2022年大厂offer必备java面试题整理-redis(2)
Allen:2022年大厂offer必备java面试题整理-Java基础(1)
Allen:2022年大厂offer必备java面试题整理-Java基础(2)
Allen:2022年大厂offer必备java面试题整理-Java基础(3)
Allen:2022年大厂offer必备java面试题整理-JVM
Allen:2022年大厂offer必备java面试题整理-MySQL(1)
Allen:2022年大厂offer必备java面试题整理-MySQL(2)
Allen:2022年大厂offer必备java面试题整理-Spring(1)
Allen:2022年大厂offer必备java面试题整理-Spring(2)
Allen:2022年大厂offer必备java面试题整理-redis(1)
11、渐进式 rehash 的优点
渐进式 rehash 的好处在于它采取分⽽治之的⽅式,将 rehash 键值对所需的计算⼯作均摊到对字典的每个添加、删除、查找和更新操作上,从⽽避免了集中式 rehash ⽽带来的庞⼤计算量。
在进⾏渐进式 rehash 的过程中,字典会同时使⽤ ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进⾏期间,字典的删除、査找、更新等操作会在两个哈希表上进⾏。例如,要在字典⾥⾯査找⼀个键的话,程序会先在 ht[0]⾥⾯进⾏査找,如果没找到的话,就会继续到 ht[1] ⾥⾯进⾏査找,诸如此类。
另外,在渐进式 rehash 执⾏期间,新增的键值对会被直接保存到 ht[1], ht[0] 不再进⾏任何添加操作,这样就保证了 ht[0] 包含的键值对数量会只减不增,并随着 rehash 操作的执⾏⽽最终变成空表。
12、rehash 流程在数据量⼤的时候会有什么问题吗(Hash 对象的扩容流程在数据量⼤的时候会有什么问题吗)
1)扩容期开始时,会先给 ht[1] 申请空间,所以在整个扩容期间,会同时存在 ht[0] 和 ht[1],会占⽤额外的空间。 2)扩容期间同时存在 ht[0] 和 ht[1],查找、删除、更新等操作有概率需要操作两张表,耗时会增加。 3)redis 在内存使⽤接近 maxmemory 并且有设置驱逐策略的情况下,出现 rehash 会使得内存占⽤超过maxmemory,触发驱逐淘汰操作,导致 master/slave 均有有⼤量的 key 被驱逐淘汰,从⽽出现 master/slave主从不⼀致。
13、Redis 的⽹络事件处理器(Reactor 模式)
redis 基于 reactor 模式开发了⾃⼰的⽹络事件处理器,由4个部分组成:套接字、I/O 多路复⽤程序、⽂件事件分派器(dispatcher)、以及事件处理器。 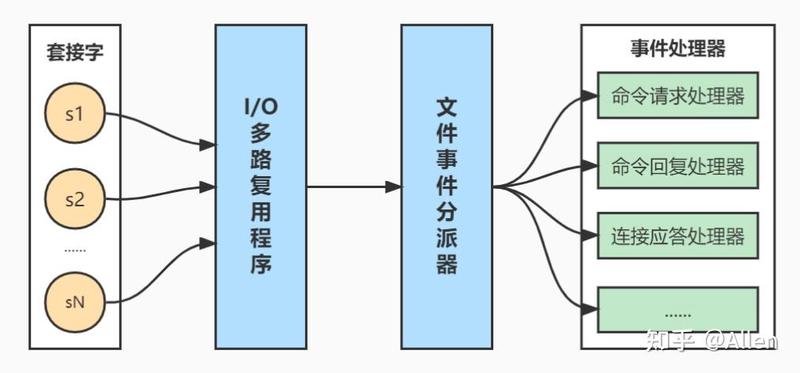
套接字:socket 连接,也就是客户端连接。当⼀个套接字准备好执⾏连接、写⼊、读取、关闭等操作时, 就会产⽣⼀个相应的⽂件事件。因为⼀个服务器通常会连接多个套接字, 所以多个⽂件事件有可能会并发地出现。
I/O 多路复⽤程序:提供 select、epoll、evport、kqueue 的实现,会根据当前系统⾃动选择最佳的⽅式。负责监听多个套接字,当套接字产⽣事件时,会向⽂件事件分派器传送那些产⽣了事件的套接字。当多个⽂件事件并发出现时, I/O 多路复⽤程序会将所有产⽣事件的套接字都放到⼀个队列⾥⾯,然后通过这个队列,以有序、同步、每次⼀个套接字的⽅式向⽂件事件分派器传送套接字:当上⼀个套接字产⽣的事件被处理完毕之后,才会继续传送下⼀个套接字。
⽂件事件分派器:接收 I/O 多路复⽤程序传来的套接字, 并根据套接字产⽣的事件的类型, 调⽤相应的事件处理器。
事件处理器:事件处理器就是⼀个个函数, 定义了某个事件发⽣时, 服务器应该执⾏的动作。例如:建⽴连接、命令查询、命令写⼊、连接关闭等等。
14、Redis 删除过期键的策略(缓存失效策略、数据过期策略)
定时删除:在设置键的过期时间的同时,创建⼀个定时器,让定时器在键的过期时间来临时,⽴即执⾏对键的删除操作。对内存最友好,对 CPU 时间最不友好。
