53.redis面试题汇总(2)
1.如何避免缓存雪崩、缓存击穿、缓存穿透?
缓存雪崩:设置缓存的过期时间(TTL)为不同的随机值,避免大量缓存同时过期。使用高可用的缓存解决方案,如 Redis 集群,确保缓存服务的稳定性。缓存击穿:对热点数据设置永不过期或者长时间过期,并定期更新缓存。使用互斥锁或同步机制确保并发请求中只有一个请求去构建缓存。缓存穿透:对查询结果为空的情况也进行缓存,避免重复查询非法或不存在的数据。使用布隆过滤器(Bloom Filter)预先判断请求的数据是否存在。
避免击穿
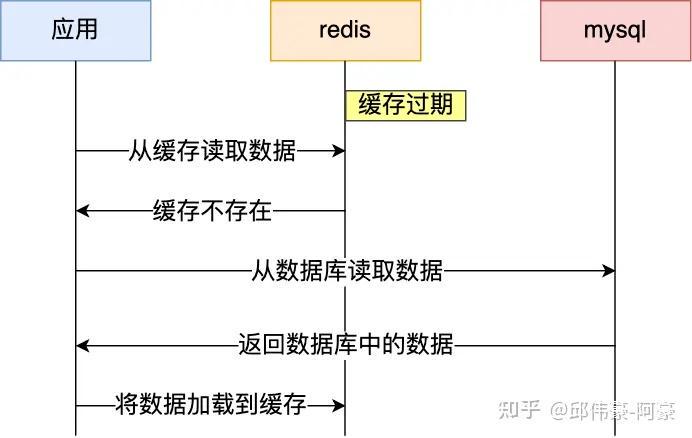
2.如何设计一个缓存策略,可以动态缓存热点数据呢?
通过数据最新访问时间来做排名,并过滤掉不常访问的数据,只留下经常访问的数据。
以电商平台场景中的例子,现在要求只缓存用户经常访问的 Top 1000 的商品。
3.说说常见的缓存更新策略?
常见的缓存更新策略共有3种:Cache Aside(旁路缓存)策略;Read/Write Through(读穿 / 写穿)策略;Write Back(写回)策略;
4.Redis 如何实现延迟队列?
在淘宝、京东等购物平台上下单,超过一定时间未付款,订单会自动取消;打车的时候,在规定时间没有车主接单,平台会取消你的单并提醒你暂时没有车主接单;点外卖的时候,如果商家在10分钟还没接单,就会自动取消订单;
在 Redis 可以使用有序集合(ZSet)的方式来实现延迟消息队列的,ZSet 有一个 Score 属性可以用来存储延迟执行的时间。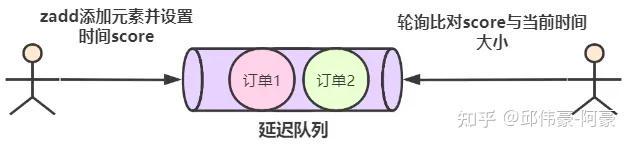
5.Redis 的大 key 如何处理?
大 key 并不是指 key 的值很大,而是 key 对应的 value 很大。
一般而言,下面这两种情况被称为大 key:String 类型的值大于 10 KB;Hash、List、Set、ZSet 类型的元素的个数超过 5000个;
大 key 会带来以下四种影响:客户端超时阻塞。由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。内存分布不均。集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
排查redis-cli --bigkeys 查找大key、使用 SCAN 命令查找大 key、使用 RdbTools 工具查找大 key
处理分批次删除(删除大 Hash、删除大 List、删除大 Set、删除大 ZSet、异步删除)
6.Redis 管道有什么用?
管道技术(Pipeline)是客户端提供的一种批处理技术,用于一次处理多个 Redis 命令,从而提高整个交互的性能。
普通模式: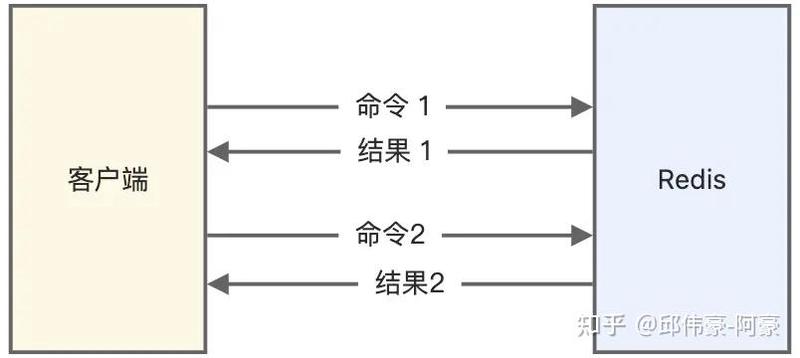
管道模式: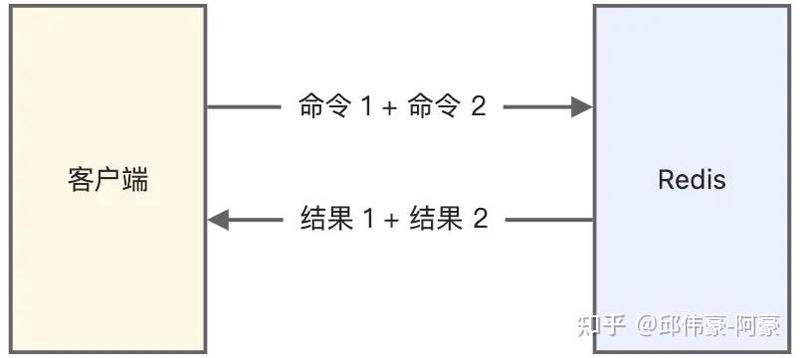
7.Redis 事务支持回滚吗?
作者不支持事务回滚的原因有以下两个:他认为 Redis 事务的执行时,错误通常都是编程错误造成的,这种错误通常只会出现在开发环境中,而很少会在实际的生产环境中出现,所以他认为没有必要为 Redis 开发事务回滚功能;不支持事务回滚是因为这种复杂的功能和 Redis 追求的简单高效的设计主旨不符合。
8.如何用 Redis 实现分布式锁的?
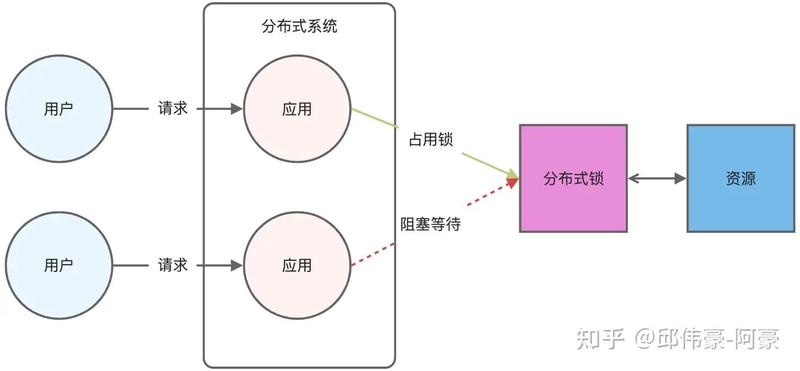
Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:如果 key 不存在,则显示插入成功,可以用来表示加锁成功;如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
lock_key 就是 key 键;unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
