使用Pytorch训练中文词向量
1、用Jieba库进行中文样本预训练
用get_ch_label()函数将所有文本读入training_data,然后在fenci()函数中使用Jieba库对training_data分词生成training_ci,将training_ci放入build_dataset中生成指定长度的字典。
在函数中,对样本的词频进行统计,将所有的词按照词频顺序由高到低进行排列,同时将排列后的列表中的第0个索引设置成未知字符UNK,这个未知字符用于对词频低的词语进行填充,例如设置字典为350,词频排在350之后的词会被当成未知字符处理。最终总字数1567,总次数961
2、按照Skip-Gram规则制作数据集
首先用 Dataset与DataLoader接口制作数据集。在自定义Dataset类中,按照 Skip-Gram规则对样本和其对应的标签进行组合。
编写代码实现数据集的制作:在数据集中,每批次取12个样本作为输入数据;每个词向量的维度为128;每个中心词前后的各取3个子词。
样本中的每个子词都被当作一个中心词。任意一个样本中心词都会生成两组标签:正样本标签与负样本标签。正样本标签来自中心词的前后位置,负样本标签来自词频的多项式采样。
3、搭建模型进行训练
首先定义一个词嵌入层,将输入的样本和标签分别用词嵌入层进行转换;然后在训练过程中,将输入与标签的词嵌入当作两个向量,将二者的矩阵相乘当作两个向量间夹角的余弦值并用该余弦值作为被优化的损失函数。
其中bmm()函数处理的是批次数据,mm()函数处理的是普通矩阵的数据。
第113行代码,(return -loss)对最终的loss值取负,将损失函数的值域由(-inf,0]变为(0,inf]。这种变换有利于在迭代训练中使用优化器进行优化(因为优化器只能使损失值沿着最小化的方向优化)。
第139~155行代码,( norm = torch.sum(model.in_embed.weight.data.pow(2),-1).sqrt().unsqueeze(1)到最后)实现了对现有模型进行能力测试。该代码会从验证样本中取出指定个数的子词,通过词嵌入转换 在已有的训练样本中找到与其语义相近的子词并显示出来。
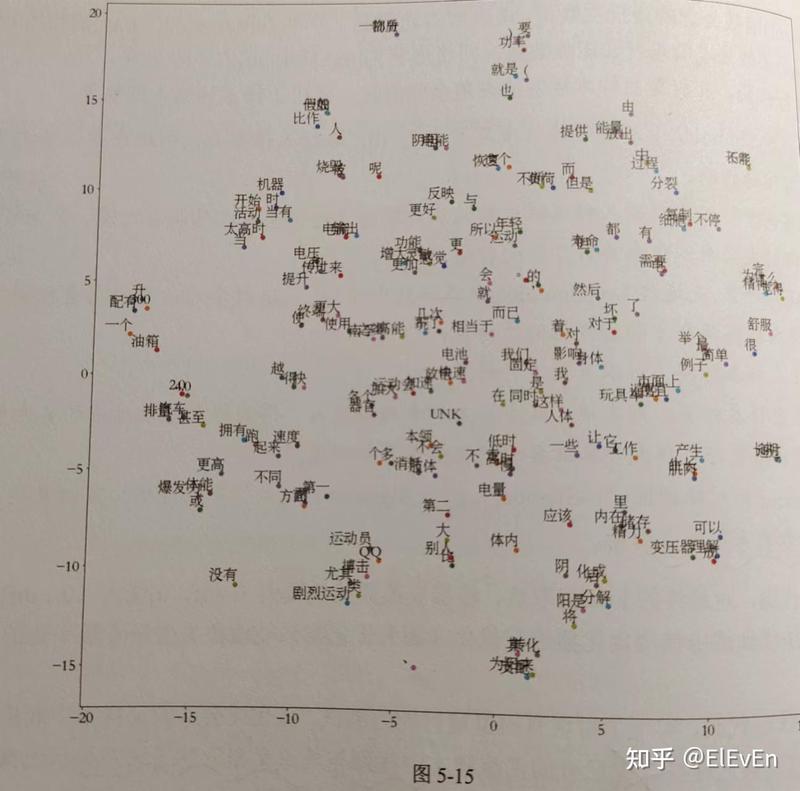
最终得到如下结果:
最终的可视化结果可以展示为: