What's New in DataGrip 2021.1
What's New in DataGrip 2021.1
Today we’re introducing DataGrip 2021.1, our first major release this year and possibly the most
remarkable release in the history of our IDE. We hope you will find that v2021.1 addresses at least
one of your pain points, or maybe you will discover a new feature you’ll love, or both. Let’s dive
in!
UI for grants
This is available for PostgreSQL, Redshift, Greenplum, MySQL, MariaDB, DB2, SQL Server, and Sybase.
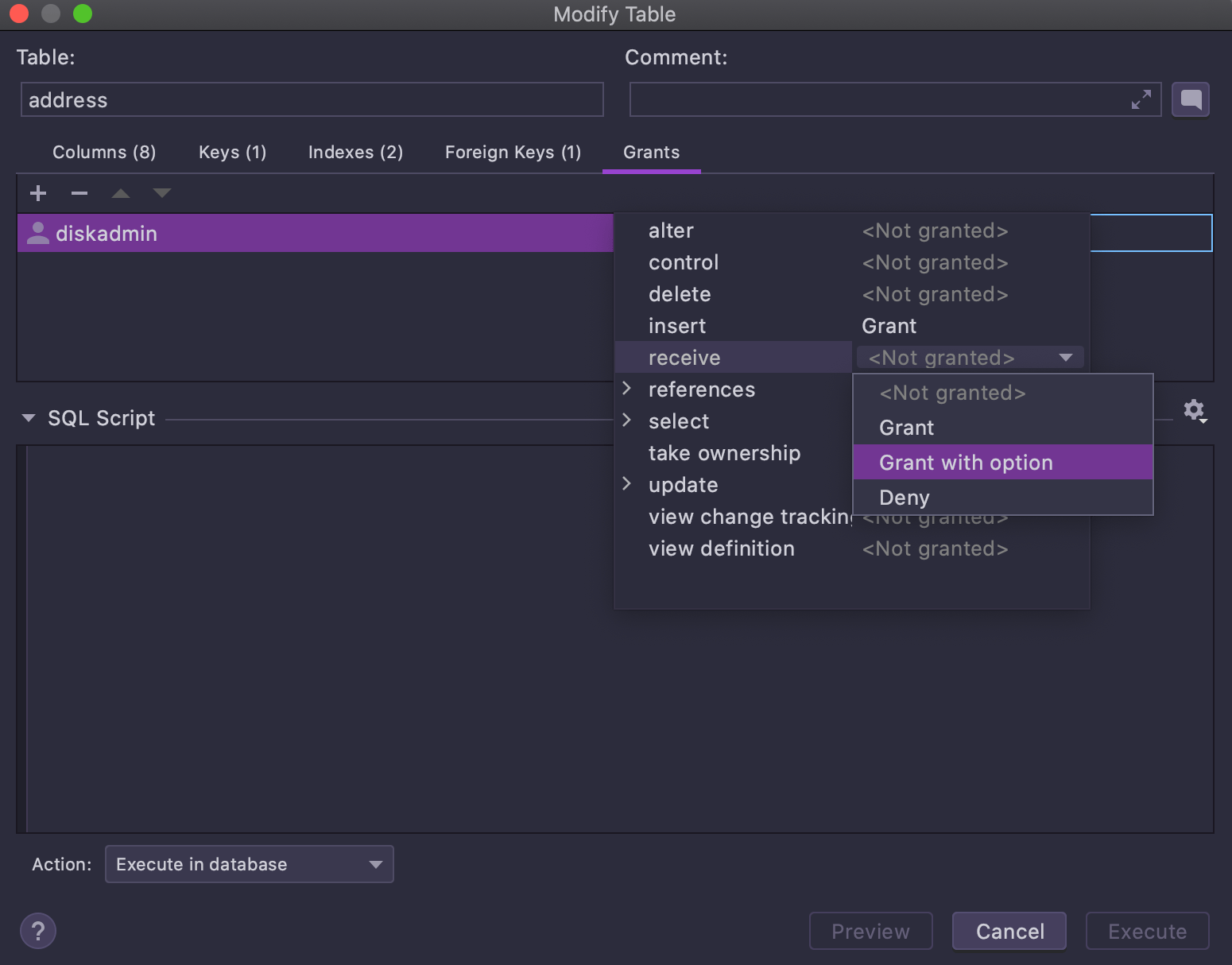 We’ve added a UI for editing grants when modifying objects.
We’ve added a UI for editing grants when modifying objects.
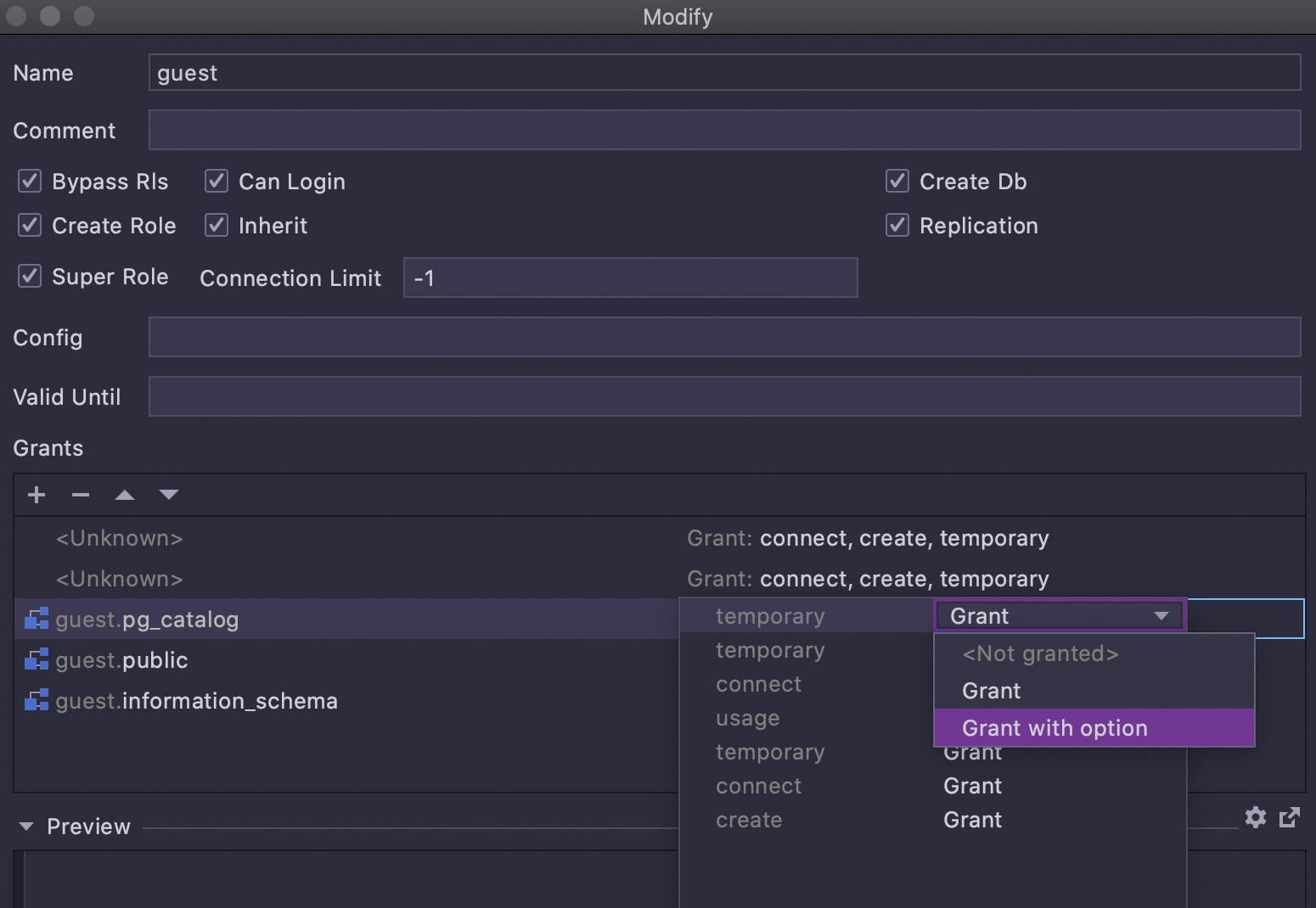 The Modify user window, which you can invoke on a user in the database explorer
with Cmd/Ctrl+F6, now has a UI for adding grants to objects:
Context Live Templates
The Modify user window, which you can invoke on a user in the database explorer
with Cmd/Ctrl+F6, now has a UI for adding grants to objects:
Context Live Templates
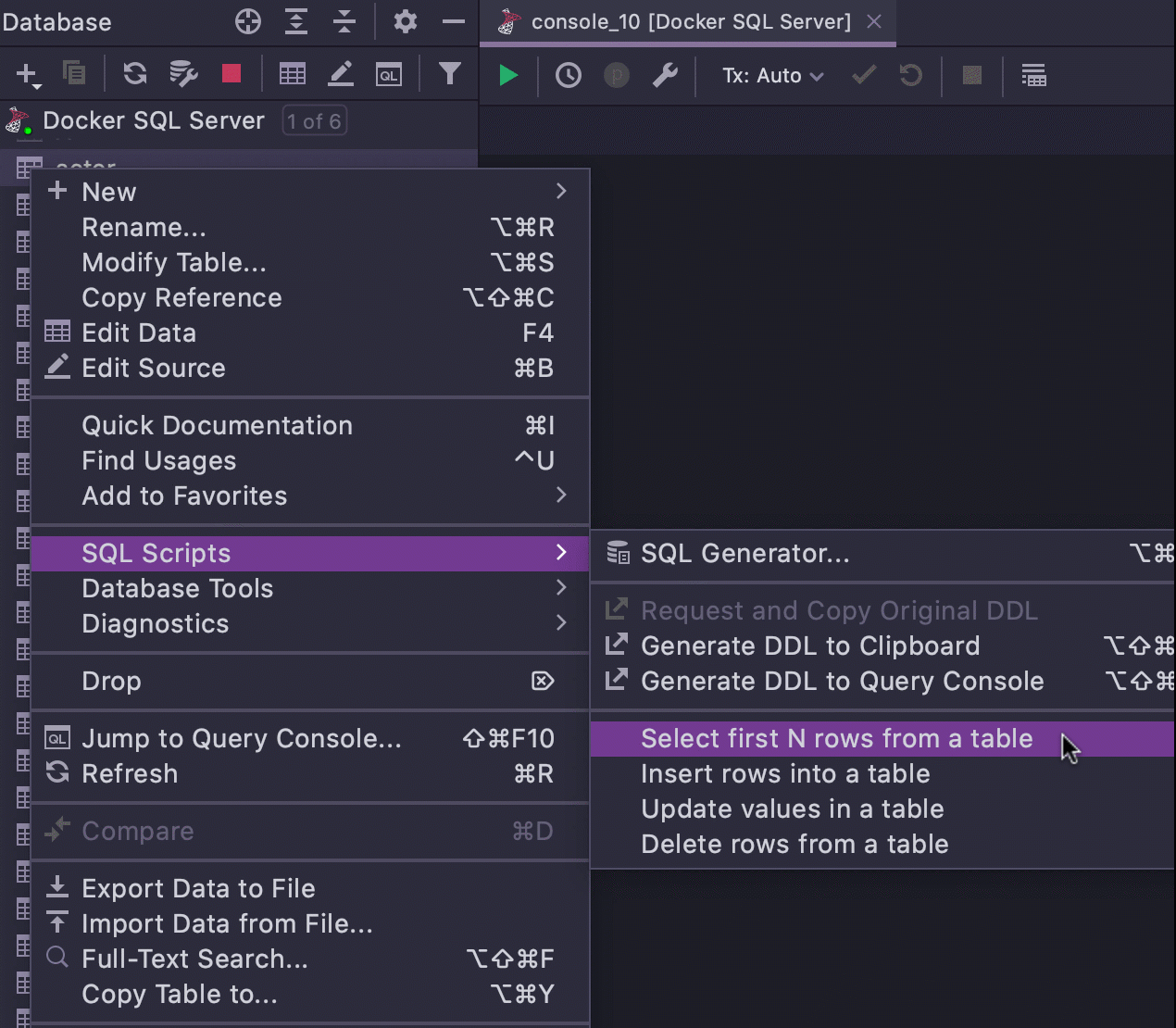 This is our solution for anyone wanting to generate simple statements straight from the
database explorer. General Live Templates cover many cases where you need to write a
simple query quickly. But we also understand that sometimes, when you are in the context
of the database explorer and you are already focusing on the object you need, there is a
better way to get a simple query using that object.
And of course, many other tools also use this mechanism for reducing repetitive work, so
many users are already used to it.
Here’s a short video that shows how it works:
This is our solution for anyone wanting to generate simple statements straight from the
database explorer. General Live Templates cover many cases where you need to write a
simple query quickly. But we also understand that sometimes, when you are in the context
of the database explorer and you are already focusing on the object you need, there is a
better way to get a simple query using that object.
And of course, many other tools also use this mechanism for reducing repetitive work, so
many users are already used to it.
Here’s a short video that shows how it works:
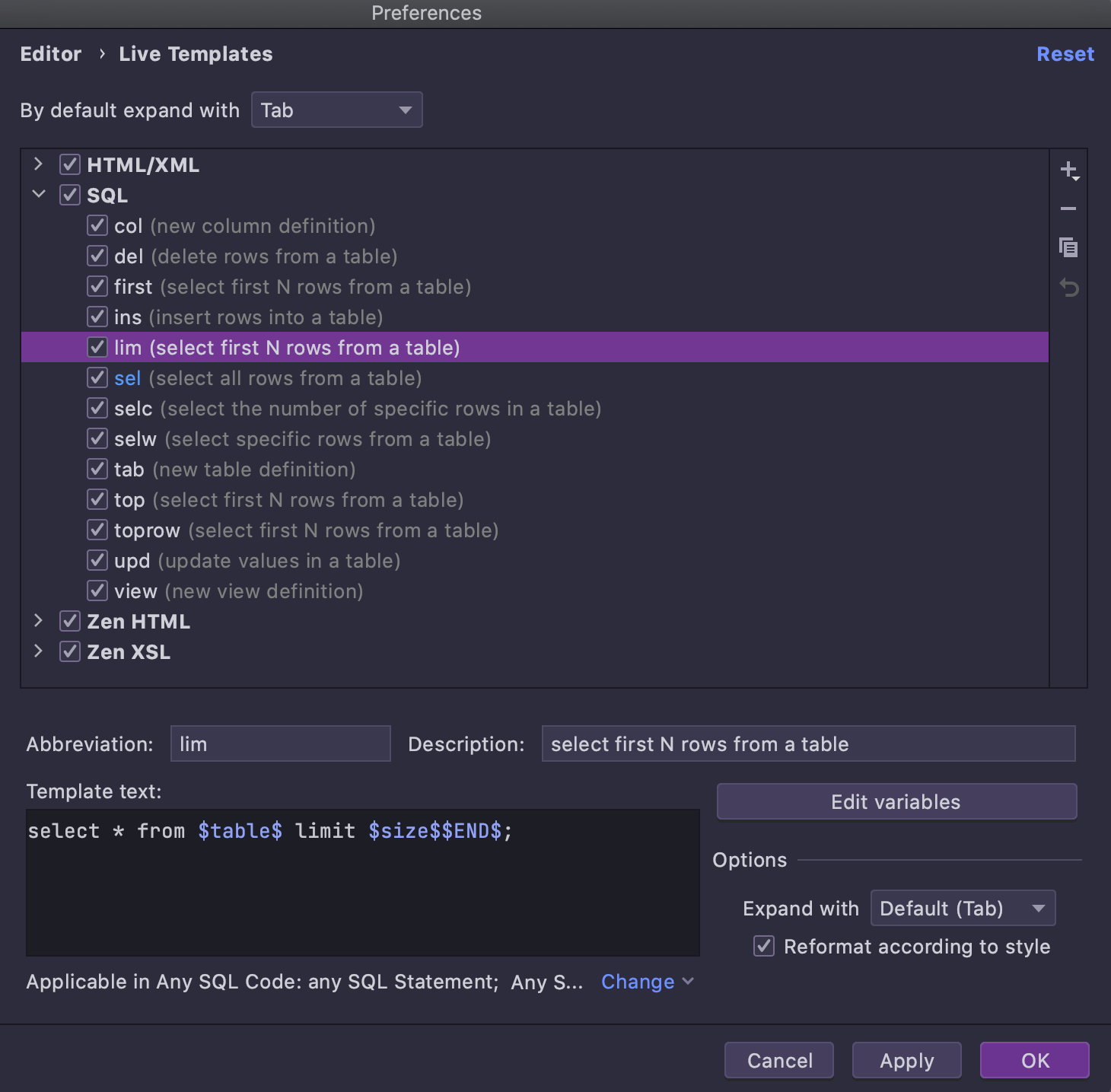 Every code snippet in this list is actually a live template, but they are all special
ones that can be generated in the context of the chosen object. For example, let's look
at the Select first N rows from a table template.