惰性删除:放任键过期不管,但是每次获取键时,都检査键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。对 CPU 时间最优化,对内存最不友好。
定期删除:每隔⼀段时间,默认100ms,程序就对数据库进⾏⼀次检査,删除⾥⾯的过期键。⾄ 于要删除多少过期键,以及要检査多少个数据库,则由算法决定。前两种策略的折中,对 CPU 时间和内存的友好程度较平衡。 Redis 使⽤惰性删除和定期删除。
15、Redis 的内存淘汰(驱逐)策略
当 redis 的内存空间(maxmemory 参数配置)已经⽤满时,redis 将根据配置的驱逐策略(maxmemory-policy参数配置),进⾏相应的动作。
⽹上很多资料都是写 6 种,但是其实当前 redis 的淘汰策略已经有 8 种了,多余的两种是 Redis 4.0 新增的,基于LFU(Least Frequently Used)算法实现的。
noeviction:默认策略,不淘汰任何 key,直接返回错误 allkeys-lru:在所有的 key 中,使⽤ LRU 算法淘汰部分 key allkeys-lfu:在所有的 key 中,使⽤ LFU 算法淘汰部分 key,该算法于 Redis 4.0 新增 allkeys-random:在所有的 key 中,随机淘汰部分 key volatile-lru:在设置了过期时间的 key 中,使⽤ LRU 算法淘汰部分 key volatile-lfu:在设置了过期时间的 key 中,使⽤ LFU 算法淘汰部分 key,该算法于 Redis 4.0 新增 volatile-random:在设置了过期时间的 key 中,随机淘汰部分 key volatile-ttl:在设置了过期时间的 key 中,挑选 TTL(time to live,剩余时间)短的 key 淘汰
16、Redis 的 LRU 算法怎么实现的?
Redis 在 redisObject 结构体中定义了⼀个⻓度 24 bit 的 unsigned 类型的字段(unsigned lru:LRU_BITS),在LRU 算法中⽤来存储对象最后⼀次被命令程序访问的时间。 具体的 LRU 算法经历了两个版本。
版本1:随机选取 N 个淘汰法。
最初 Redis 是这样实现的:随机选 N(默认5) 个 key,把空闲时间(idle time)最⼤的那个 key 移除。这边的N可通过 maxmemory-samples 配置项修改。
就是这么简单,简单得让⼈不敢相信了,⽽且⼗分有效。
但是这个算法有个明显的缺点:每次都是随机从 N 个⾥选择 1 个,并没有利⽤前⼀轮的历史信息。
其实在上⼀轮移除 key 的过程中,其实是知道了 N 个 key 的 idle time 的情况的,那在下⼀轮移除 key 时,其实可以利⽤上⼀轮的这些信息。这也是 Redis 3.0 的优化思想。
版本2:Redis 3.0 对 LRU 算法进⾏改进,引⼊了缓冲池(pool,默认16)的概念。
当每⼀轮移除 key 时,拿到了 N(默认5)个 key 的 idle time,遍历处理这 N 个 key,如果 key 的 idle time ⽐pool ⾥⾯的 key 的 idle time 还要⼤,就把它添加到 pool ⾥⾯去。
当 pool 放满之后,每次如果有新的 key 需要放⼊,需要将 pool 中 idle time 最⼩的⼀个 key 移除。这样相当于 pool ⾥⾯始终维护着还未被淘汰的 idle time 最⼤的 16 个 key。
当我们每轮要淘汰的时候,直接从 pool ⾥⾯取出 idle time 最⼤的 key(只取1个),将之淘汰掉。
整个流程相当于随机取 5 个 key 放⼊ pool,然后淘汰 pool 中空闲时间最⼤的 key,然后再随机取 5 个 key放⼊ pool,继续淘汰 pool 中空闲时间最⼤的 key,⼀直持续下去。
在进⼊淘汰前会计算出需要释放的内存⼤⼩,然后就⼀直循环上述流程,直⾄释放⾜够的内存。
17、Redis 的持久化机制有哪⼏种,各⾃的实现原理和优缺点?
