【模型+代码/保姆级教程】使用Pytorch实现手写汉字识别
鉴于已经3202年了,GPT4都出来了,网上还是缺乏汉字识别这种“底层”基础神经网络的能让新手直接上手跑通的手把手教程,我就斗胆自己写一篇好了。
本文的主要特点:
使用EfficientNetV2模型真正实现3755类汉字识别
项目开源
预训练模型公开
预制数据集,无需处理直接使用
数据集
使用中科院制作的手写汉字数据集,链接直达官网,所以我这里不多介绍,只有满腔敬意。
上面参考的博客可能要你自己下载之后按照它的办法再预处理一下,但是在这个环节出现问题的朋友挺多,本着保姆级教程教程的原则,我把预处理的数据已经传到北航云盘(貌似有损坏,先用评论区的链接)了,速度应该比百度网盘快吧,大概…
预训练模型已经上传了(后面有链接),但是如果想自己训一下,就需要下载这个数据集,解压到项目结构里的data文件夹如下所示
data文件夹和log文件夹需要自己建。
项目结构
————————————————
完整源代码
目录结构
重点注意data文件夹的结构,不要把数据集放错位置了或者多嵌套了文件夹
神经网络模型
预训练模型参数链接(包含vgg19和efficientnetv2)
请将.pth文件重命名为log+数字.pth的格式,例如log1.pth,放入log文件夹。方便识别和retrain。
VGG19
这里先后用了两种神经网络,我先用VGG19试了一下,分类前1000种汉字。训得有点慢,主要还是这模型有点老了,参数量也不小。而且要改到3755类的话还用原参数的话就很难收敛,也不知道该怎么调参数了,估计调好了也会规模很大,所以这里VGG19模型的版本只能分类1000种,就是数据集的前1000种(准确率>92%)。
EfficientNetV2
这个模型很不错,主要是卷积层的部分非常有效,参数量也很少。直接用small版本去分类3755个汉字,半小时就收敛得差不多了。所以本文用来实现3755类汉字的模型就是EfficientNetV2(准确率>89%),后面的教程都是基于这个,VGG19就不管了,在源码里感兴趣的自己看吧。
————————————————
运行环境
显存>=4G(与batchSize有关,batchSize=512时显存占用4.8G;如果是256或者128,应该会低于4G,虽然会导致训得慢一点)
内存>=16G(训练时不太占内存,但是刚开始加载的时候会突然占一下,如果小于16G还是怕爆)
如果你没有安装过Pytorch,啊,我也不知道怎么办,你要不就看看安装Pytorch的教程吧。(总体步骤是,有一个不太老的N卡,先去驱动里看看cuda版本,安装合适的CUDA,然后根据CUDA版本去pytorch.org找到合适的安装指令,然后在本地pip install)
以下是项目运行环境,我是3060 6G,CUDA版本11.6
这个约等号不用在意,可以都安装最新版本,反正我这里应该没用什么特殊的API
————————————————
数据集准备
首先定义classes_txt方法在Utils.py中(不是我写的,是CSDN那两篇博客的,MyDataset同):
生成每张图片的路径,存储到train.txt或test.txt。方便训练或评估时读取数据
定义Dataset类,用于制作数据集,为每个图片加上对应的标签,即图片所在文件夹的代号
入口
我把各种超参都放在了args里方便改,请根据实际情况自行调整。这套defaults就是我训练这个模型时使用的超参,图片size默认32是因为我显存太小辣!!但是数据集给的图片大小普遍不超过64,如果想训得更精确,可以试试64*64的大小。
如果你训练时爆mem,请调小batch_size,试试256,128,64,32
————————————————
训练
在前面CSDN博客的基础上,增加了lr_scheduler自行调整学习率(如果连续2个epoch无改进,就调小lr到一半),增加了连续训练的功能:
先在log文件夹下寻找是否存在参数文件,如果没有,就认为是初次训练;如果有,就找到后缀数字最大的log.pth,在这个基础上继续训练,并且每训练完一个epoch,就保存最新的log.pth,代号是上一次的+1。这样可以多次训练,防止训练过程中出错,参数文件损坏前功尽弃。
其中has_log_file和find_max_log在Utils.py中有定义。
————————————————
评估
没什么好说的,就是跑测试集,算总体准确率。但是有一点不完善,就是看不到每一个类具体的准确率。我的预训练模型其实感觉有几类是过拟合的,但是我懒得调整了。
推理
输入文字图片,输出识别结果:
其中char_dict就是每个汉字在数据集里的代号对应的gb2312编码,这个模型的输出结果是它在数据集里的代号,所以要查这个char_dict来获取它对应的汉字。
例如输入图片为: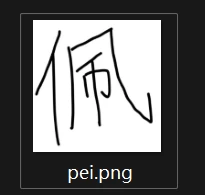
程序运行结果: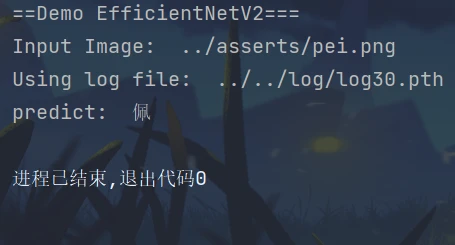
其他说明
这个模型我正在尝试移植到安卓应用,因为Pytorch有一套Pytorch for Android,但是现在遇到一个问题,它的bitmap2Tensor函数内部实现与Pytorch的toTensor()+Normalize()不一样,导致输入相同的图片,转出来的张量是不一样的,比如我输入的图片是白底黑字,白底的部分输出一样,但是黑色的部分的数值出现了偏移,我用的是同一套归一化参数,不知道这是为什么。然后这个张量的差异就导致安卓端表现很不好,目前正在寻找解决办法,灰阶处理可能是出路?
另外,这个模型对于太细太黑的字体,准确度貌似不是很好,可能还是有点过拟合了。建议输入的图片与数据集的风格靠拢,黑色尽量浅一点,线不要太细。
————————————————
为大家准备了本项目所需的源代码!深度学习以及计算机视觉学习资料!可论文指导1对1付费咨询!
可添加VX公众号:【AI技术星球】,回复369免费领学习资料!
【1】人工智能学习课程及配套资料
【2】超详解人工智能学习路线图及学习大纲
【3】学人工智能必看优质书籍电子书汇总
【4】人工智能面试题库大全以及问题总结
【5】人工智能经典论文100篇+解读+复现教程
【6】计算机视觉技术教学课程+YOLO等项目教学
【7】人工智能最新行业报告
