【译】理解 Ranking Loss,Contrastive Loss,Margin Loss,Triplet Loss,Hinge Loss 等易混淆的概念
Ranking Loss被用于很多领域和神经网络任务中(如 Siamese Nets 或 Triplet Nets),这也是它为什么拥有 Contrastive Loss、Margin Loss、Hinge Loss 或 Triplet Loss 等这么多名字的原因。
Ranking Loss 函数:度量学习
像 Cross-Entropy Loss 或 Mean Squear Error Loss 这些 Loss 函数,它们的目的是为了直接预测一个标签或一个值,而 Ranking Loss 的目的是为了预测输入样本间的相对距离。这样的任务通常被称作度量学习。
Ranking Loss 函数在训练数据方面非常灵活:我们只需要知道数据间的相似度分数,就可以使用它们。这个相似度分数可以是二维的(相似/不相似)。例如,想象一个面部识别数据集,我们知道哪些人脸图像属于同一个人(相似),哪些不属于(不相似)。使用 Ranking Loss 函数,我们可以训练一个 CNN 网络,来推断两张面部图像是否属于同一个人。
要使用 Ranking Loss 函数,我们首先要定义特征抽取器,它能从 2 个或 3 个样本中抽取表征样本的 embedding;接着我们定义一个能度量他们相似度的函数,如欧拉距离;最后,我们训练特征抽取器,在相似样本的条件下,所产生出的 embeddings 的距离相近,反之对于不相似的样本,它们的距离较远。
我们不关心表征 embedding 所对应的值,只关心它们的距离。然而,这种训练方法已经证明可以为不同的任务产生强大的表征。
Ranking Losses 表述
Ranking Losses 有不同的名称,但在大多数场景下,它们的表述是简单的和不变的。我们用于区分不同 Ranking Loss 的方式有 2 种:二元组训练数据(Pairwise Ranking Loss)或三元组训练数据(Triplet Ranking Loss)。
这两者都会比较训练数据的表征之间的距离。
Pairwise Ranking Loss
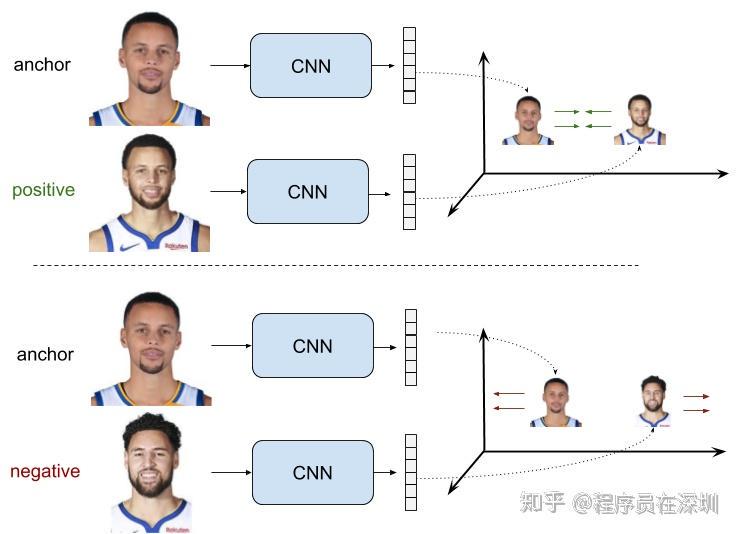
该设置会用到正样本对和负样本对训练集,正样本对包含锚样本 和正样本
,
和
相似,负样本对由锚样本
和负样本
组成,在度量中它和
不相似。
对于正样本对,目标是学习它们的表达,使它们之间的距离 越小越好;而对于负样本对,要求样本之间的距离超过一个边距
。Pairwise Ranking Loss 要求正样本对之间的表达的距离为 0,同时负样本对的距离要超过一个边距(margin)。我们用
,
和
来分别表示锚样本、正样本和负样本的表达,
是一个距离函数,则可以写成:
对于正样本对,只有当网络产生的两个元素的表征没有距离时,损失才是0,损失会随着距离的增加而增加。
对于负样本对,当两个元素的表征的距离超过边距 时,损失才是0。然而当距离小于
时,loss 为正值,此时网络参数会被更新,以调整这些元素的表达,当