Redis 的持久化机制有:RDB、AOF、混合持久化(RDB+AOF,Redis 4.0引⼊)。
1)RDB
描述:类似于快照。在某个时间点,将 Redis 在内存中的数据库状态(数据库的键值对等信息)保存到磁盘⾥⾯。RDB 持久化功能⽣成的 RDB ⽂件是经过压缩的⼆进制⽂件。
命令:有两个 Redis 命令可以⽤于⽣成 RDB ⽂件,⼀个是 SAVE,另⼀个是 BGSAVE。
开启:使⽤ save point 配置,满⾜ save point 条件后会触发 BGSAVE 来存储⼀次快照。save point 格式:save ,含义是 Redis 如果在 seconds 秒内数据发⽣了 changes 次改变,就保存快照⽂件。
例如 Redis 默认就配置了以下3个:
关闭:1)注释掉所有save point 配置可以关闭 RDB 持久化。2)在所有 save point 配置后增加:save "",该配置可以删除所有之前配置的 save point。
SAVE:⽣成 RDB 快照⽂件,但是会阻塞主进程,服务器将⽆法处理客户端发来的命令请求,所以通常不会直接使⽤该命令。
BGSAVE:fork ⼦进程来⽣成 RDB 快照⽂件,阻塞只会发⽣在 fork ⼦进程的时候,之后主进程可以正常处理请求,详细过程如下图: 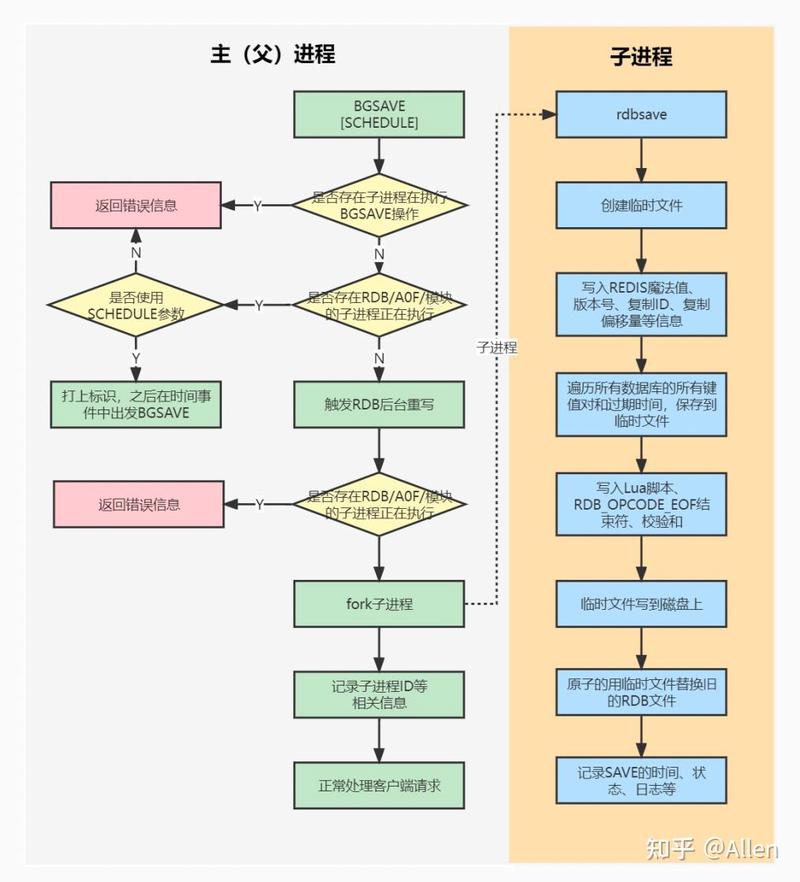
fork:在 Linux 系统中,调⽤ fork() 时,会创建出⼀个新进程,称为⼦进程,⼦进程会拷⻉⽗进程的 page table。如果进程占⽤的内存越⼤,进程的 page table 也会越⼤,那么 fork 也会占⽤更多的时间。如果 Redis 占⽤的内存很⼤,那么在 fork ⼦进程时,则会出现明显的停顿现象。
RDB 的优点
1)RDB ⽂件是是经过压缩的⼆进制⽂件,占⽤空间很⼩,它保存了 Redis 某个时间点的数据集,很适合⽤于做备份。 ⽐如说,你可以在最近的 24 ⼩时内,每⼩时备份⼀次 RDB ⽂件,并且在每个⽉的每⼀天,也备份⼀个 RDB ⽂件。这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。
2)RDB ⾮常适⽤于灾难恢复(disaster recovery):它只有⼀个⽂件,并且内容都⾮常紧凑,可以(在加密后)将它传送到别的数据中⼼。
3)RDB 可以最⼤化 redis 的性能。⽗进程在保存 RDB ⽂件时唯⼀要做的就是 fork 出⼀个⼦进程,然后这个⼦进程就会处理接下来的所有保存⼯作,⽗进程⽆须执⾏任何磁盘 I/O 操作。
4)RDB 在恢复⼤数据集时的速度⽐ AOF 的恢复速度要快。
RDB 的缺点
1)RDB 在服务器故障时容易造成数据的丢失。RDB 允许我们通过修改 save point 配置来控制持久化的频率。但是,因为 RDB ⽂件需要保存整个数据集的状态, 所以它是⼀个⽐较重的操作,如果频率太频繁,可能会对 Redis 性能产⽣影响。所以通常可能设置⾄少5分钟才保存⼀次快照,这时如果 Redis 出现宕机等情况,则意味着最多可能丢失5分钟数据。
