内存管理(六):一文搞懂malloc、free实现原理
malloc / free 简介
分配指定大小的内存空间,返回一个指向该空间的指针。大小以字节为单位。返回 指针,需要强制类型转换后才能引用其中的值。 释放一个由 所分配的内存空间。 指向一个要释放内存的内存块,该指针应当是之前调用 的返回值。
使用示例:
动态内存分配的系统调用:
动态分配的内存都在堆中,堆从低地址向高地址增长:
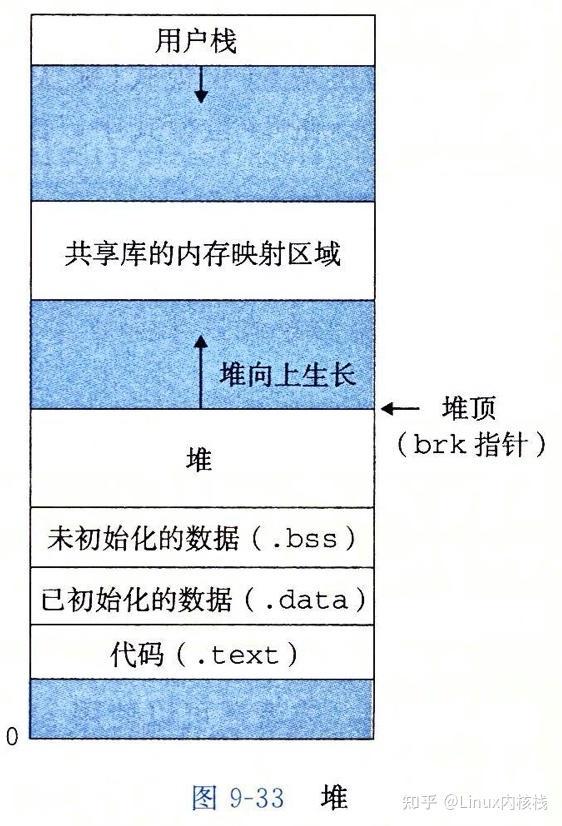
Linux 提供了两个系统调用 和 :
用于返回堆的顶部地址; 用于扩展堆,通过参数 指定要增加的大小,如果扩展成功,返回 的旧值。如果 为零,返回 的当前值。
我们不会直接通过 或 来分配堆内存,而是先通过 扩展堆,将这部分空闲内存空间作为缓冲池,然后通过 管理缓冲池中的内存。这是一种池化思想,能够避免频繁的系统调用,提高程序性能。
malloc / free 实现思路
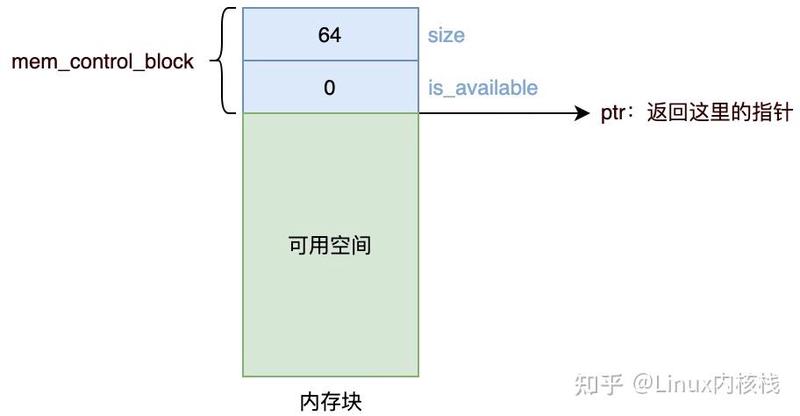
使用空闲链表组织堆中的空闲区块,空闲链表有时也用双向链表实现。每个空闲区块都有一个相同的首部,称为“内存控制块” ,其中记录了空闲区块的元信息,比如指向下一个分配块的指针、当前分配块的长度、或者当前区块是否已经被分配出去。这个首部对于程序是不可见的, 返回的是紧跟在首部后面的地址,即可用空间的起始地址。
分配时会搜索空闲链表,根据匹配原则,找到一个大于等于所需空间的空闲区块,然后将其分配出去,返回这部分空间的指针。如果没有这样的内存块,则向操作系统申请扩展堆内存。注意,返回的指针是从可用空间开始的,而不是从首部开始的:
malloc 所实际使用的内存匹配算法有很多,执行时间和内存消耗各有不同。到底使用哪个匹配算法,取决于实现。常见的内存匹配算法有:最佳适应法最差适应法首次适应法下一个适应法
free 会将区块重新插入到空闲链表中。free 只接受一个指针,却可以释放恰当大小的内存,这是因为在分配的区域的首部保存了该区域的大小。
malloc 的实现方式一:显式空闲链表 + 整块分配
malloc 的实现方式有很多种。最简单的方法是使用一个链表来管理所有已分配和未分配的内存块,在每个内存块的首部记录当前块的大小、当前区块是否已经被分配出去。首部对应这样的结构体:
使用首次适应法进行分配:遍历整个链表,找到第一个未被分配、大小合适的内存块;如果没有这样的内存块,则向操作系统申请扩展堆内存。
下面是这种实现方式的代码:
对应的free实现:
这种方法的缺点是:
1、已分配和未分配的内存块位于同一个链表中,每次分配都需要从头到尾遍历2、采用首次适应法,内存块会被整体分配,容易产生较多内部碎片
malloc 的实现方式二:显式空闲链表 + 按需分配