和
的距离为 0 时,loss 达到最大值
。边距的作用是,当负样本对产生的表征距离足够远时,就不会把精力浪费在扩大这个距离上,所以进一步训练可以集中在更难的样本上。
假设 和
是样本的表征,
为 0 时表示负样本对,为 1 时表示正样本对,距离用欧拉距离来表示,我们还可以把 Loss 写成:
Triplet Ranking Loss
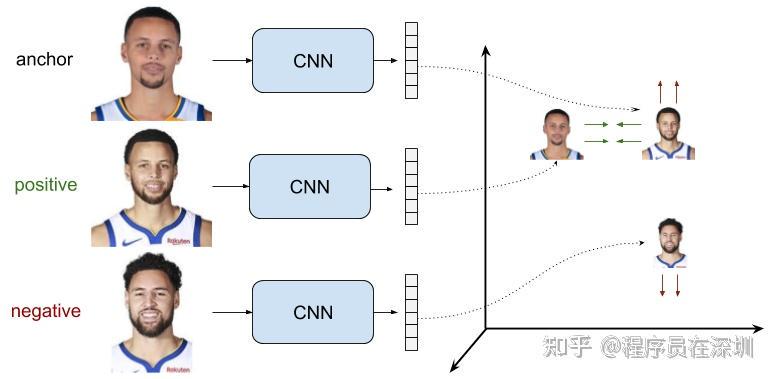
使用 triplet 三元组的而不是二元组来训练,模型的表现更好。Triplets 三元组由锚样本 ,正样本
,和负样本
组成。**模型的目标是锚样本和负样本表达的距离
要比锚样本和正样本表达的距离
大一个边距
。**我们可以这样写:
一起来分析下该 loss 的 3 种情况:Easy Triplets:,相对于正样本和锚样本之间的距离,负样本和锚样本的距离已经足够大了,此时 loss 为 0,网络参数无需更新。Hard Triplets:
。负样本和锚样本的距离比正样本和锚样本之间的距离还近,此时 loss 为正,且比
大。Semi-Hard Triplets:
。锚样本和负样本之间的距离比和正样本大,但不超过边距
,所以 loss 依然为正(但小于 m)。
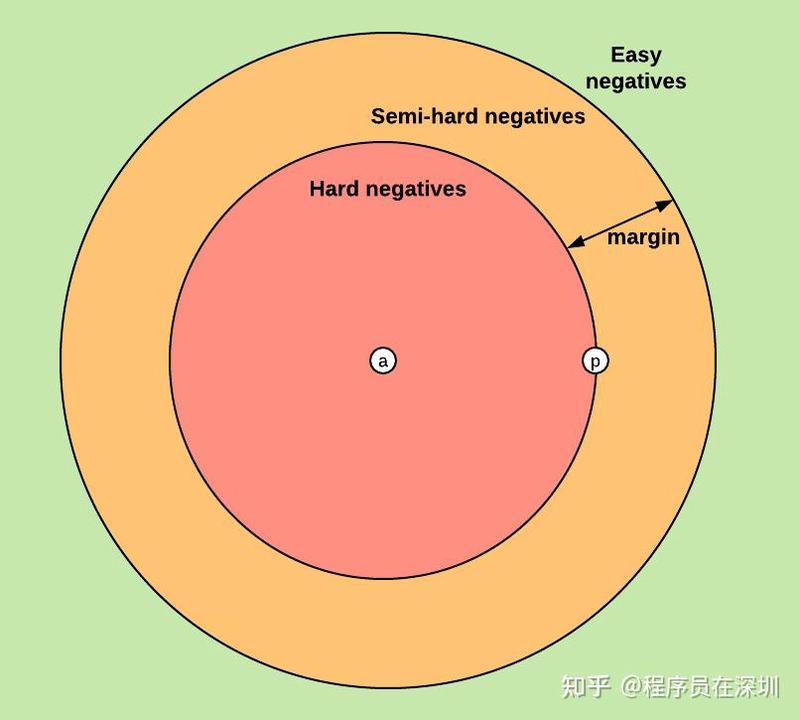
负样本的选择
训练 Triplet Ranking Loss 的重要步骤就是负样本的选择,选择负样本的策略会直接影响模型效果,很明显,Easy Triplets 的负样本需要避免,因为它们的 loss 为 0。
第一策略为使用离线 triplet 采样,意味着 triplets 在训练之前就准备好。另外就是在线 triplet 采样,它在训练的每个 batch 内定义 triplets,这种方式的训练效率比较高。
最佳的负样本选择方案高度依赖于任务本身,更多该方面的内容你可以参考这篇博客。 深度学习的 Triplet Loss介绍:Learning Fine-grained Image Similarity with Deep Ranking 和 FaceNet: A Unified Embedding for Face Recognition and Clustering 这个 github 中包含了有趣的可视化 Cross-Entropy Loss、Pairwise Ranking Loss 和 Triplet Ranking Loss,它们都基于 MINST 数据集。
Ranking Loss 的其他命名
上文介绍的 Ranking Loss,在许多不同的应用中表述都基本相同,或只有微小的变化。然而,它们常使用不同的名称,这可能会造成混淆,我来解释下:Ranking Loss:这个名字来自于信息检索领域,我们希望训练模型按照特定顺序对目标进行排序。Margin Loss:这个名字来自于它们的损失使用一个边距来衡量样本表征的距离。Contrastive Loss:Contrastive 指的是这些损失是通过对比两个或更多数据点的表征来计算的。这个名字经常被用于 Pairwise Ranking Loss,但我从未见过在 Triplets 中使用它。Triplet Loss:当使用 triplet 三元组训练时,常作为 Loss 名称。Hinge Loss:也称作最大化边距目标,常用于训练分类的 SVM 。它有类似的机制,即一直优化到边距值为止。这也是它为什么常在 Ranking Losses 中出现的原因。