2)RDB 保存时使⽤ fork ⼦进程进⾏数据的持久化,如果数据⽐较⼤的话,fork 可能会⾮常耗时,造成 Redis 停⽌处理服务N毫秒。如果数据集很⼤且 CPU ⽐较繁忙的时候,停⽌服务的时间甚⾄会到⼀秒。
3)Linux fork ⼦进程采⽤的是 copy-on-write 的⽅式。在 Redis 执⾏ RDB 持久化期间,如果 client 写⼊数据很频繁,那么将增加 Redis 占⽤的内存,最坏情况下,内存的占⽤将达到原先的2倍。刚 fork 时,主进程和⼦进程共享内存,但是随着主进程需要处理写操作,主进程需要将修改的⻚⾯拷⻉⼀份出来,然后进⾏修改。极端情况下,如果所有的⻚⾯都被修改,则此时的内存占⽤是原先的2倍。
2)AOF
描述:保存 Redis 服务器所执⾏的所有写操作命令来记录数据库状态,并在服务器启动时,通过重新执⾏这些命令来还原数据集。
开启:AOF 持久化默认是关闭的,可以通过配置:appendonly yes 开启。
关闭:使⽤配置 appendonly no 可以关闭 AOF 持久化。
AOF 持久化功能的实现可以分为三个步骤:命令追加、⽂件写⼊、⽂件同步。
命令追加:当 AOF 持久化功能打开时,服务器在执⾏完⼀个写命令之后,会将被执⾏的写命令追加到服务器状态的 aof 缓冲区(aof_buf)的末尾。
⽂件写⼊与⽂件同步:可能有⼈不明⽩为什么将 aof_buf 的内容写到磁盘上需要两步操作,这边简单解释⼀下。
Linux 操作系统中为了提升性能,使⽤了⻚缓存(page cache)。当我们将 aof_buf 的内容写到磁盘上时,此时数据并没有真正的落盘,⽽是在 page cache 中,为了将 page cache 中的数据真正落盘,需要执⾏ fsync / fdatasync 命令来强制刷盘。
这边的⽂件同步做的就是刷盘操作,或者叫⽂件刷盘可能更容易理解⼀些。
serverCron 时间事件中会触发 flushAppendOnlyFile 函数,该函数会根据服务器配置的 appendfsync 参数值,来决定是否将 aof_buf 缓冲区的内容写⼊和保存到 AOF ⽂件。
appendfsync 参数有三个选项:
1. always:每处理⼀个命令都将 aof_buf 缓冲区中的所有内容写⼊并同步到AOF ⽂件,即每个命令都刷盘。
2. everysec:将 aof_buf 缓冲区中的所有内容写⼊到 AOF ⽂件,如果上次同步 AOF ⽂件的时间距离现在超过⼀秒钟, 那么再次对 AOF ⽂件进⾏同步, 并且这个同步操作是异步的,由⼀个后台线程专⻔负责执⾏,即每秒刷盘1次。
3. no:将 aof_buf 缓冲区中的所有内容写⼊到 AOF ⽂件, 但并不对 AOF ⽂件进⾏同步, 何时同步由操作系统来决定。即不执⾏刷盘,让操作系统⾃⼰执⾏刷盘。
AOF 的优点
4. AOF ⽐ RDB可靠。你可以设置不同的 fsync 策略:no、everysec 和 always。默认是 everysec,在这种配置下,redis 仍然可以保持良好的性能,并且就算发⽣故障停机,也最多只会丢失⼀秒钟的数据。
