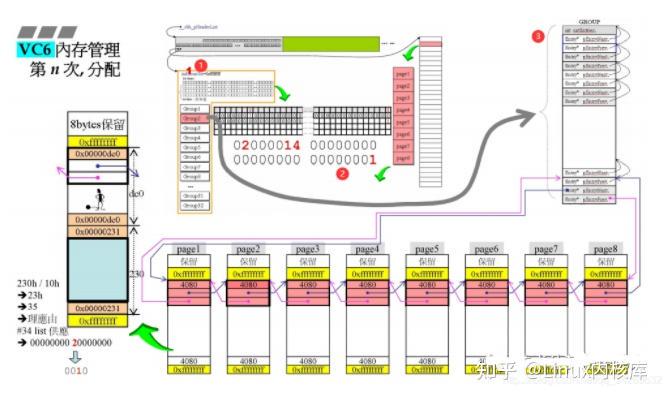
当某一次分配时,group0中没有比当前需求大的内存块了,此时就需要开辟另一个group去服务了编号1:由于当前是group1再分配内存,所以Region 中的 indGroupUse设置为1编号2:将group1中最后一条链表再bitMap中对应的位设置为1编号3:group1整个的内存页被划分了一次,所以Group 中的 cntEntries被置为1此时再分配内存就会从group中去分配了
4.内存归还的动作
当多次连续分配之后,出现了一次归还空间的动作
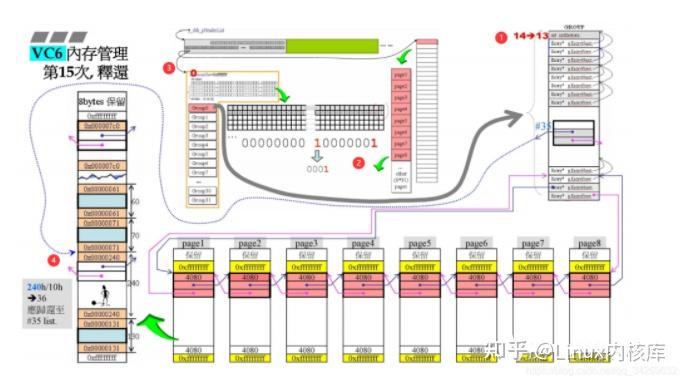
编号1:当前group分配出的内存块-1编号2:由于此次归还的内存大小为0x240应该挂载于第35号链表,所以将第35号链表对应的bite设为1(这里将byteMap中每四个byte写成了一个16进制数)编号3:当前还是group所分配内存,所以所以Region 中的 indGroupUse仍为0编号4:这时被归还的内存被复写,两个cookie从0x241变回0x240,表示没有被使用,两根指针连入35号链表。
三、将内存归还给OS
我们来探讨几个问题:
Q1、当多个group被启用时,怎么去寻找归还的内存属于哪个group?
答案很简单,夹杀法:我们知道每一个group对应内存的起始地址和结尾地址,我们只需要去判断被归还的指针中地址的大小是否在这二者之间,就能判断出是否属于当前的group。而去寻找所对应的header的方法也是如此。
Q2、怎么将内存还给操作系统?`
这里时malloc和之前讲过的分配器本质上的区别,我们能将收回的内存还给操作系统,具体步骤如下:对于回收的连续的内存空间进行合并 这个实现时基于上下两个cookie的实现完成的
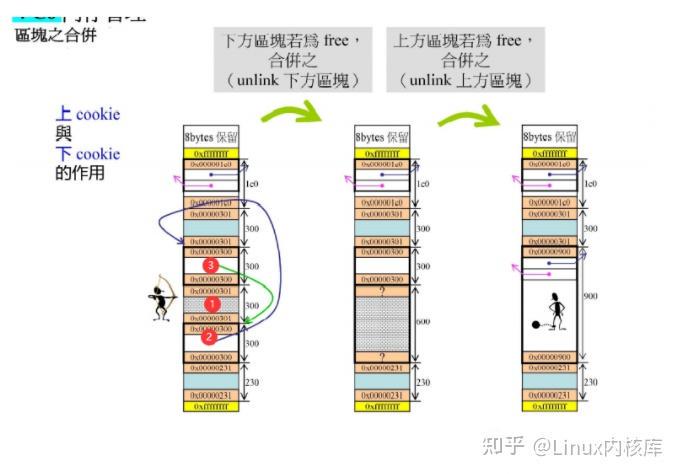
这里我们假设还的的1号空间,我们能看到 2、3两个空间的cookie结尾都是0,所以也是空闲的,也就是说这三块连续的空间可以合并。向下合并:我们首先有一个指向1号空间的指针,他通过cookie可以知道自己有多大,所以下调对应的大小就可以到达2号空间的开头,查看2号空间的cookie可以知道他的大小,也可以知道它是空闲的,所以可以将他们两个合并。向上合并:我们首先有一个指向1号空间的指针,他向上调整两个int的长度,可以到达3号空间的cookie,通过三号空间的cookie可以知道3号空间的大小,也可以知道3号空间是空闲的,所以就可以将他们两个合并。重复上边两个步骤,我们可以将相连的N块空闲内存全部合并,并计算大小调整连接位置。
2. 判断分配的空间的全回收这也很简单,我们再每个group都记录了分配出去的次数,每当我们回收的时候,就将这个值-1,所以当它再次为0的时候,就证明这个group的内存全部回收了。
3. 当内存全回收之后的状态由于有上边的合并机制,所以当一个group的内存全回收之后,他的状态就和最开始时一样,也就是最后一个链表上连接着8个4KB大小的内存块,这时我们就可以将他还给操作系统了。
Q3:当一个group全回收之后,我们需要将他立刻还给系统么?
答案肯定是否定的,因为如果我们全回收一个就还一个,那么当下一次在需要分配时,我们还需要重新分配。所以全回收的group不会立刻被还给系统,而是等待下一个全回收的group出现,就会将前一个group对应的内存free掉。