Siamese 和 triplet 网络
Siamese 和 triplet 网络分别对应 pairwise ranking loss 和 triplet ranking loss。 在这些模型中,用于计算 pair 或 triplet 样本表征的网络一般会共享参数(例如使用相同的 CNN)。
Siamese 网络
Siamese 网络由 2 个相同的共享参数的 CNN 组成(两个 CNN 的参数相同),每一个 CNN 处理一张图片,生成两张图片的表征,接着计算两个表征的距离,最后,使用 Pairwise Ranking Loss 来训练该网络。相似图片产生的表征的距离很小,而不相似图片的距离较大。
假设 就是 CNN 网络,我们可以把 Pairwise Ranking Loss 写为:
Triplet 网络
和 Siamese 网络的思想一致,但 Triplet 网络拥有 3 个分支(3 个共享参数的 CNN),模型的输入为 1 个正样本、1个负样本以及对应的锚样本,并使用 Triplet Ranking Loss 来训练它。对于锚图片来说,可以让模型同时学到相似图片和不相似图片的差异。
在 Triplet 网络中,因为相同的 CNN 要产生 3 个元素的表征,我们可以把 Triplet Ranking Loss 写成:
使用 Ranking Loss 做多模态检索
在我的研究中,我已经使用了 Triplet Ranking Loss 来实现了多模态文字和图片的检索。训练数据集由标记了文字的图片组成,模型的训练目标是将文字和图片的 embedding 映射到同一向量空间中。为了达到这一点,首先单独训练文本的 embeddings,并把训练好的参数固定住,文本 embeddings 使用如 Word2Vec 或 Glove 算法。接着,训练一个 CNN 将图片向量映射到同样的向量空间。思路是让模型学会在多模态向量空间的同一个点上嵌入一张图片和它相关的标题。
做这件事的第一种方法,是训练一个 CNN,根据 Cross-Entropy Loss 来直接预测图片的 embedding,效果不错,但我们发现使用 Triplet Ranking Loss 可以得到更好的结果。
具体操作如下:我们先固定住文本 embedding(GLove),然后仅通过 CNN 来学习图片的表达,那么,假设锚样本 是图片,正样本
是和图片关联的文字,以及负样本
为另一张“负样本”图片对应的文字。为了选择负样本文字,我们探索了网上不通的负采样策略,最终选择了 Glove 向量空间中与正样本文字距离较远的。在这个问题中,因为并没有建立分类,所以这种 Triplets 采样是合理的。考虑到图片的多样性,选择三元组很简单,但必须小心 hard-negatives 的采样,因为和另一张图片对应的文字,很可能也可以用来描述锚图片。