这种实现方式维护一个空闲块链表,只包含未分配的内存块。malloc 分配时会搜索空闲链表,找到第一个大于等于所需空间的空闲区块,然后从该区块的尾部取出所需要的空间,剩余空间还是存在空闲链表中;如果该区块的剩余部分不足以放下首部信息,则直接将其从空闲链表摘除。最后返回这部分空间的指针。 下面是这种实现方式的几个示例:
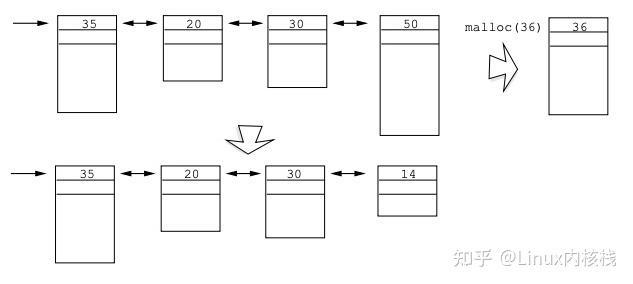
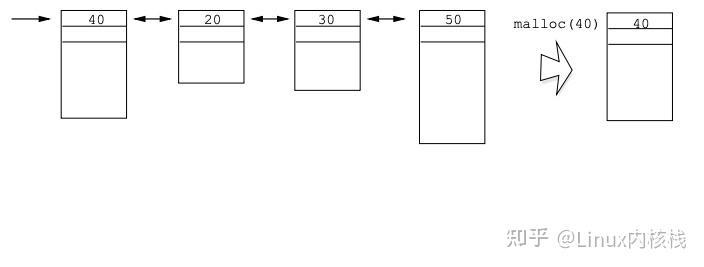
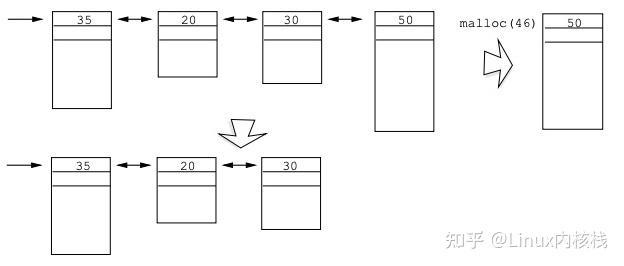
通过 free 释放内存时,会将内存块加入到空闲链表中,并将前后相邻的空闲内存合并,这时使用双向链表管理空闲链表就很有用了。
和第一种方式相比,这种方式的优点主要是:空闲链表中只包含未被分配的内存块,节省遍历开销只分配必须大小的空间,避免内存浪费
这种方式的缺点是:多次调用 malloc 后,空闲内存被切成很多的小内存片段,产生较多外部碎片,会导致用户在申请内存使用时,找不到足够大的内存空间。这时需要进行内存整理,将连续的空闲内存合并,但是这会降低函数性能。
注意:内存紧凑在这里一般是不可用的,因为这会改变之前 malloc 返回的空间的地址。
malloc 的实现方式三:分离的空闲链表
上面的两种分配方法,分配时间都和空闲块的数量成线性关系。
另一种实现方式是分离存储,即维护多个空闲链表,其中每个链表中的块有大致相等或者相同的大小。一般常见的是根据 2 的幂来划分块大小。分配时,可以直接在某个空闲链表里搜索合适的块。如果没有找到合适的块与之匹配,就搜索下一个链表,以此类推。
简单分离存储
每个大小类的空闲链表包含大小相等的块。分配时,从某个空闲链表取下一块,或者向操作系统请求内存片并分割成大小相等的块,形成新的链表。释放时,只需要简单的将块插入到相应空闲链表的前面。
优点一是分配和释放只需要在链表头进行操作,都是常数时间,二是因为每个块大小都是固定的,所以只需要一个 next 指针,不需要额外的控制信息,节省空间。缺点是容易造成内部碎片和外部碎片。内部碎片显而易见,因为每个块都是整体分配的,不会被分割。外部碎片在这样的模式下很容易产生:应用频繁地申请和释放较小大小的内存块,由于这些内存块不会合并,所以系统维护了大量小内存块形成的空闲链表,而没有多余空间来分配大内存块,导致产生外部碎片。
分离适配
这种方法同样维护了多个空闲链表,只不过每个链表中的块是大致相等的大小,比如每个链表中的块大小范围可能是:123~45~8…1025~~~∞
在分配的时候,需要先根据申请内存的大小选择适当的空闲链表,然后遍历该链表,根据匹配算法(如首次适应)寻找合适的块。如果找到一个块,将其分割(可选),并将剩余部分插入到适当的空闲链表中。如果找不到合适的块,则查找下一个更大的大小类的空闲链表,以此类推,直到找到或者向操作系统申请额外的堆内存。在释放一个块时,合并前后相邻的空闲块,并将结果放到相应的空闲链表中。