Open the Live Templates settings page and locate the template you need:
Every code snippet in this list is actually a live template, but they are all special
ones that can be generated in the context of the chosen object. For example, let's look
at the Select first N rows from a table template.
Open the Live Templates settings page and locate the template you need:
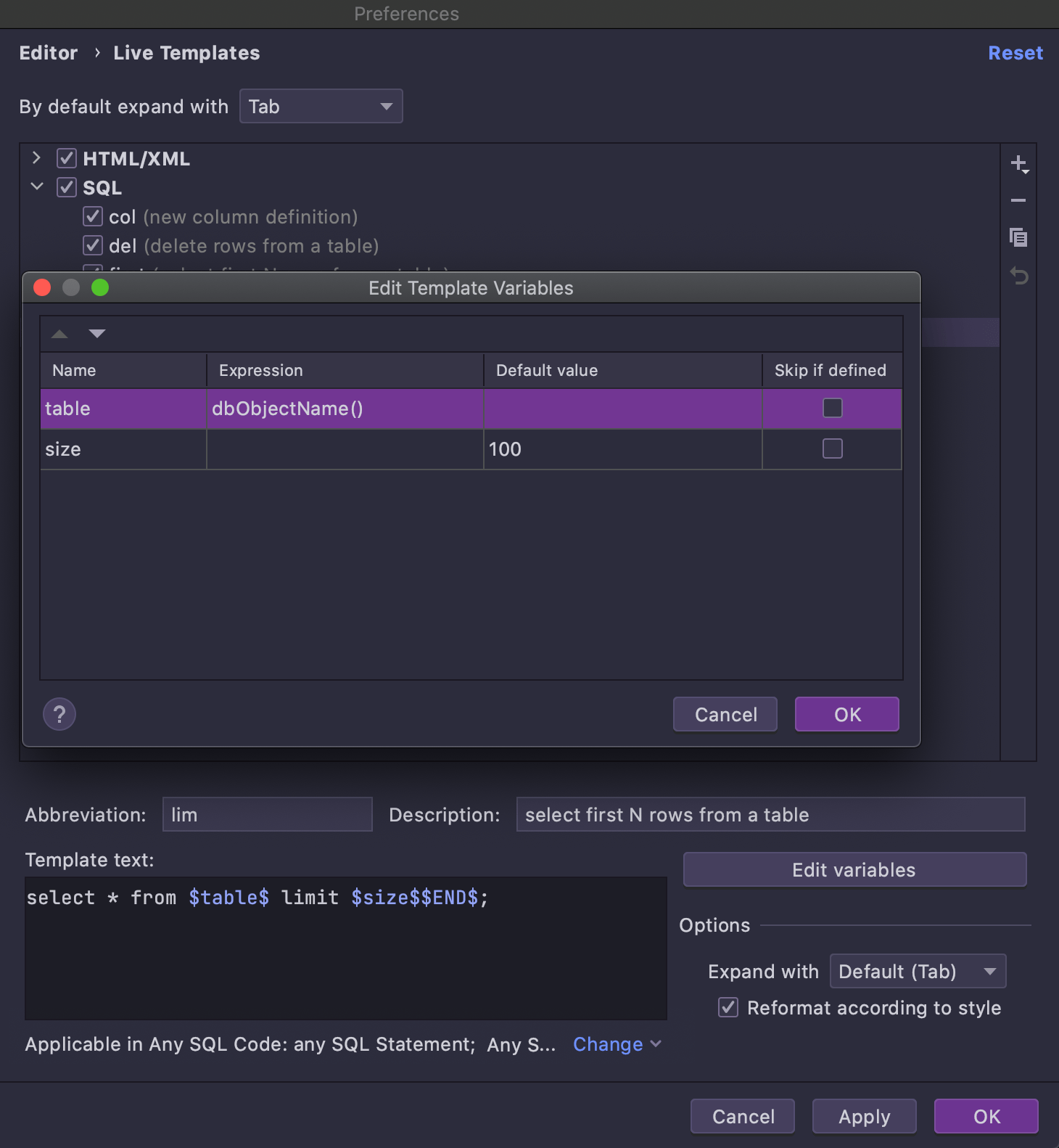 Select first N rows from a table looks like a general template (and can be used
as such). Since this particular syntax cannot be used in all databases, the
corresponding dialects are set for the template. The major difference that makes this
template applicable in the database explorer is the special expression
dbObjectName, which is used for the $table$ variable:
Select first N rows from a table looks like a general template (and can be used
as such). Since this particular syntax cannot be used in all databases, the
corresponding dialects are set for the template. The major difference that makes this
template applicable in the database explorer is the special expression
dbObjectName, which is used for the $table$ variable:
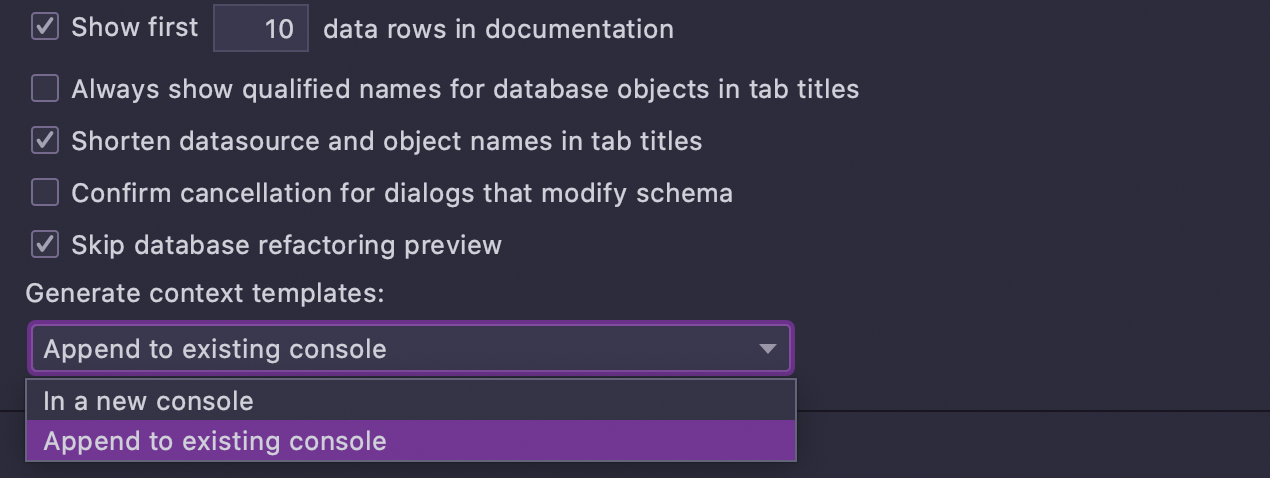 You can of course add your own templates or edit the existing ones.
In Settings/Preferences | Database | General choose whether you want your script
to be generated to the current console or a new one.
Data Editor
You can of course add your own templates or edit the existing ones.
In Settings/Preferences | Database | General choose whether you want your script
to be generated to the current console or a new one.
Data Editor
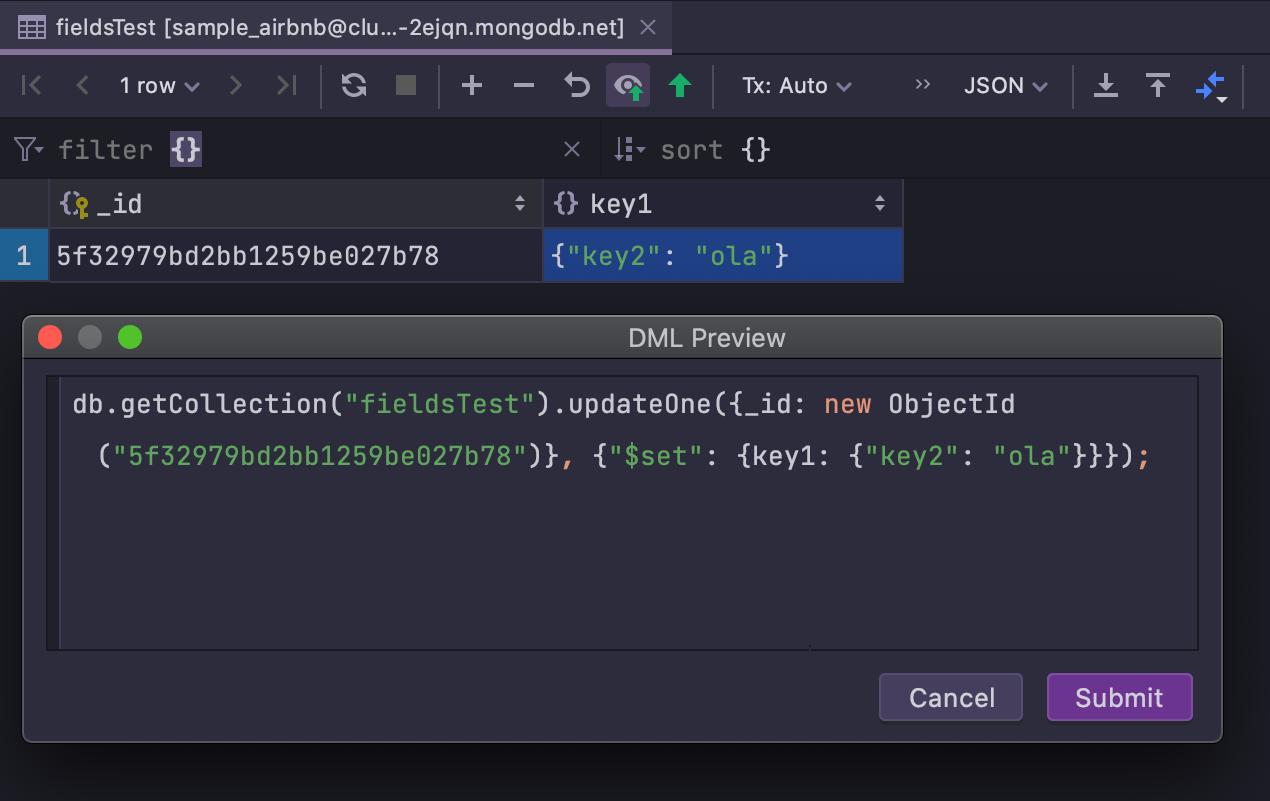 Edit data in MongoDB
We’ve added a crucial feature for working with MongoDB: starting with this version, you
can edit data in MongoDB collections. A statement preview is also available.
Edit data in MongoDB
We’ve added a crucial feature for working with MongoDB: starting with this version, you
can edit data in MongoDB collections. A statement preview is also available.
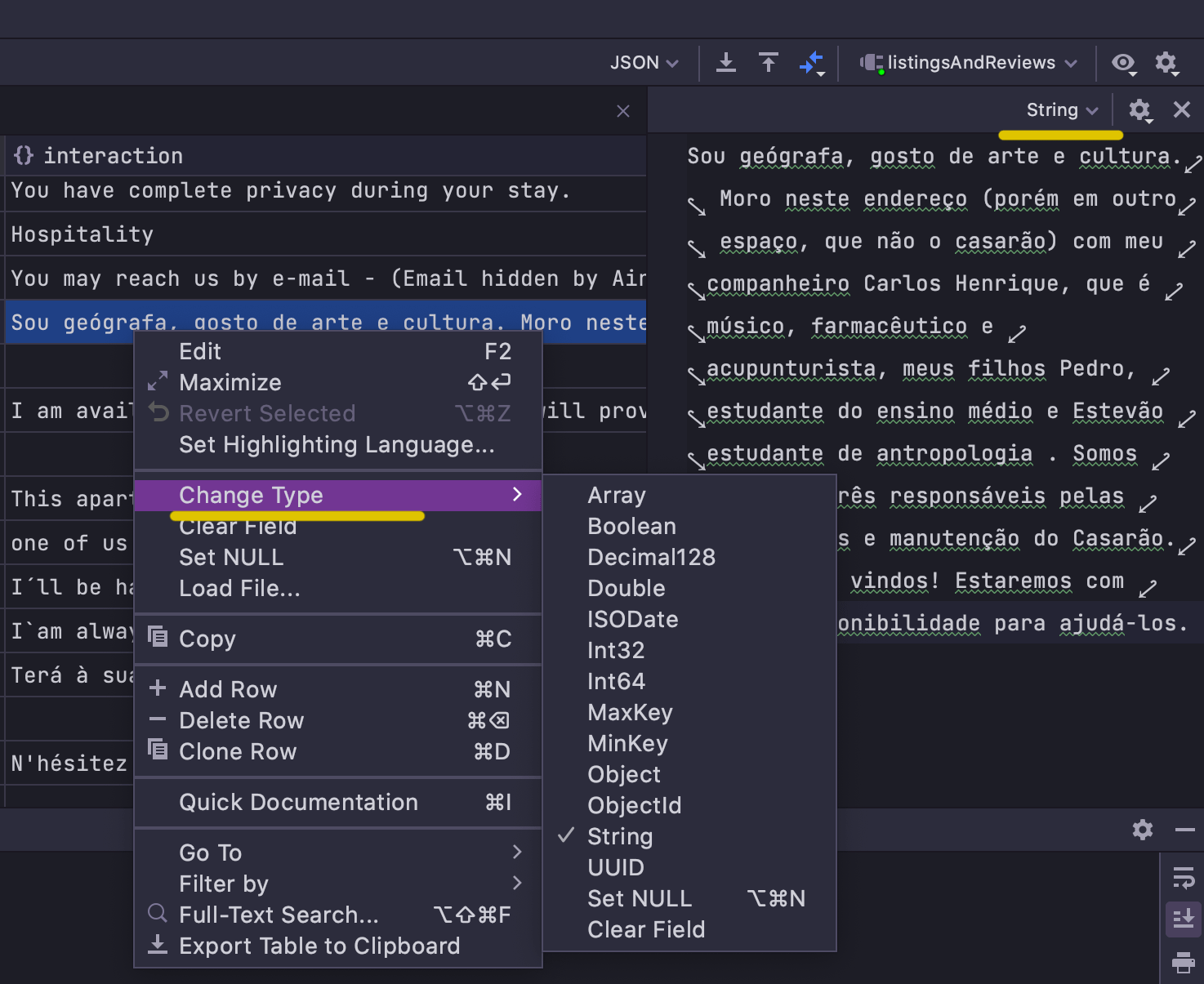 To make editing more flexible, we’ve introduced the ability to change the type of a
field from the UI. This can be done either from the context menu of the field or in the
value editor:
To make editing more flexible, we’ve introduced the ability to change the type of a
field from the UI. This can be done either from the context menu of the field or in the
value editor:
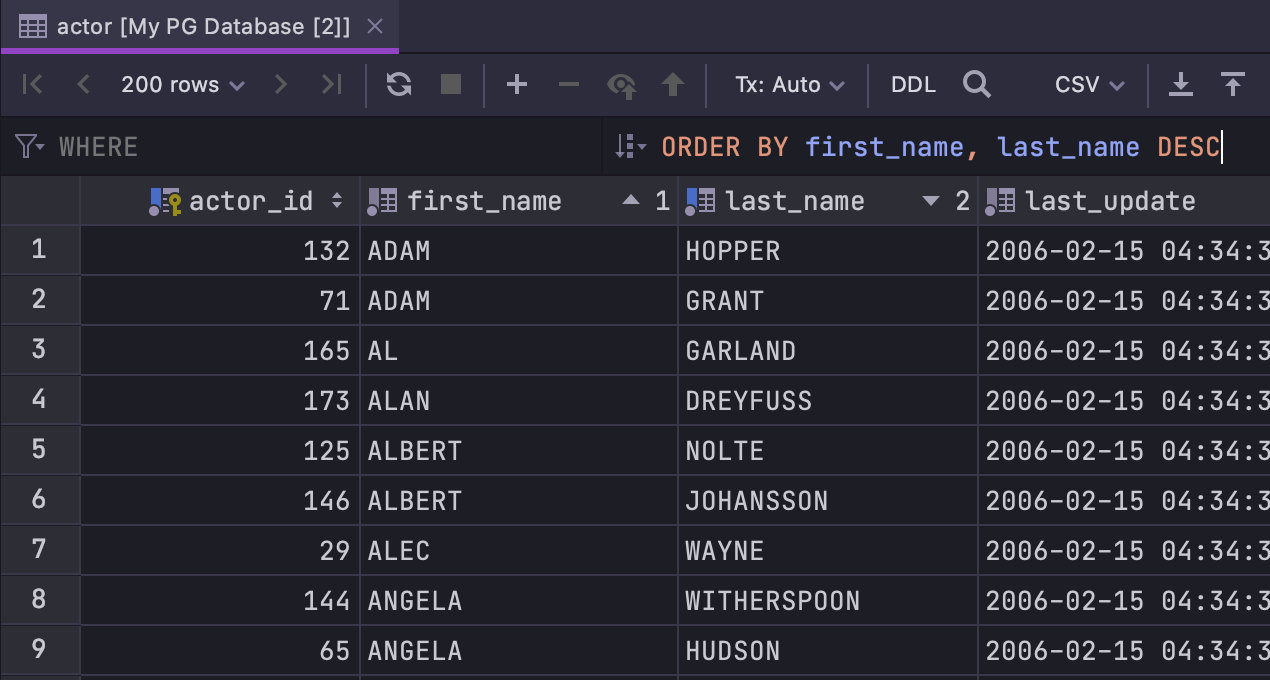 Better sorting
We’ve improved the sorting of data:
A new field works similar to the field
(which was called Filter before): enter a working clause to have it applied
to the query of the grid.
The sorting is not ‘stacked’ by default. If you click on the name of a column you
want to use to sort data, the sorting based on other columns will be cleared. If you
would prefer to use stacked sorting, click a column name while holding the
Alt key.
Better sorting
We’ve improved the sorting of data:
A new field works similar to the field
(which was called Filter before): enter a working clause to have it applied
to the query of the grid.
The sorting is not ‘stacked’ by default. If you click on the name of a column you
want to use to sort data, the sorting based on other columns will be cleared. If you
would prefer to use stacked sorting, click a column name while holding the
Alt key.
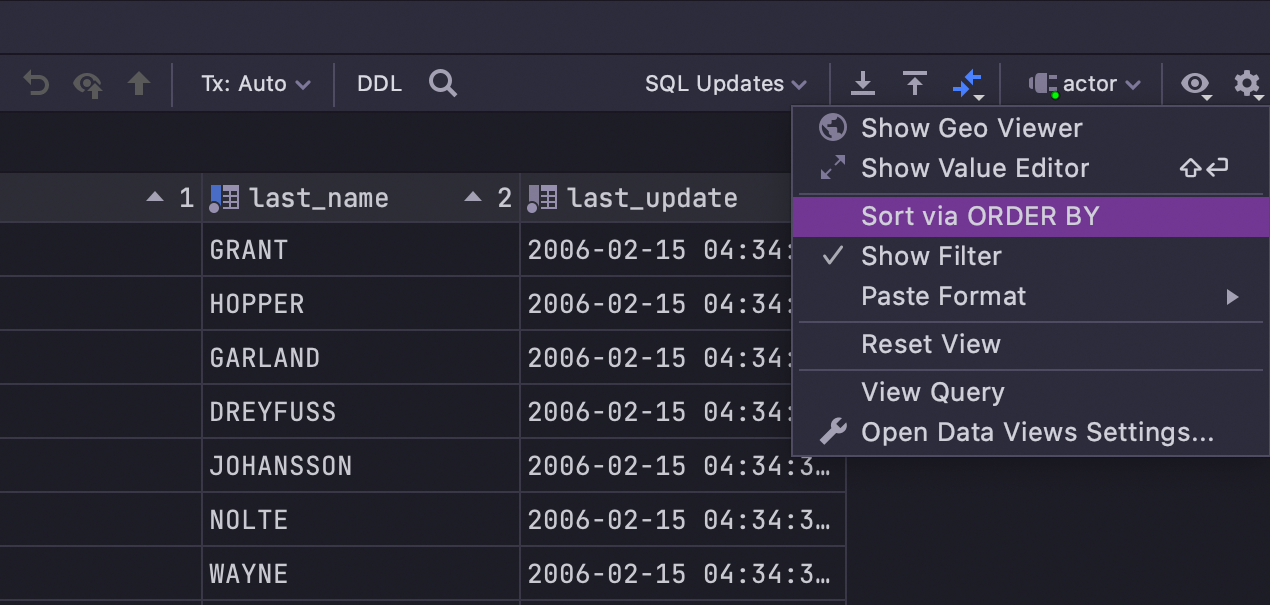 If you want to use sorting on the client side (which means DataGrip will not rerun
the query, but will sort the data within the current page instead), uncheck
Sort via ORDER BY:
If you want to use sorting on the client side (which means DataGrip will not rerun
the query, but will sort the data within the current page instead), uncheck
Sort via ORDER BY:
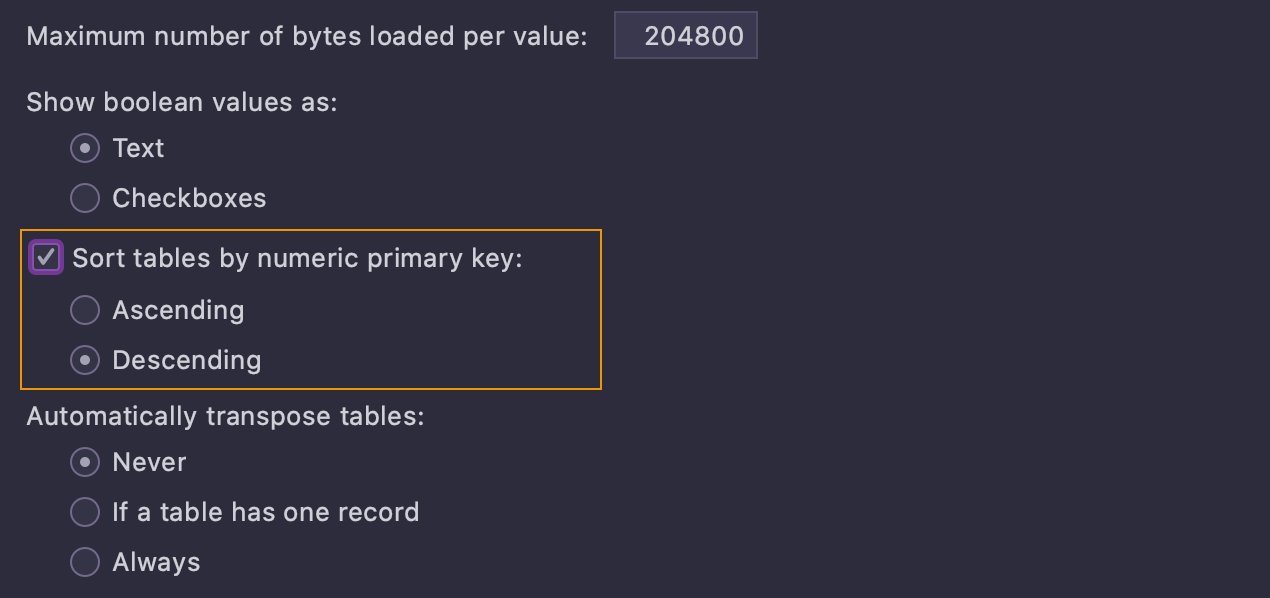 It's also possible to open tables with predefined sorting based on the numeric primary
key. This setting is placed in Settings/Preferences | Database | Data Views.
It's also possible to open tables with predefined sorting based on the numeric primary
key. This setting is placed in Settings/Preferences | Database | Data Views.
 New toolbar
We’ve reworked the toolbar in the data editor. The Roll-back and Commit
buttons are no longer displayed in automatic transaction mode, and there are two new
buttons, Revert changes and Find.
New toolbar
We’ve reworked the toolbar in the data editor. The Roll-back and Commit
buttons are no longer displayed in automatic transaction mode, and there are two new
buttons, Revert changes and Find.
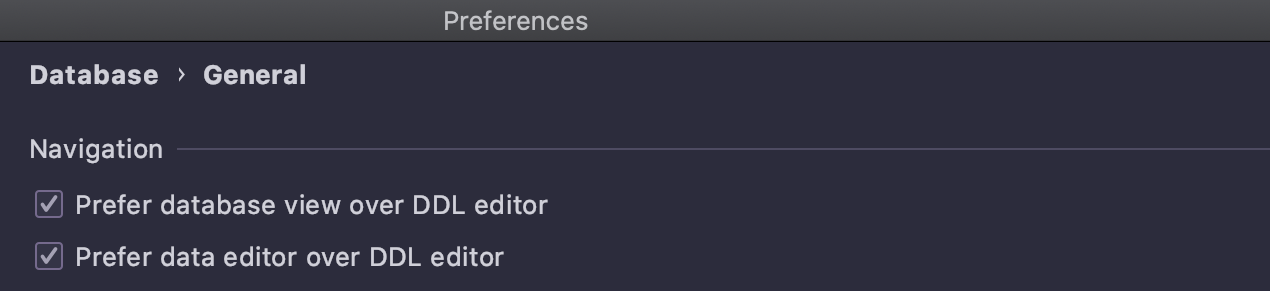 Straightforward actions
We’ve simplified the navigation and got rid of the following settings:
Straightforward actions
We’ve simplified the navigation and got rid of the following settings:
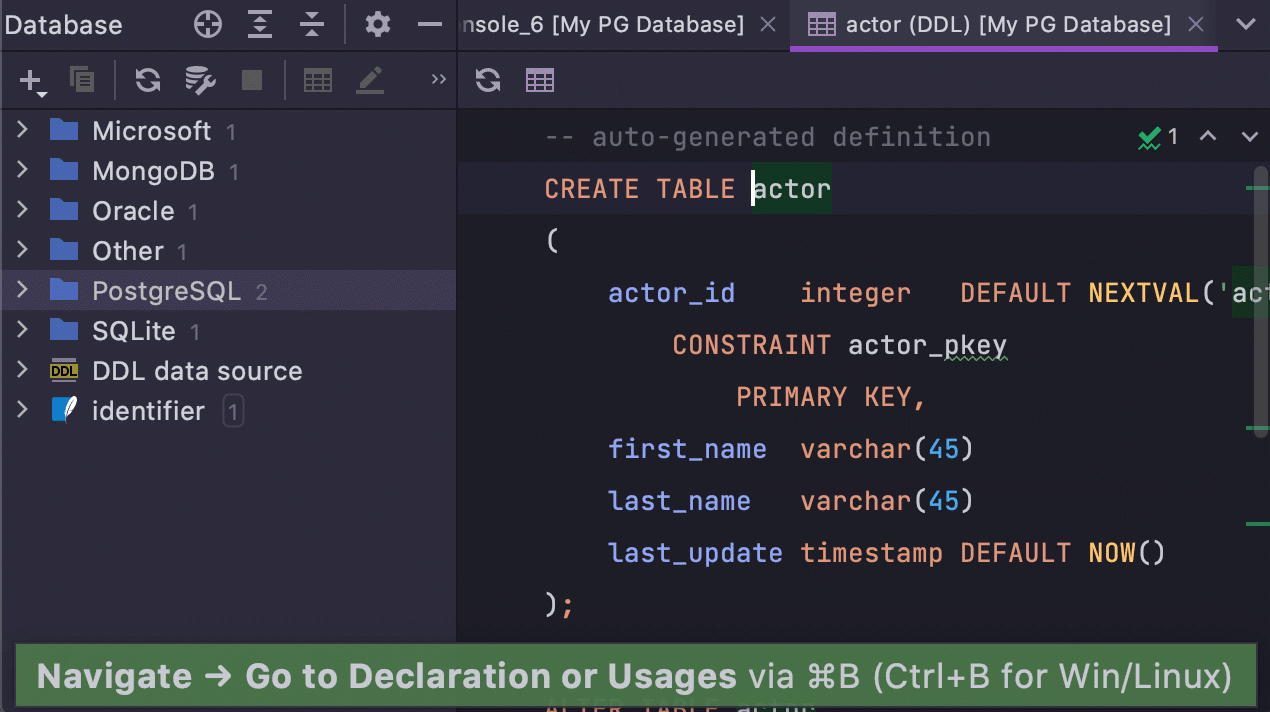 If you’ve never changed these settings and had the checkboxes marked by default, the
major change in 2021.1 for you is the following: Go to declaration
(Ctrl/Cmd+B) invoked on an object in SQL now takes you to the DDL, not to the
database tree.
We’ve also introduced a shortcut for the Select in database tree action:
Alt+Shift+B for Windows/Linux and Opt+Shift+B for macOS.
The main reason for this change is to make the logic more straightforward: each action
should take you to the place you expect it to.
Now, if you have the cursor on an object:
Ctrl/Cmd+B shows you the DDL.
F4 shows the data.
Alt/Opt+Shift+B highlights the object in the database tree.
We understand that some habits might be broken by this, and we’re ready to provide ways
to keep your previous experience. Some tips:
Know the power of the keymap. If you like using Ctrl/Cmd+B for opening
the database explorer, just remap the shortcut for Select in database tree.
If you like how Ctrl/Cmd+B or Ctrl/Cmd+Click opened the
CREATE definition when the object used in SQL hasn’t yet been created, just
don’t remove these shortcuts from Go to declaration after doing the remapping
in the previous tip.
If you use the unchecked Prefer data editor over DDL editor setting and like
how double-click opens the DDL, this behavior can be brought back by changing the
value of the
registry key:
. According to our data, very
few users used this flow. We also recommend using shortcuts for opening the DDL for
objects.
If any use cases are no longer covered by this new flow, please let us know.
Connectivity
If you’ve never changed these settings and had the checkboxes marked by default, the
major change in 2021.1 for you is the following: Go to declaration
(Ctrl/Cmd+B) invoked on an object in SQL now takes you to the DDL, not to the
database tree.
We’ve also introduced a shortcut for the Select in database tree action:
Alt+Shift+B for Windows/Linux and Opt+Shift+B for macOS.
The main reason for this change is to make the logic more straightforward: each action
should take you to the place you expect it to.
Now, if you have the cursor on an object:
Ctrl/Cmd+B shows you the DDL.
F4 shows the data.
Alt/Opt+Shift+B highlights the object in the database tree.
We understand that some habits might be broken by this, and we’re ready to provide ways
to keep your previous experience. Some tips:
Know the power of the keymap. If you like using Ctrl/Cmd+B for opening
the database explorer, just remap the shortcut for Select in database tree.
If you like how Ctrl/Cmd+B or Ctrl/Cmd+Click opened the
CREATE definition when the object used in SQL hasn’t yet been created, just
don’t remove these shortcuts from Go to declaration after doing the remapping
in the previous tip.
If you use the unchecked Prefer data editor over DDL editor setting and like
how double-click opens the DDL, this behavior can be brought back by changing the
value of the
registry key:
. According to our data, very
few users used this flow. We also recommend using shortcuts for opening the DDL for
objects.
If any use cases are no longer covered by this new flow, please let us know.
Connectivity
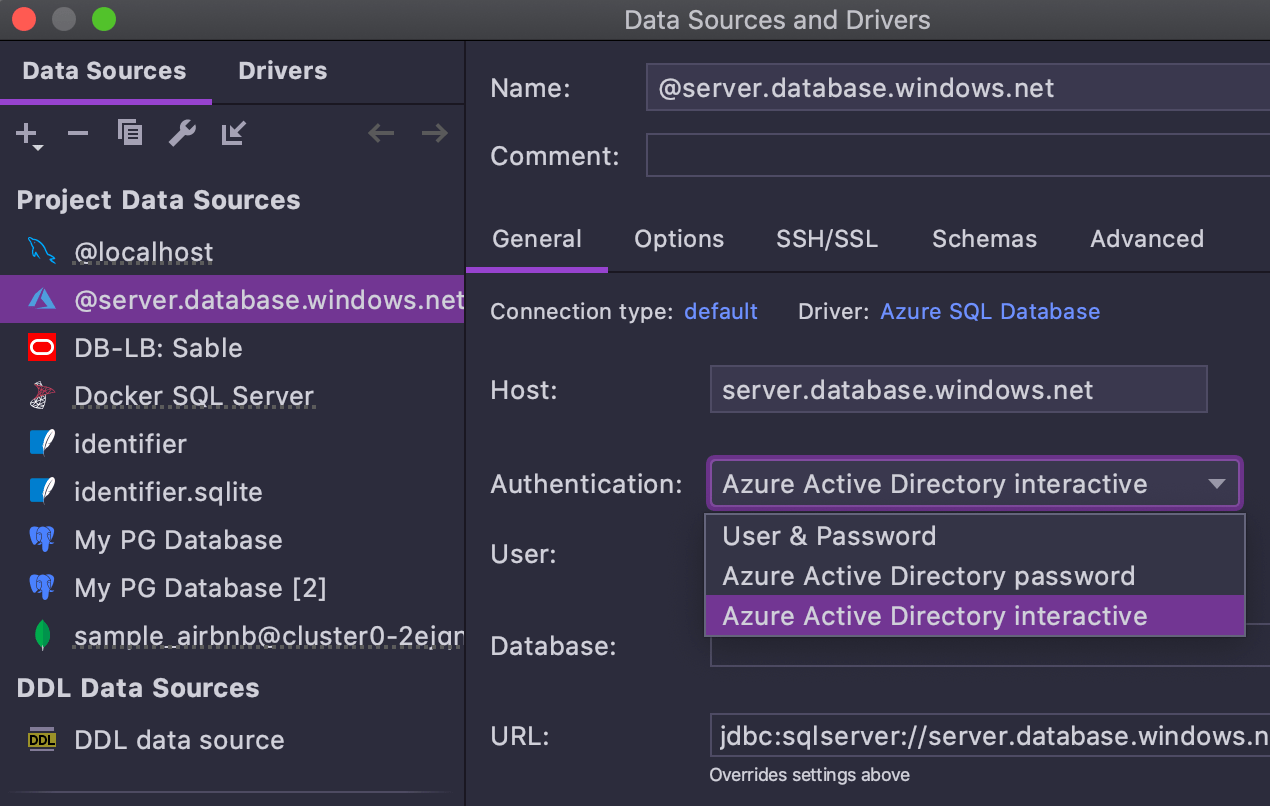 Azure MFA support
Azure Active Directory interactive authentication is supported. When it is enabled, the
browser will automatically open and let you log in.
Azure MFA support
Azure Active Directory interactive authentication is supported. When it is enabled, the
browser will automatically open and let you log in.
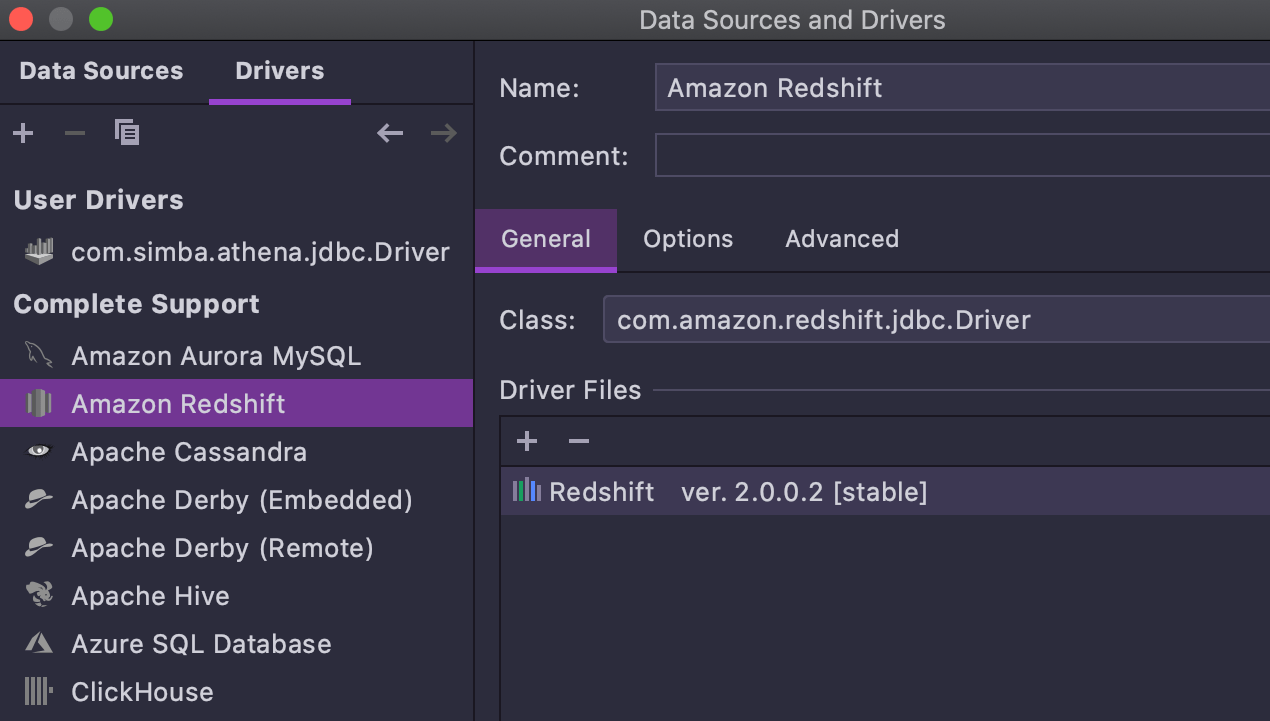 Redshift driver 2.x
The Redshift 2.x JDBC driver is available for DataGrip users starting with this version.
The major enhancement here is the
ability to cancel queries.
Redshift driver 2.x
The Redshift 2.x JDBC driver is available for DataGrip users starting with this version.
The major enhancement here is the
ability to cancel queries.
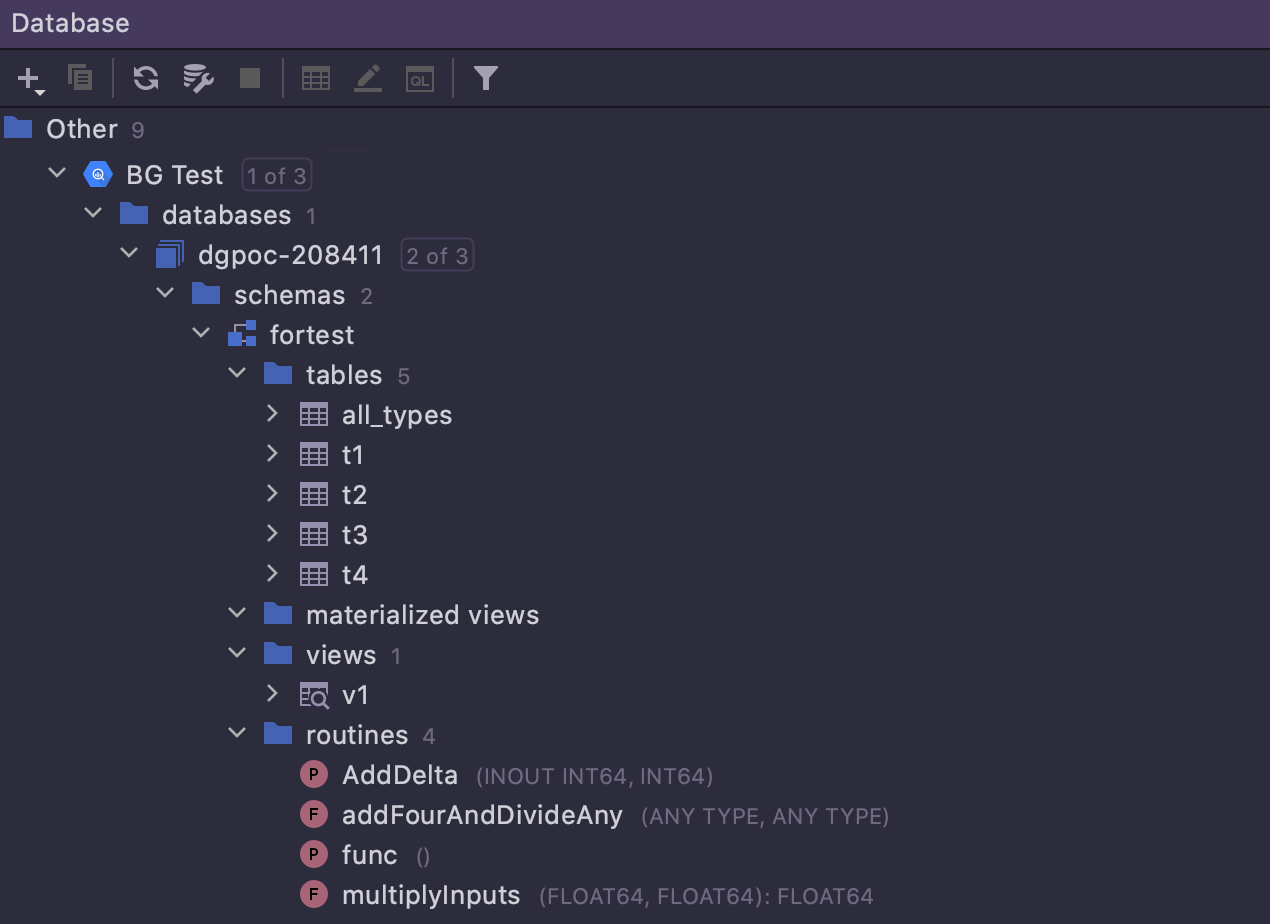 Google BigQuery full support
Support for Google BigQuery dialect was added in the previous release. We’ve expanded
it in this release so that database introspection and code generation now work properly
and are no longer dependent on the functionality of the JDBC driver.
Google BigQuery full support
Support for Google BigQuery dialect was added in the previous release. We’ve expanded
it in this release so that database introspection and code generation now work properly
and are no longer dependent on the functionality of the JDBC driver.
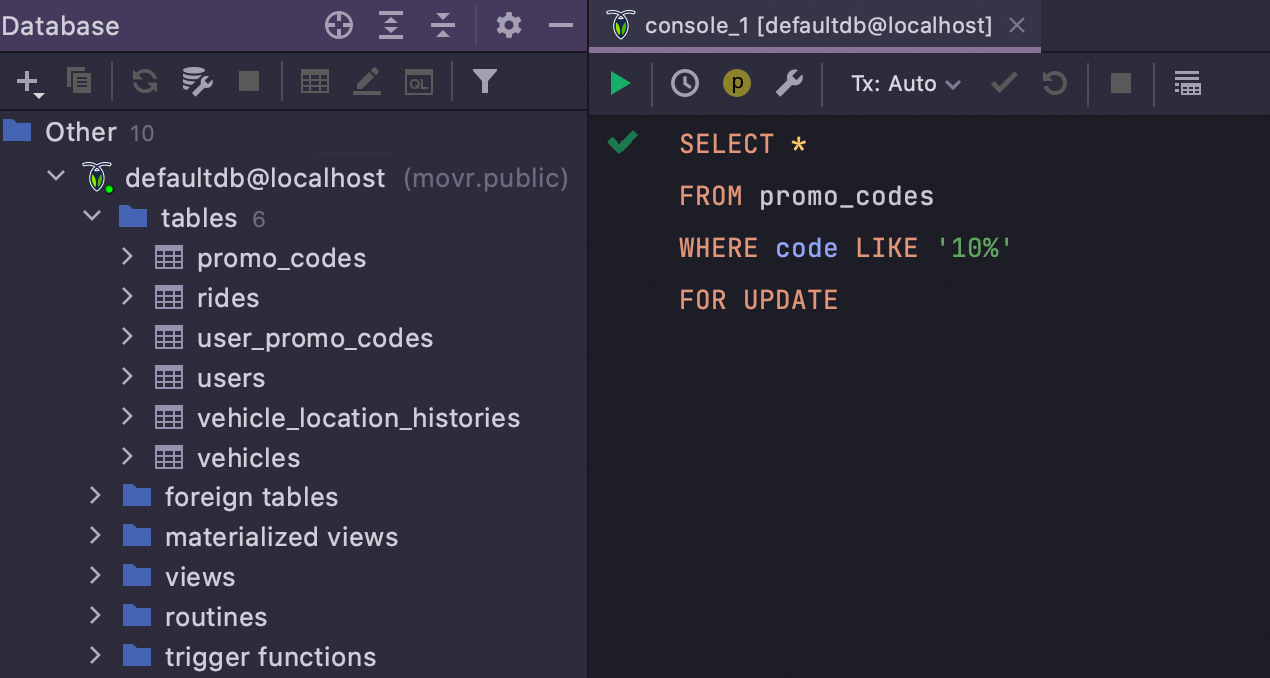 CockroachDB dialect support
Now if you work with the CockroachDB scripts or write SQL to query that database, your
code will be highlighted properly and all errors will be shown before you run the query.
This is the first step to full CockroachDB support, which is coming in one of the future
releases.
CockroachDB dialect support
Now if you work with the CockroachDB scripts or write SQL to query that database, your
code will be highlighted properly and all errors will be shown before you run the query.
This is the first step to full CockroachDB support, which is coming in one of the future
releases.
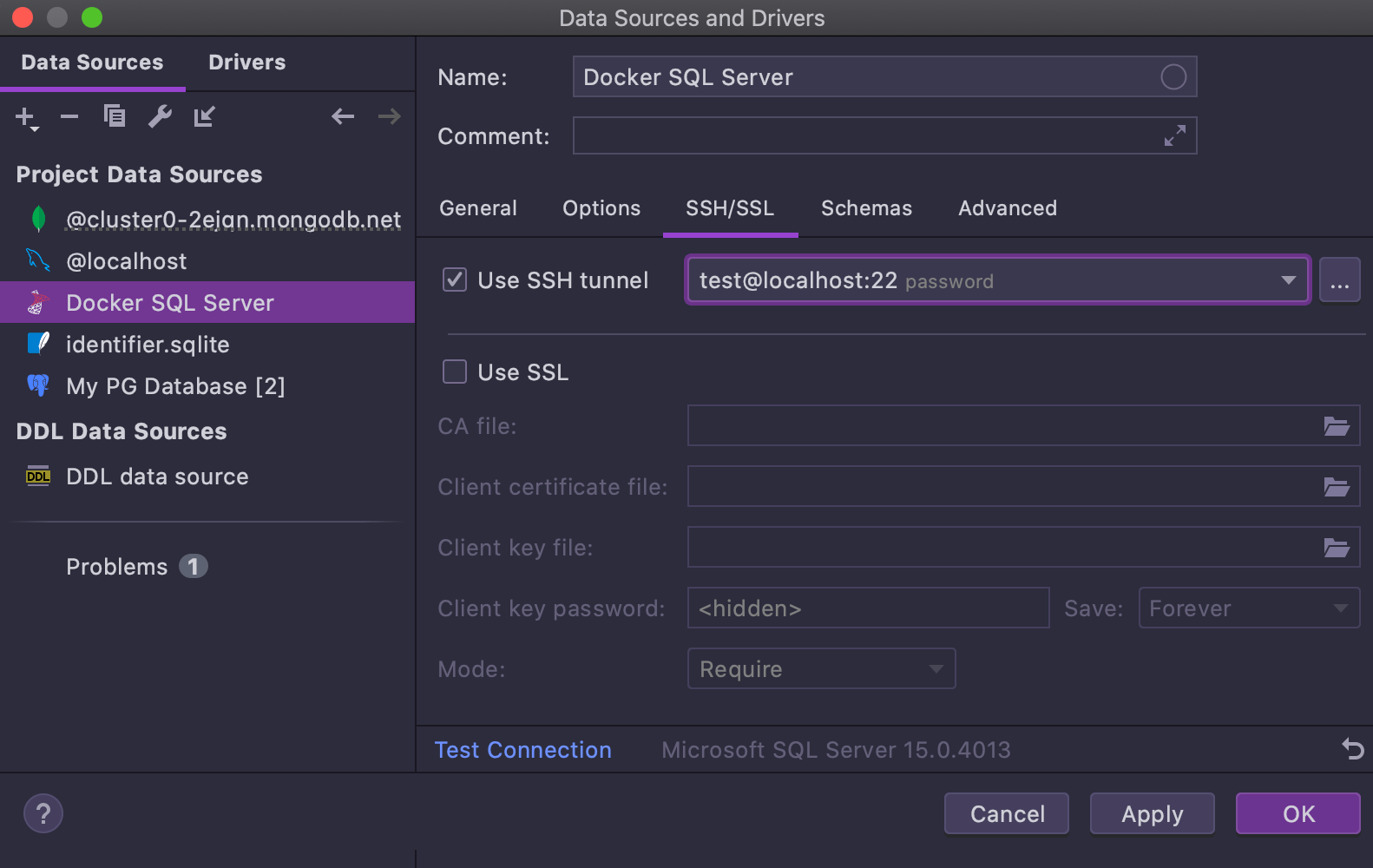 Improvements in the connection window
We’ve reworked the connection window to make it friendlier.
Drivers and data sources are now listed on two different tabs. The list of drivers
should not bother experienced users, while helping newcomers not confuse them with
data sources.
Every driver’s page includes a Create data source button.
The Test Connection button has been moved to the footer so that you can use
it from any tab of the data source properties, not only the
General and SSH/SSL tab as before.
The DDL data source properties page has a drop-down list for choosing the dialect.
Improvements in the connection window
We’ve reworked the connection window to make it friendlier.
Drivers and data sources are now listed on two different tabs. The list of drivers
should not bother experienced users, while helping newcomers not confuse them with
data sources.
Every driver’s page includes a Create data source button.
The Test Connection button has been moved to the footer so that you can use
it from any tab of the data source properties, not only the
General and SSH/SSL tab as before.
The DDL data source properties page has a drop-down list for choosing the dialect.
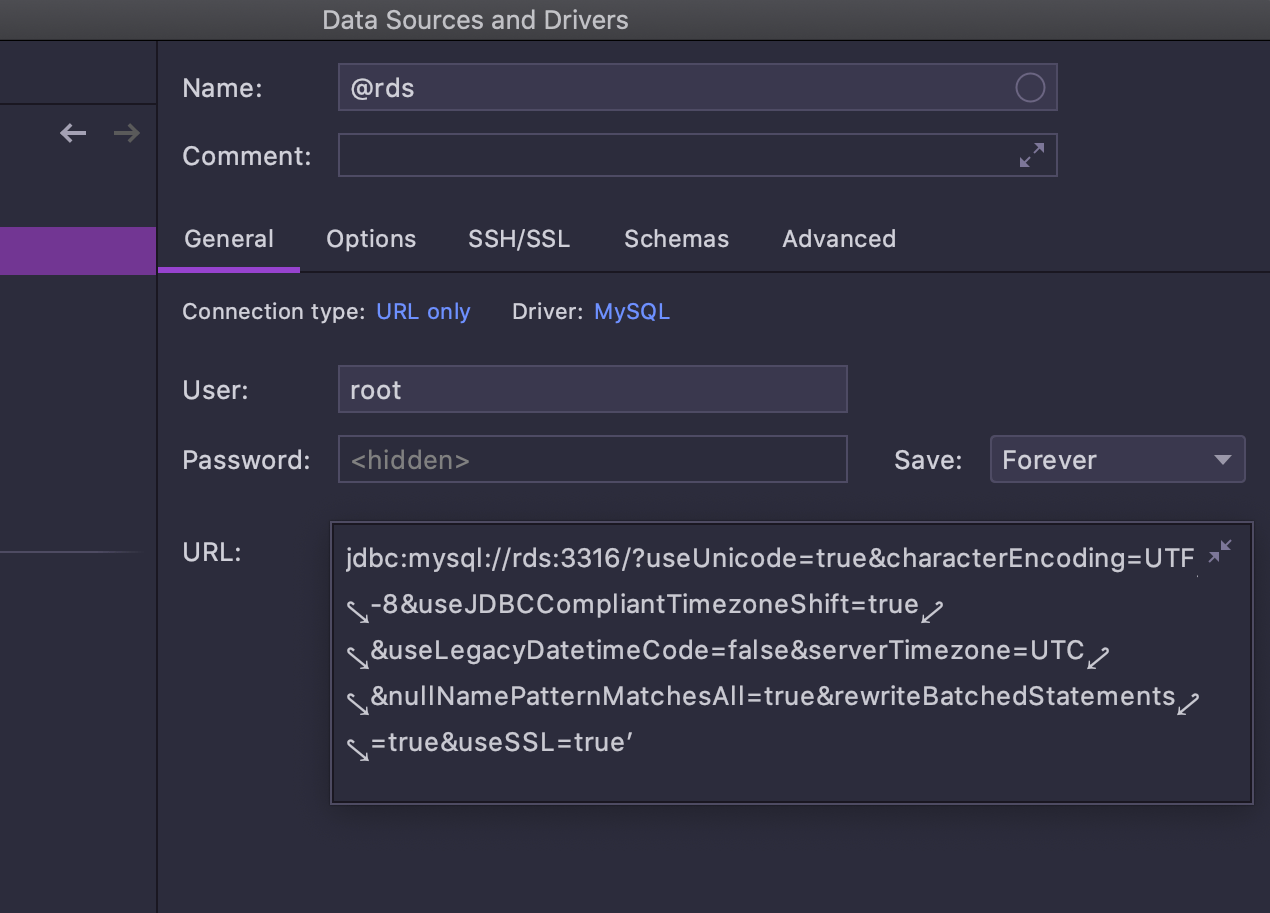 The URL field is expandable now, which makes it easier to handle long URLs.
Database explorer
The URL field is expandable now, which makes it easier to handle long URLs.
Database explorer
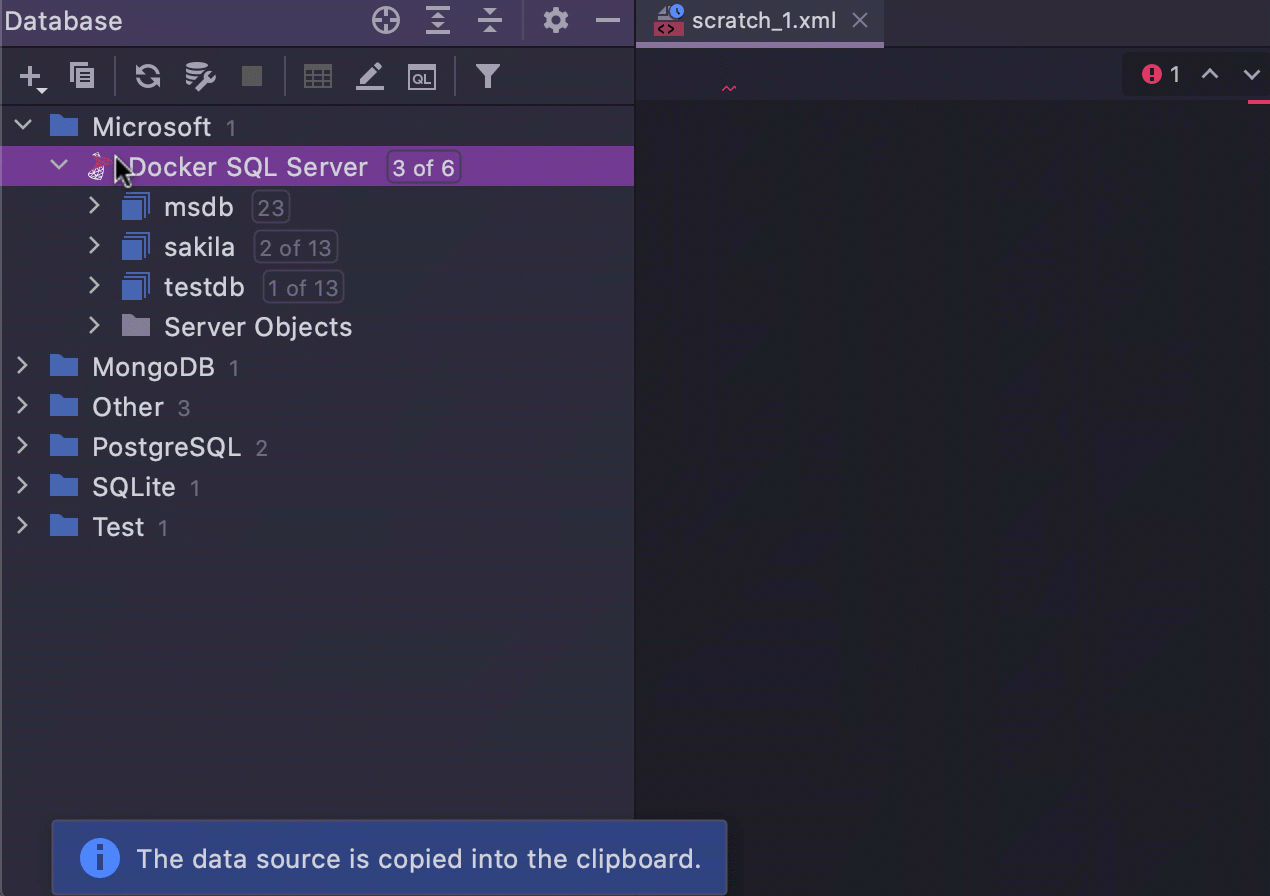 Easy copy-paste of data sources
The ability to copy and paste data sources was
introduced a long time ago. But starting with 2021.1, you can copy, cut, and paste data
sources using some of the most famous shortcuts in the world: Ctrl/Cmd+C/V/X.
When you copy a data source, the XML is copied to the clipboard, which you can then
share via a messenger. You can also use the Paste action to paste a piece of
XML from somewhere else.
If you cut and paste a data source inside one project, it will be just moved, no
password required. But the password is required in all the other cases.
A Cut can be undone with Ctrl/Cmd+Z.
Easy copy-paste of data sources
The ability to copy and paste data sources was
introduced a long time ago. But starting with 2021.1, you can copy, cut, and paste data
sources using some of the most famous shortcuts in the world: Ctrl/Cmd+C/V/X.
When you copy a data source, the XML is copied to the clipboard, which you can then
share via a messenger. You can also use the Paste action to paste a piece of
XML from somewhere else.
If you cut and paste a data source inside one project, it will be just moved, no
password required. But the password is required in all the other cases.
A Cut can be undone with Ctrl/Cmd+Z.
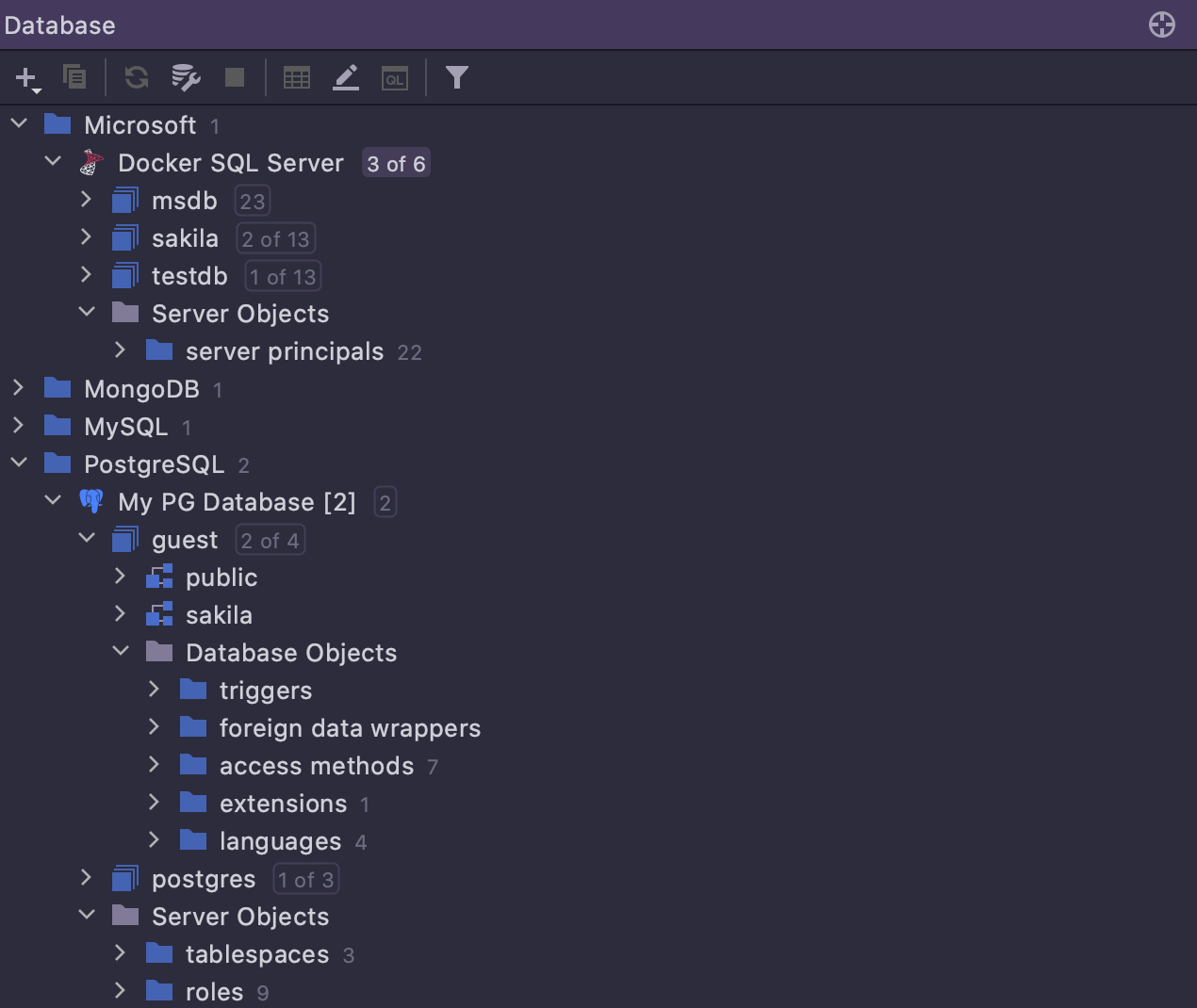 New layout
The default layout of the database explorer has been changed, with non-major objects now
available under a dedicated node. Most of the time people work with tables, views, and
routines, whereas seeing users, roles, tablespaces, foreign data wrappers, and many
other types of objects is not high on their list of priorities. So, these secondary
objects are now hidden under two nodes: Server Objects and
Database Objects.
New layout
The default layout of the database explorer has been changed, with non-major objects now
available under a dedicated node. Most of the time people work with tables, views, and
routines, whereas seeing users, roles, tablespaces, foreign data wrappers, and many
other types of objects is not high on their list of priorities. So, these secondary
objects are now hidden under two nodes: Server Objects and
Database Objects.
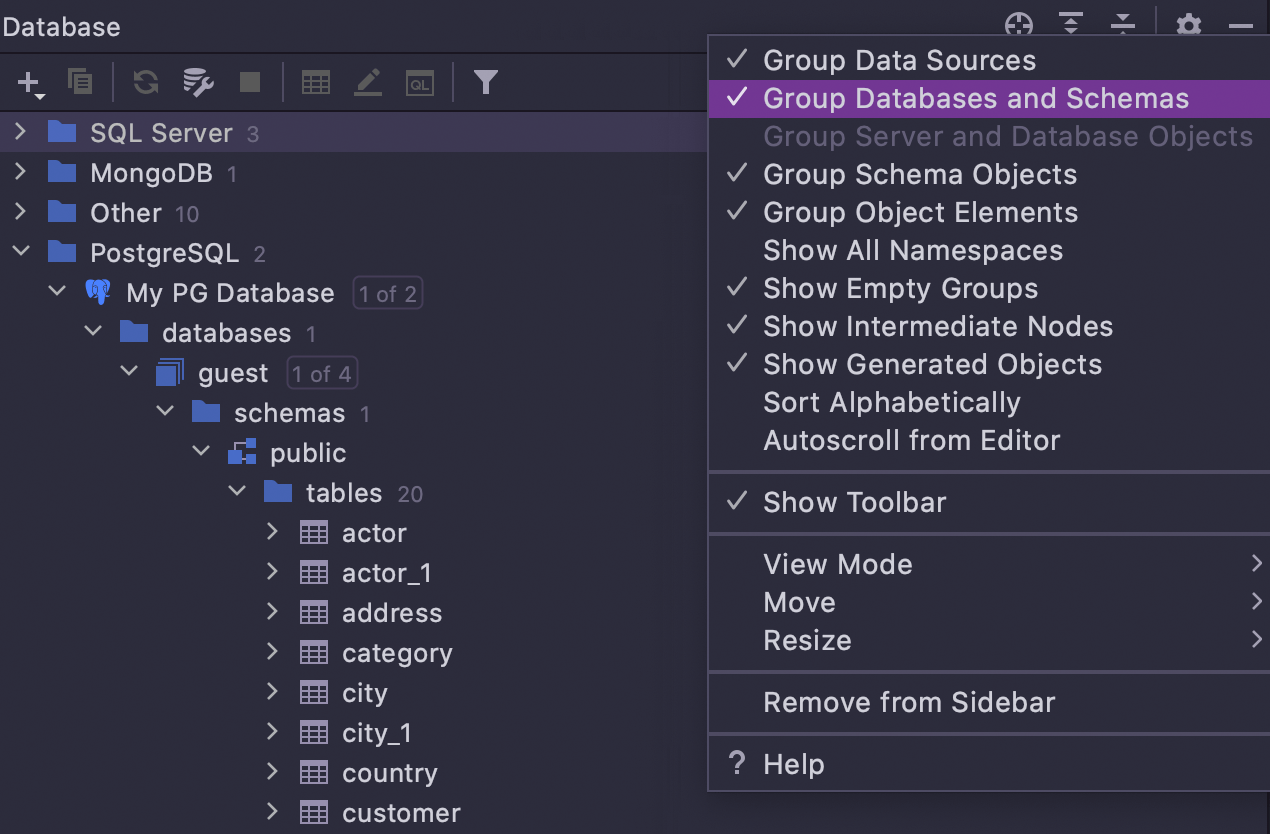 If you want the old layout back, just select Group Database and Schemas in
settings under the gear icon.
If you want the old layout back, just select Group Database and Schemas in
settings under the gear icon.
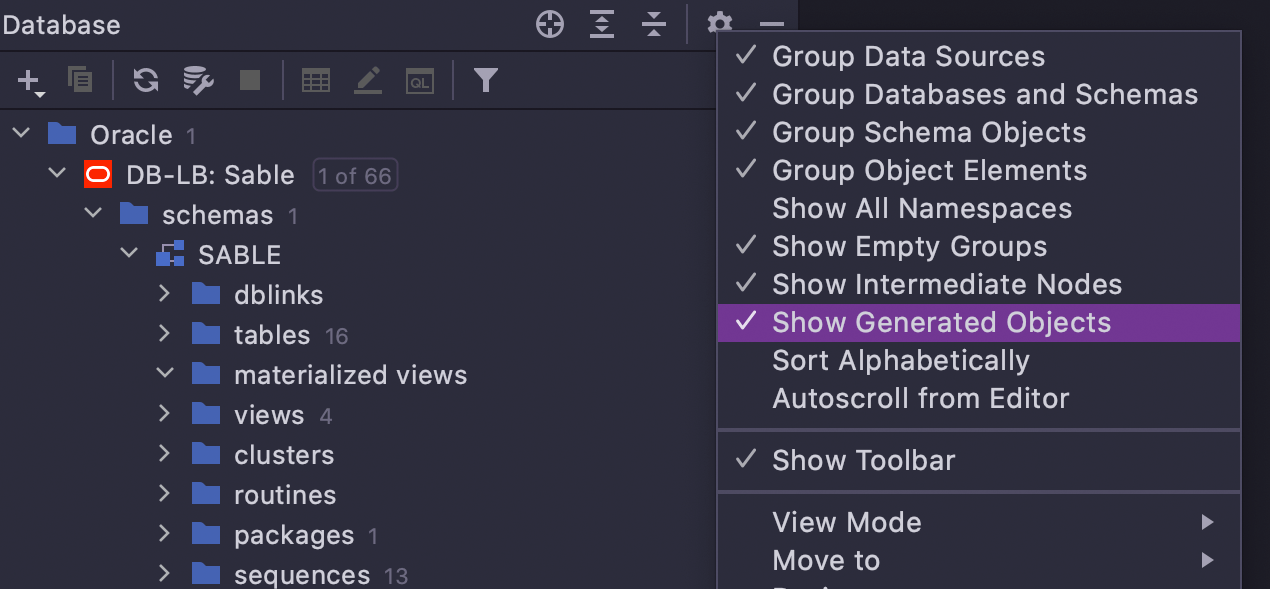 Hide auto-generated objects Oracle
If you use Oracle, there is an option to show or hide auto-generated objects in the tree, including the following:
Materialized view logs
The underlying tables for materialized views
Secondary tables
Hide auto-generated objects Oracle
If you use Oracle, there is an option to show or hide auto-generated objects in the tree, including the following:
Materialized view logs
The underlying tables for materialized views
Secondary tables
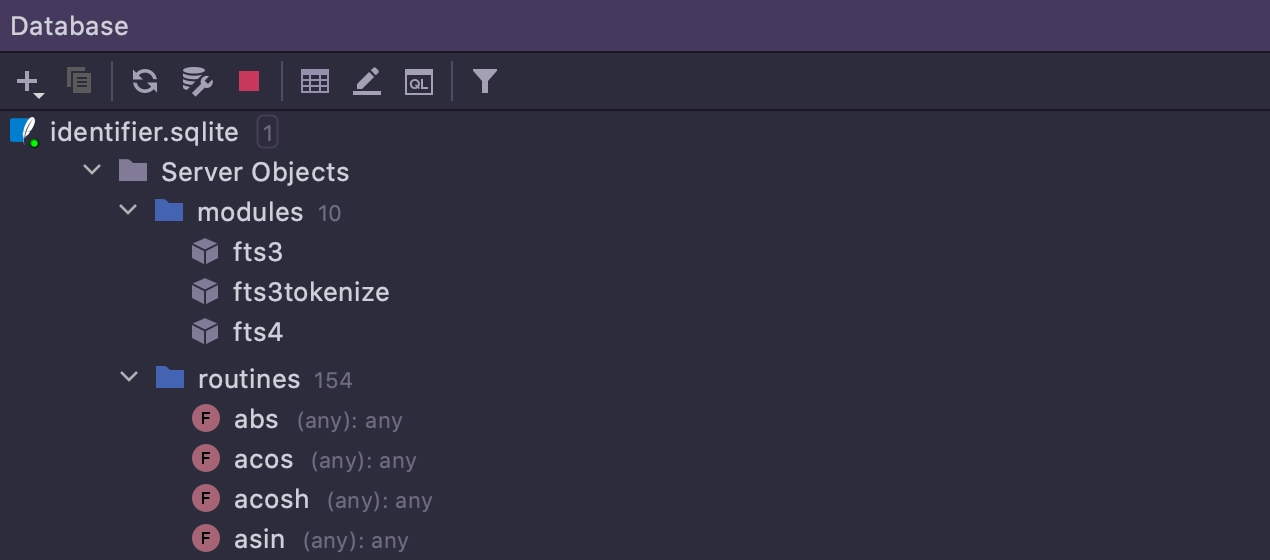 New types of objects SQLite
Functions, modules, and virtual columns are introspected for SQLite.
Improvements for unsupported databases
Data source templates
Starting with 2021.1, it’s easier to add the data source for databases we don't
support. We now provide JDBC drivers for AWS Athena, Informix, Presto, SAP HANA,
Google Cloud Spanner and many others. Look for these databases in the Other
section of the database list.
We’ve made some additional improvements:
You no longer need to download the driver yourself and manually create a data source
based on it.
New versions of the driver will be provided by DataGrip.
Some new databases have their own dedicated icons.
Please note that support for these databases is limited. It is mainly dependent on the
abilities of the JDBC driver and the SQL:2016 dialect support of DataGrip's SQL editor.
Queries parsing
We’ve introduced a new setting for using unsupported databases. When working with these
databases in DataGrip, you’ll need to use either the SQL:2016 or Generic
dialect. Generic is almost identical to SQL:2016, with just one
difference: DataGrip does not highlight any errors it finds.
To access the setting, go to Settings/Preferences | Database | General | Split a
script for execution in Generic and ANSI SQL dialects. The following values are
available to choose from:
On valid ANSI SQL statements or by separator – this is the default setting that
is suitable for the majority of cases. In other words, we’ll do our best to understand
what you want to run.
On ANSI SQL Statements – split statements as before. The logic is based only on
what DataGrip considers valid based on SQL:2016 grammar.
By statement separator – extract and run statements by separators. Use it if the
first option didn’t do the job. For GenericSQL, the separator is a semicolon.
Please note it is no longer possible to set a custom separator.
Here are some of the problems we’ve resolved:
Many users have reported a
problem with running CTEs. This should have
been partially mitigated when Generic grammar was upgraded from SQL:92 to SQL:2016,
but the On valid ANSI SQL statements or by separator option still helps with
complex CTEs. Another
example of a statement that will work with
this option is the unusual MERGE statement.
The On valid ANSI SQL statements or by separator option also helps run things
that aren’t statements at all in SQL:2016 grammar, such as show databases.
Coding assistance
New types of objects SQLite
Functions, modules, and virtual columns are introspected for SQLite.
Improvements for unsupported databases
Data source templates
Starting with 2021.1, it’s easier to add the data source for databases we don't
support. We now provide JDBC drivers for AWS Athena, Informix, Presto, SAP HANA,
Google Cloud Spanner and many others. Look for these databases in the Other
section of the database list.
We’ve made some additional improvements:
You no longer need to download the driver yourself and manually create a data source
based on it.
New versions of the driver will be provided by DataGrip.
Some new databases have their own dedicated icons.
Please note that support for these databases is limited. It is mainly dependent on the
abilities of the JDBC driver and the SQL:2016 dialect support of DataGrip's SQL editor.
Queries parsing
We’ve introduced a new setting for using unsupported databases. When working with these
databases in DataGrip, you’ll need to use either the SQL:2016 or Generic
dialect. Generic is almost identical to SQL:2016, with just one
difference: DataGrip does not highlight any errors it finds.
To access the setting, go to Settings/Preferences | Database | General | Split a
script for execution in Generic and ANSI SQL dialects. The following values are
available to choose from:
On valid ANSI SQL statements or by separator – this is the default setting that
is suitable for the majority of cases. In other words, we’ll do our best to understand
what you want to run.
On ANSI SQL Statements – split statements as before. The logic is based only on
what DataGrip considers valid based on SQL:2016 grammar.
By statement separator – extract and run statements by separators. Use it if the
first option didn’t do the job. For GenericSQL, the separator is a semicolon.
Please note it is no longer possible to set a custom separator.
Here are some of the problems we’ve resolved:
Many users have reported a
problem with running CTEs. This should have
been partially mitigated when Generic grammar was upgraded from SQL:92 to SQL:2016,
but the On valid ANSI SQL statements or by separator option still helps with
complex CTEs. Another
example of a statement that will work with
this option is the unusual MERGE statement.
The On valid ANSI SQL statements or by separator option also helps run things
that aren’t statements at all in SQL:2016 grammar, such as show databases.
Coding assistance
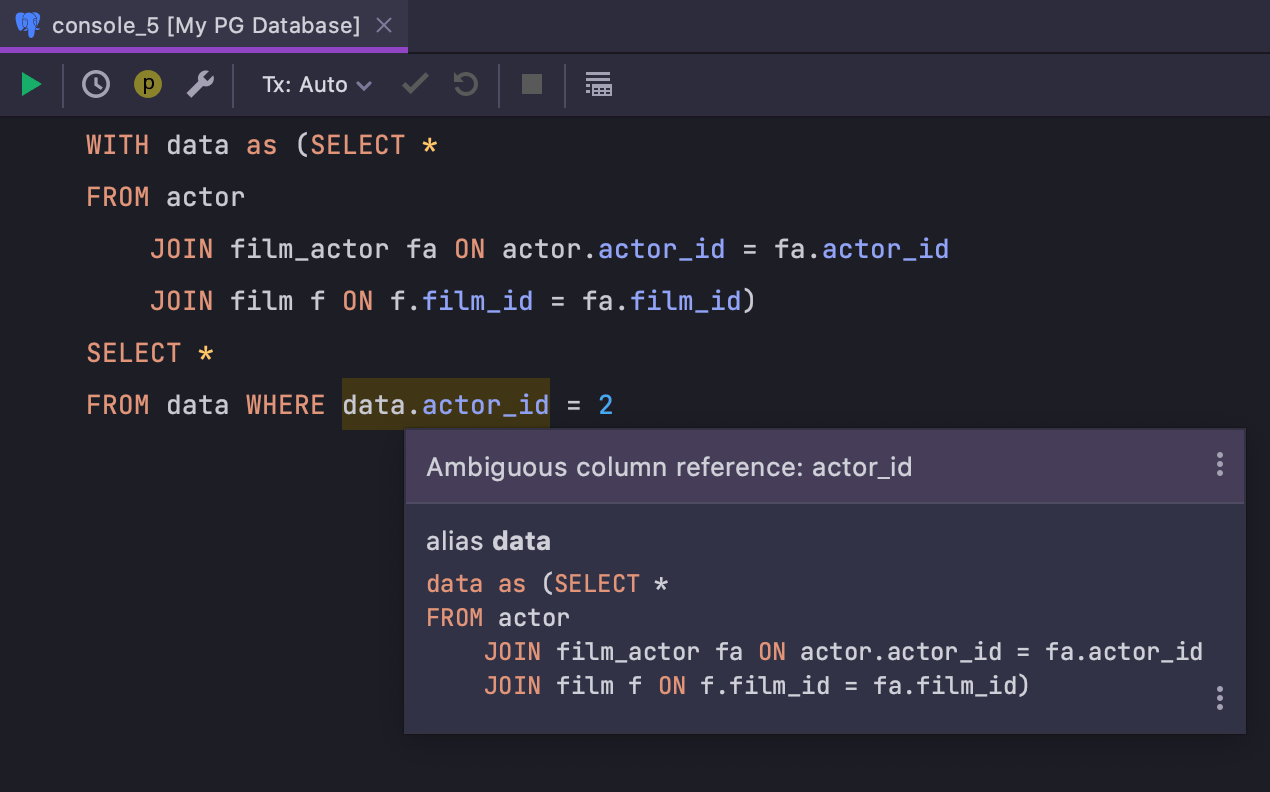 Ambiguous column name when using CTE
The inspection that reports ambiguous column names has become smarter and now takes into
account any columns inside common table expressions:
Ambiguous column name when using CTE
The inspection that reports ambiguous column names has become smarter and now takes into
account any columns inside common table expressions:
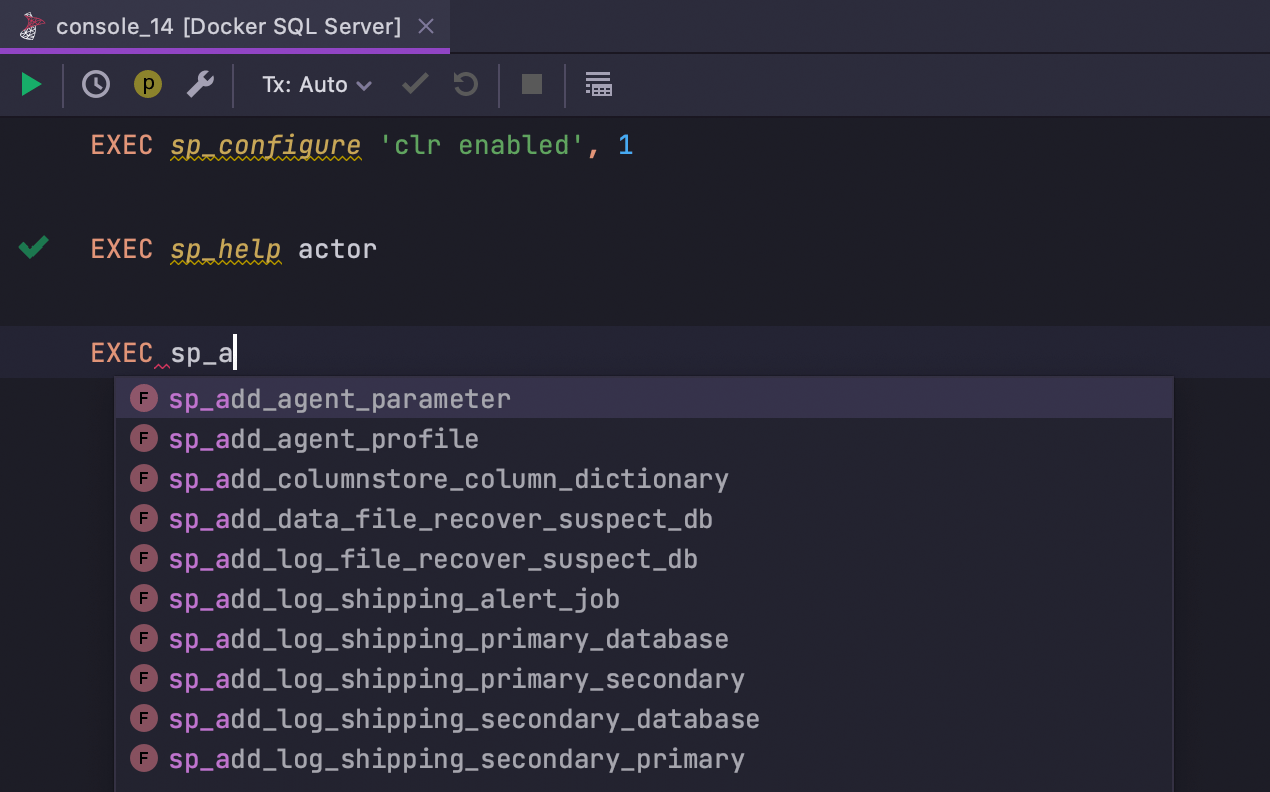 System functions can be used unqualified
SQL Server
System functions and procedures are no longer highlighted as errors when used
unqualified. Navigation and completion now work for them, as well.
System functions can be used unqualified
SQL Server
System functions and procedures are no longer highlighted as errors when used
unqualified. Navigation and completion now work for them, as well.
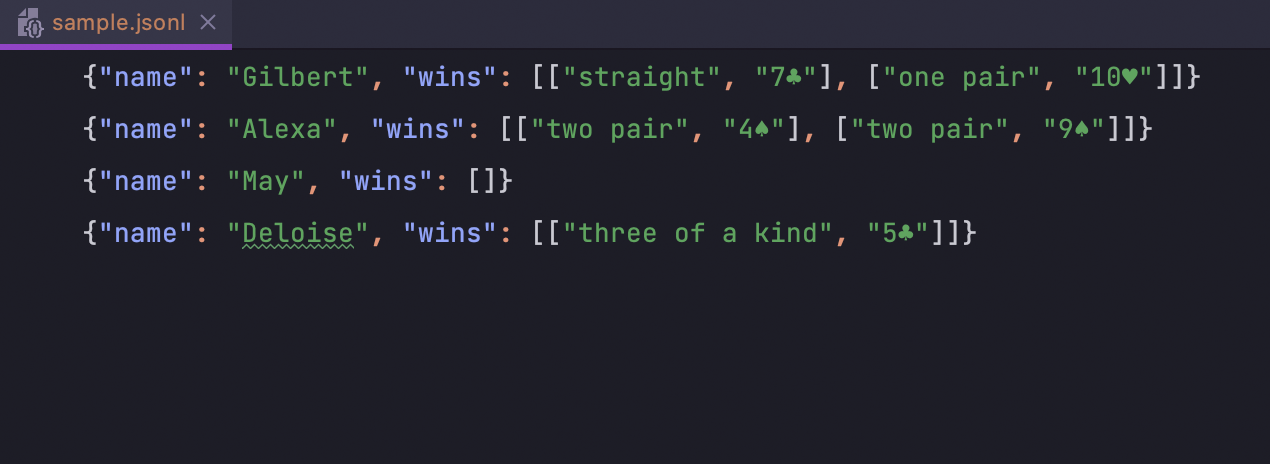 JSON Lines support
Thanks to the IntelliJ Platform, DataGrip now has support for the newline-delimited
JSON Lines format used for working with structured data
and logs. The IDE will recognize .jsonl, .jslines, .ldjson, and
.ndjson file types.
JSON Lines support
Thanks to the IntelliJ Platform, DataGrip now has support for the newline-delimited
JSON Lines format used for working with structured data
and logs. The IDE will recognize .jsonl, .jslines, .ldjson, and
.ndjson file types.
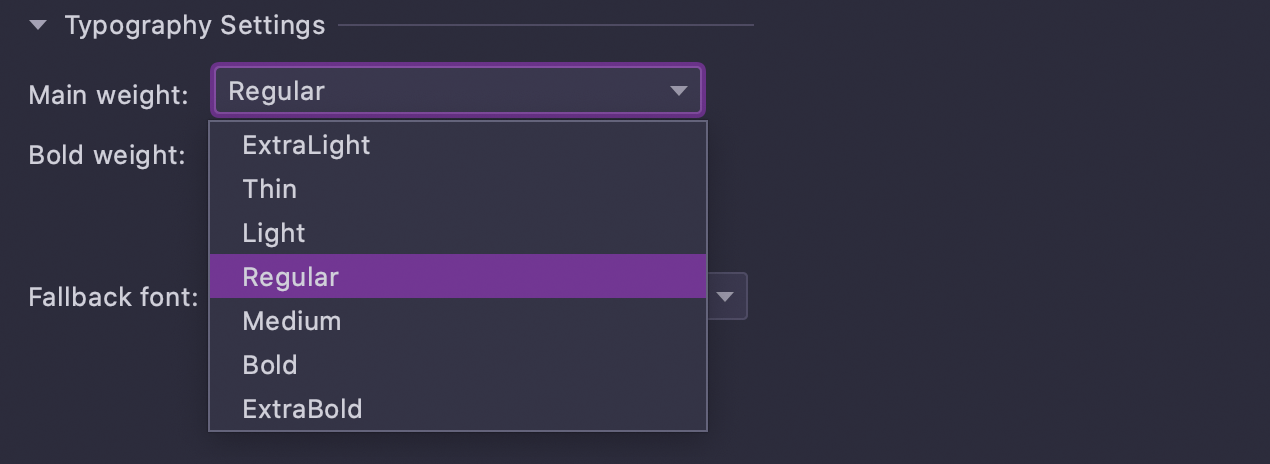 Adjustable font weight
The new typography settings help you fine-tune your font style. In v2021.1, you can
choose the weight of your main and bold font styles in
Settings/Preferences | Editor | Fonts.
Import / Export
Warning about not loaded data
When you copy binary data that hasn’t been completely loaded yet, the following
notification will be shown:
Adjustable font weight
The new typography settings help you fine-tune your font style. In v2021.1, you can
choose the weight of your main and bold font styles in
Settings/Preferences | Editor | Fonts.
Import / Export
Warning about not loaded data
When you copy binary data that hasn’t been completely loaded yet, the following
notification will be shown:
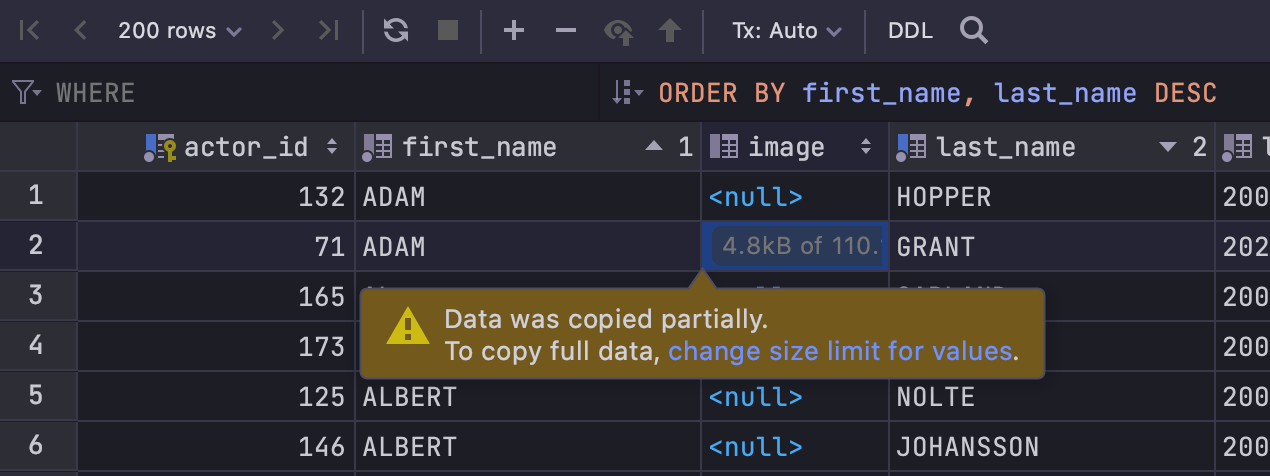 If you don’t want the data to be truncated, increase the value in
Settings/Preferences | Database | Data Views | Maximum number of bytes loaded per
value.
If you don’t want the data to be truncated, increase the value in
Settings/Preferences | Database | Data Views | Maximum number of bytes loaded per
value.
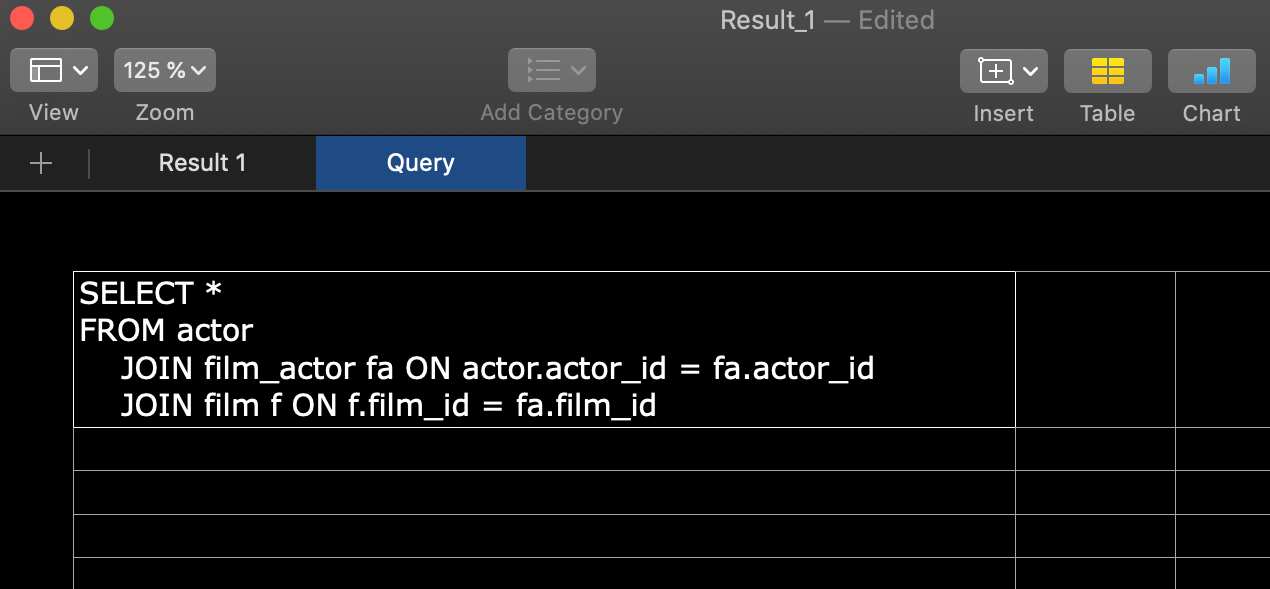 Query in the Excel file
When you export to Excel, the resulting file will contain the query on a separate sheet.
Query in the Excel file
When you export to Excel, the resulting file will contain the query on a separate sheet.
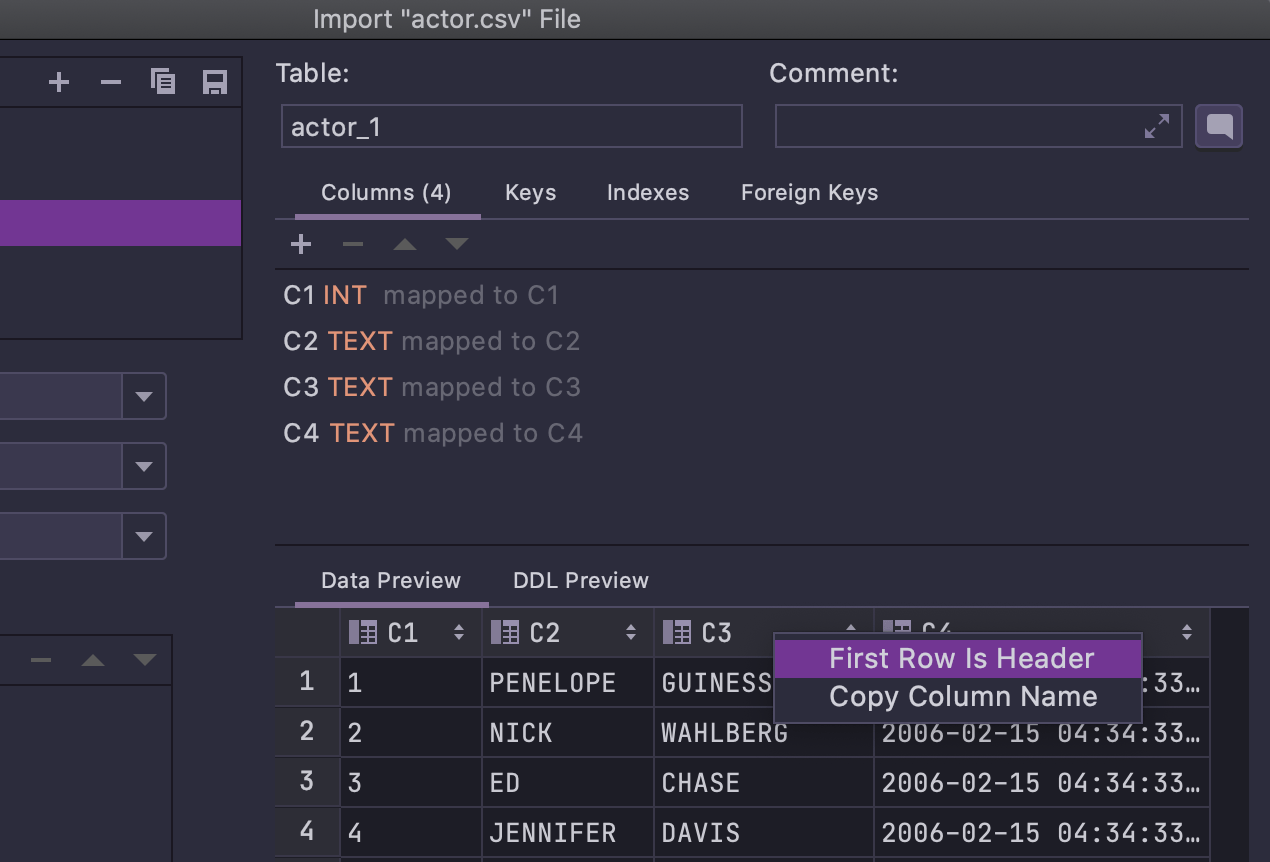 First row is header in the context menu
When you import a CSV file, the option to clarify that the first row is a header is now
available in the context menu as shown below:
User interface
First row is header in the context menu
When you import a CSV file, the option to clarify that the first row is a header is now
available in the context menu as shown below:
User interface
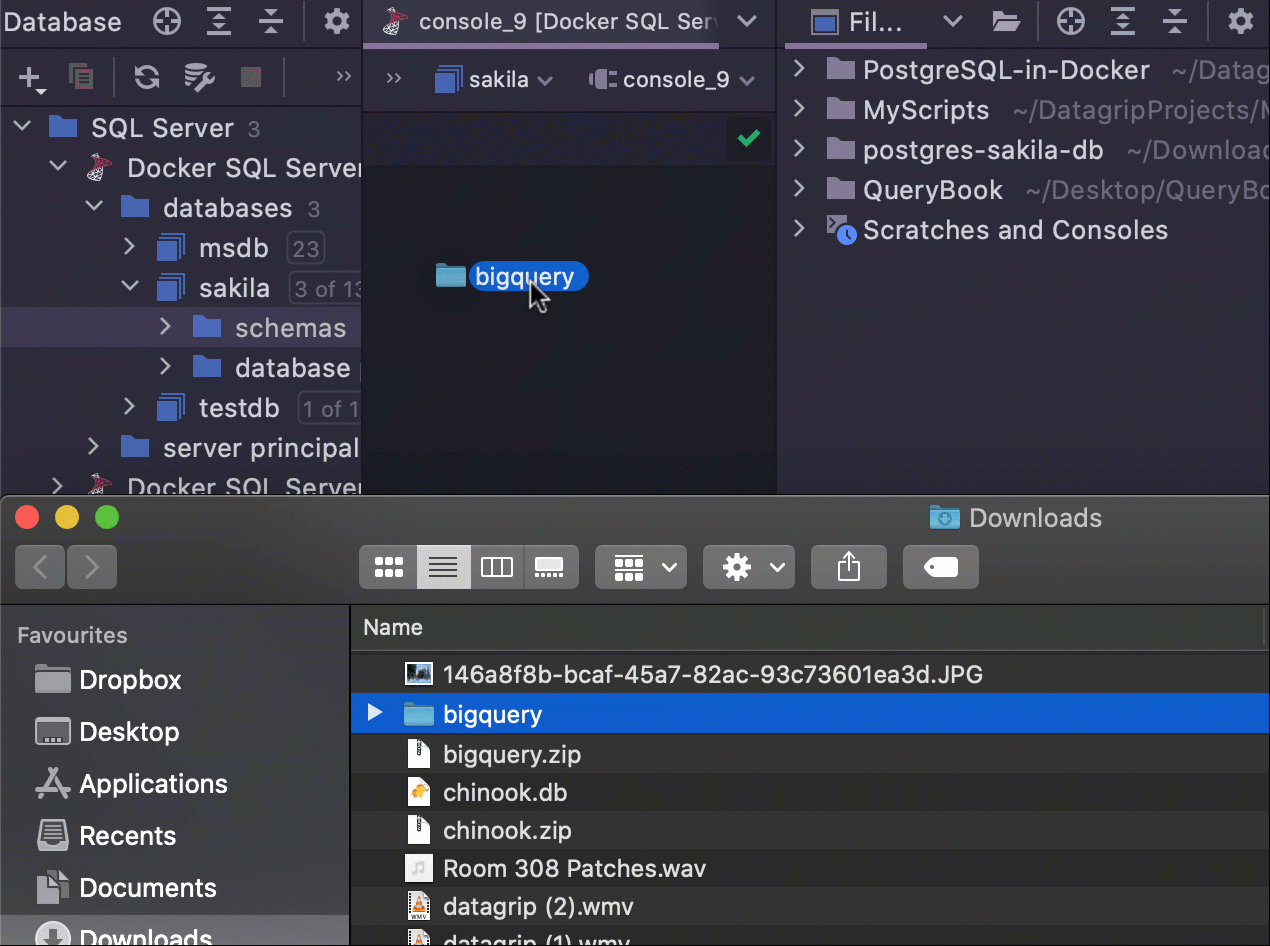 Attach folder via drag-n-drop
It's now possible to attach a folder to your project by dragging-and-dropping it.
Attach folder via drag-n-drop
It's now possible to attach a folder to your project by dragging-and-dropping it.
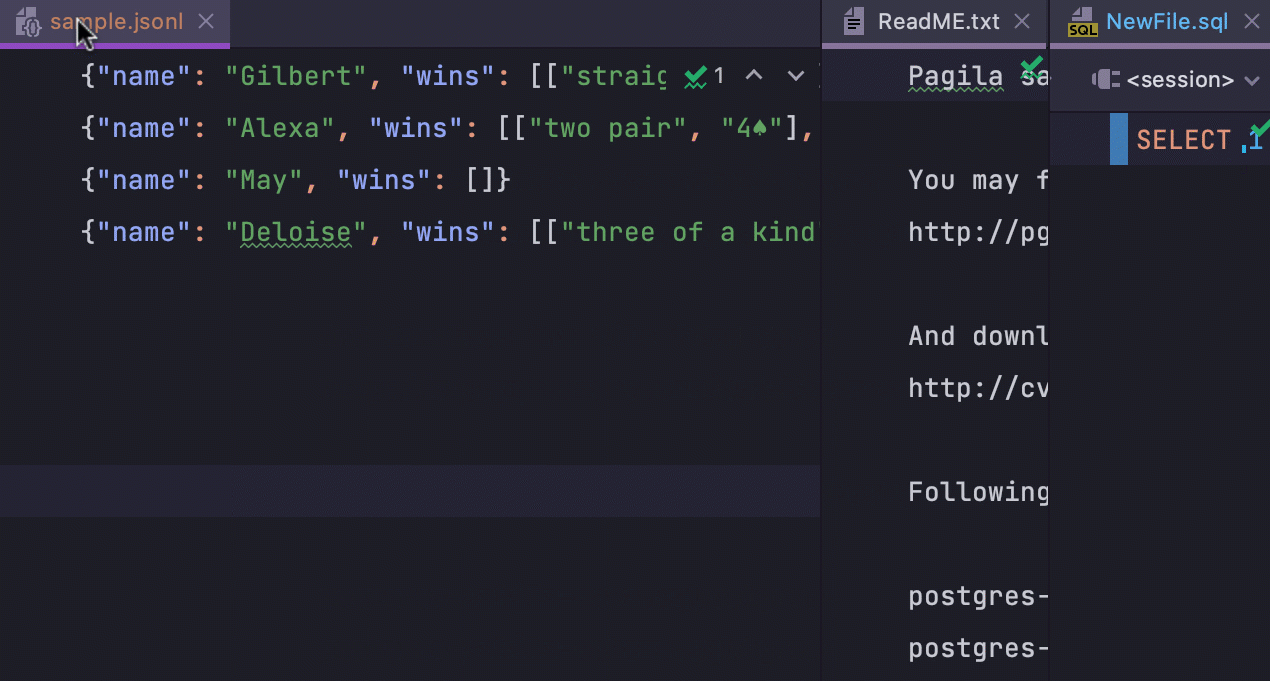 Maximize tabs in the split view
Whenever several tabs that
split the editor vertically are open, you can
double click them and maximize the editor window for each one. To bring the window back
to its original size, simply double-click it again.
Maximize tabs in the split view
Whenever several tabs that
split the editor vertically are open, you can
double click them and maximize the editor window for each one. To bring the window back
to its original size, simply double-click it again.
 Long names in tabs titles
Some time ago we introduced shortened tab names. Not everyone liked it, so here's a
setting to give you more choice.
Long names in tabs titles
Some time ago we introduced shortened tab names. Not everyone liked it, so here's a
setting to give you more choice.