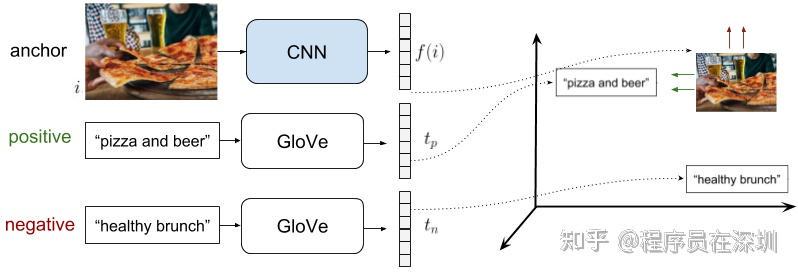
在该例子中,我们仅仅训练图片的表达,即 CNN 网络,用 来表示第
张图片,
表示 CNN,
、
分别表示 Glove 空间中的正、负文本表达的 embedding,可以写成:
我们用该例子对 Triplet Ranking Loss 和 Cross-Entropy Loss 做了些量化对比,这里我不打算继续展开,但你可以从这篇(论文,博客)中拿到同样的信息。基本上,我们利用社交网络上的数据训练出来的文本图片检索自监督模型中,Triplet Ranking Loss 的结果要比 Cross-Entropy Loss 好很多。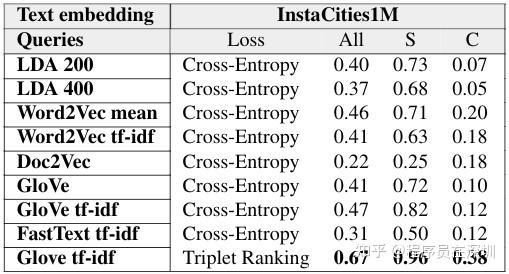 使用 Triplet Ranking Loss 而不是 Cross-Entropy Loss 或 Mean Square Error Loss 来预测文本的 embeddings 的另一个好处,是我们可以把预训练的文本 embeddings 固定住,然后把它们作为模型的 ground-truth。这允许我们先使用 RNN、LSTM 这些模型来处理文本语料,再和 CNN 一起进行训练,最终得到更好的数据表征。 类似的训练多模态检索系统和标题系统的方法在 COCO 中有使用到,链接在这里。
使用 Triplet Ranking Loss 而不是 Cross-Entropy Loss 或 Mean Square Error Loss 来预测文本的 embeddings 的另一个好处,是我们可以把预训练的文本 embeddings 固定住,然后把它们作为模型的 ground-truth。这允许我们先使用 RNN、LSTM 这些模型来处理文本语料,再和 CNN 一起进行训练,最终得到更好的数据表征。 类似的训练多模态检索系统和标题系统的方法在 COCO 中有使用到,链接在这里。
深度学习框架中的 Ranking Loss 层
Caffe
Constrastive Loss Layer. 限于 Pairwise Ranking Loss 计算. 例如,可以用于训练 Siamese 网络。PyCaffe Triplet Ranking Loss Layer. 用来训练 triplet 网络,by David Lu。
PyTorch
CosineEmbeddingLoss. 使用余弦相似度的 Pairwise Loss。输入是一对二元组,标签标记它是一个正样本对还是负样本对,以及边距 margin。MarginRankingLoss. 同上, 但使用欧拉距离。TripletMarginLoss. 使用欧拉距离的 Triplet Loss。
TensorFlow
contrastive_loss. Pairwise Ranking Loss.triplet_semihard_loss. 使用 semi-hard 负采样的 Triplet loss。
原文链接