5. AOF⽂件是⼀个纯追加的⽇志⽂件。即使⽇志因为某些原因⽽包含了未写⼊完整的命令(⽐如写⼊时磁盘已满,写⼊中途停机等等), 我们也可以使⽤ redis-check-aof ⼯具也可以轻易地修复这种问题。
6. 当 AOF⽂件太⼤时,Redis 会⾃动在后台进⾏重写:重写后的新 AOF ⽂件包含了恢复当前数据集所需的最⼩命令集合。整个重写是绝对安全,因为重写是在⼀个新的⽂件上进⾏,同时 Redis 会继续往旧的⽂件追加数据。当新⽂件重写完毕,Redis 会把新旧⽂件进⾏切换,然后开始把数据写到新⽂件上。
7. AOF ⽂件有序地保存了对数据库执⾏的所有写⼊操作以 Redis 协议的格式保存, 因此 AOF ⽂件的内容⾮常容易被⼈读懂, 对⽂件进⾏分析(parse)也很轻松。如果你不⼩⼼执⾏了 FLUSHALL 命令把所有数据刷掉了,但只要 AOF ⽂件没有被重写,那么只要停⽌服务器, 移除 AOF ⽂件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执⾏之前的状态。
AOF 的缺点
8. 对于相同的数据集,AOF ⽂件的⼤⼩⼀般会⽐ RDB ⽂件⼤。
9. 根据所使⽤的 fsync 策略,AOF 的速度可能会⽐ RDB 慢。通常 fsync 设置为每秒⼀次就能获得⽐较⾼的性能,⽽关闭 fsync 可以让 AOF 的速度和 RDB ⼀样快。
10. AOF 在过去曾经发⽣过这样的 bug :因为个别命令的原因,导致 AOF ⽂件在重新载⼊时,⽆法将数据集恢复成保存时的原样。(举个例⼦,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug ) 。虽然这种 bug 在 AOF ⽂件中并不常⻅, 但是相较⽽⾔, RDB ⼏乎是不可能出现这种 bug 的。
3)混合持久化
描述:混合持久化并不是⼀种全新的持久化⽅式,⽽是对已有⽅式的优化。混合持久化只发⽣于 AOF 重写过程。 使⽤了混合持久化,重写后的新 AOF ⽂件前半段是 RDB 格式的全量数据,后半段是 AOF 格式的增量数据。 整体格式为:[RDB file][AOF tail]
开启:混合持久化的配置参数为 aof-use-rdb-preamble,配置为 yes 时开启混合持久化,在 redis 4 刚引⼊时, 默认是关闭混合持久化的,但是在 redis 5 中默认已经打开了。
关闭:使⽤ aof-use-rdb-preamble no 配置即可关闭混合持久化。 混合持久化本质是通过 AOF 后台重写(bgrewriteaof 命令)完成的,不同的是当开启混合持久化时,fork 出的⼦ 进程先将当前全量数据以 RDB ⽅式写⼊新的 AOF ⽂件,然后再将 AOF 重写缓冲区(aof_rewrite_buf_blocks) 的增量命令以 AOF ⽅式写⼊到⽂件,写⼊完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF ⽂件替换旧的 AOF ⽂件。
优点:结合 RDB 和 AOF 的优点, 更快的重写和恢复。 缺点:AOF ⽂件⾥⾯的 RDB 部分不再是 AOF 格式,可读性差。
18、为什么需要 AOF 重写?