分离适配方法是一种常见的选择,C 标准库中提供的 GNU malloc 包就是采用的这种方法。这种方法既快速,对内存的使用也很有效率。由于搜索被限制在堆的某个部分而不是整个堆,所以搜索时间减少了。内存利用率也得到了改善,避免大量内部碎片和外部碎片。
伙伴系统
伙伴系统是分离适配的一种特例。它的每个大小类的空闲链表包含大小相等的块,并且大小都是 2 的幂。最开始时,全局只有一个大小为 2m2m 字的空闲块,2m2m 是堆的大小。
假设分配的块的大小都是 2 的幂,为了分配一个大小为 2k2k 的块,需要找到大小恰好是 2k2k 的空闲块。如果找到,则整体分配。如果没有找到,则将刚好比它大的块分割成两块,每个剩下的半块(也叫做伙伴)被放置在相应的空闲链表中,以此类推,直到得到大小恰好是 2k2k 的空闲块。释放一个大小为 2k2k 的块时,将其与空闲的伙伴合并,得到新的更大的块,以此类推,直到伙伴已分配时停止合并。
伙伴系统分配器的主要优点是它的快速搜索和快速合并。主要缺点是要求块大小为 2 的幂可能导致显著的内部碎片。因此,伙伴系统分配器不适合通用目的的工作负载。然而,对于某些特定应用的工作负载,其中块大小预先知道是 2 的幂,伙伴系统分配器就很有吸引力了。
tcmalloc
tcmalloc 是 Google 开发的内存分配器,全称 Thread-Caching Malloc,即线程缓存的 malloc,实现了高效的多线程内存管理。
tcmalloc 主要利用了池化思想来管理内存分配。对于每个线程,都有自己的私有缓存池,内部包含若干个不同大小的内存块。对于一些小容量的内存申请,可以使用线程的私有缓存;私有缓存不足或大容量内存申请时再从全局缓存中进行申请。在线程内分配时不需要加锁,因此在多线程的情况下可以大大提高分配效率。
总结
malloc 使用链表管理内存块。malloc 有多种实现方式,在不同场景下可能会使用不同的匹配算法。
malloc 分配的空间中包含一个首部来记录控制信息,因此它分配的空间要比实际需要的空间大一些。这个首部对用户而言是透明的,malloc 返回的是紧跟在首部后面的地址,即可用空间的起始地址。
malloc 分配的函数应该是字对齐的。在 32 位模式中,malloc 返回的块总是 8 的倍数。在 64 位模式中,该地址总是 16 的倍数。最简单的方式是先让堆的起始位置字对齐,然后始终分配字大小倍数的内存。
malloc 只分配几种固定大小的内存块,可以减少外部碎片,简化对齐实现,降低管理成本。
free 只需要传递一个指针就可以释放内存,空间大小可以从首部读取。
2022年嵌入式开发想进互联网大厂,你技术过硬吗?
从事十年嵌入式转内核开发(23K到45K),给兄弟们的一些建议
腾讯T6-9首发“Linux内核源码嵌入式开发进阶笔记”,差距不止一点点哦