AOF 持久化是通过保存被执⾏的写命令来记录数据库状态的,随着写⼊命令的不断增加,AOF ⽂件中的内容会越来越多,⽂件的体积也会越来越⼤。
如果不加以控制,体积过⼤的 AOF ⽂件可能会对 Redis 服务器、甚⾄整个宿主机造成影响,并且 AOF ⽂件的体积越⼤,使⽤ AOF ⽂件来进⾏数据还原所需的时间就越多。
举个例⼦, 如果你对⼀个计数器调⽤了 100 次 INCR , 那么仅仅是为了保存这个计数器的当前值, AOF ⽂件就需要使⽤ 100 条记录。
然⽽在实际上, 只使⽤⼀条 SET 命令已经⾜以保存计数器的当前值了, 其余 99 条记录实际上都是多余的。 为了处理这种情况, Redis 引⼊了 AOF 重写:可以在不打断服务端处理请求的情况下, 对 AOF ⽂件进⾏重建 (rebuild)。
19、介绍下 AOF 重写的过程、AOF 后台重写存在的问题、如何解决 AOF 后台重写存在的数据不⼀致问题?
描述:Redis ⽣成新的 AOF ⽂件来代替旧 AOF ⽂件,这个新的 AOF ⽂件包含重建当前数据集所需的最少命令。 具体过程是遍历所有数据库的所有键,从数据库读取键现在的值,然后⽤⼀条命令去记录键值对,代替之前记录这个键值对的多条命令。
命令:有两个 Redis 命令可以⽤于触发 AOF 重写,⼀个是 BGREWRITEAOF 、另⼀个是 REWRITEAOF 命令;
开启:AOF 重写由两个参数共同控制,auto-aof-rewrite-percentage 和 auto-aof-rewrite-min-size,同时满⾜这两个条件,则触发 AOF 后台重写 BGREWRITEAOF。
关闭:auto-aof-rewrite-percentage 0,指定0的百分⽐,以禁⽤⾃动AOF重写功能。
REWRITEAOF:进⾏ AOF 重写,但是会阻塞主进程,服务器将⽆法处理客户端发来的命令请求,通常不会直接使⽤该命令。
BGREWRITEAOF:fork ⼦进程来进⾏ AOF 重写,阻塞只会发⽣在 fork ⼦进程的时候,之后主进程可以正常处理请求。
REWRITEAOF 和 BGREWRITEAOF 的关系与 SAVE 和 BGSAVE 的关系类似。
AOF 后台重写存在的问题
AOF 后台重写使⽤⼦进程进⾏从写,解决了主进程阻塞的问题,但是仍然存在另⼀个问题:⼦进程在进⾏ AOF 重写期间,服务器主进程还需要继续处理命令请求,新的命令可能会对现有的数据库状态进⾏修改,从⽽使得当前的数据库状态和重写后的 AOF ⽂件保存的数据库状态不⼀致。
如何解决 AOF 后台重写存在的数据不⼀致问题
为了解决上述问题,Redis 引⼊了 AOF 重写缓冲区(aof_rewrite_buf_blocks),这个缓冲区在服务器创建⼦进程之后开始使⽤,当 Redis 服务器执⾏完⼀个写命令之后,它会同时将这个写命令追加到 AOF 缓冲区和 AOF 重写缓冲区。
这样⼀来可以保证: 1、现有 AOF ⽂件的处理⼯作会如常进⾏。这样即使在重写的中途发⽣停机,现有的 AOF ⽂件也还是安全的。
2、从创建⼦进程开始,也就是 AOF 重写开始,服务器执⾏的所有写命令会被记录到 AOF 重写缓冲区⾥⾯。 这样,当⼦进程完成 AOF 重写⼯作后,⽗进程会在 serverCron 中检测到⼦进程已经重写结束,则会执⾏以下⼯作:
1、将 AOF 重写缓冲区中的所有内容写⼊到新 AOF ⽂件中,这时新 AOF ⽂件所保存的数据库状态将和服务器当前的数据库状态⼀致。
2、对新的 AOF ⽂件进⾏改名,原⼦的覆盖现有的 AOF ⽂件,完成新旧两个 AOF ⽂件的替换。 之后,⽗进程就可以继续像往常⼀样接受命令请求了。
20、RDB、AOF、混合持久,我应该⽤哪⼀个?
⼀般来说, 如果想尽量保证数据安全性, 你应该同时使⽤ RDB 和 AOF 持久化功能,同时可以开启混合持久化。
如果你⾮常关⼼你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使⽤ RDB 持久化。
如果你的数据是可以丢失的,则可以关闭持久化功能,在这种情况下,Redis 的性能是最⾼的。
使⽤ Redis 通常都是为了提升性能,⽽如果为了不丢失数据⽽将 appendfsync 设置为 always 级别时,对 Redis 的性能影响是很⼤的,在这种不能接受数据丢失的场景,其实可以考虑直接选择 MySQL 等类似的数据库。
